Zebra命令模式分析(一) - 分析
文章来源:http://blog.csdn.net/qy532846454/article/details/5200531
==================================================================================================
zebra分析版本:Zebra-0.95a
命令存储结构
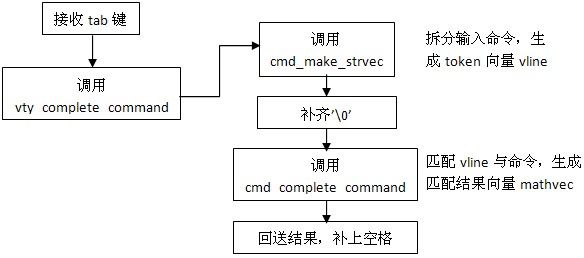
对于上图中略去的cmd_elemnt,它代表了一条命令,具体展开如下:
每条命令按上图存储,命令被分拆为tokens,存储在vector中
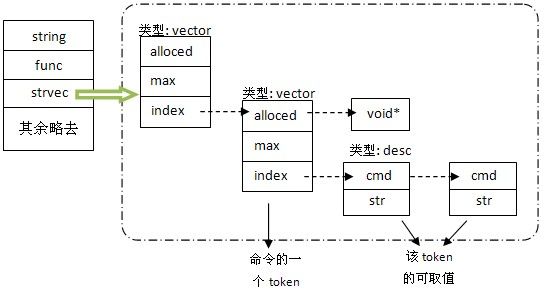
如此,形成了zebra命令模式的基本框架:所有命令被分类到不同模式下。这里的模式即上面图中的
节点cmd_node,而命令则相当于cmd_element,可见,命令被放到了不同的node下。注意,上图中的虚
箭头并不代表链表,只是代表元素的先后顺序,实际上它们是以数组存储的。
Zebra中命令的总结点(或根结点)是cmdvec,它包含了所有的cmd_node,而cmd_node包含了所有
的cmd_element。
初始化时首先加载所有的命令,形成上图中的整体层次结构,然后对每个cmd_node下的命令执
行qsort,按命令的字符序重排,主要是为了查找加速。
命令分析
命令的执行只要查找cmdvec就可以了,下面着重于zebra命令的tab自动补齐,及打印所有可用命令
接收tab键,自动补齐命令,执行函数: vty_complete_command()

Zebra的调用结构:
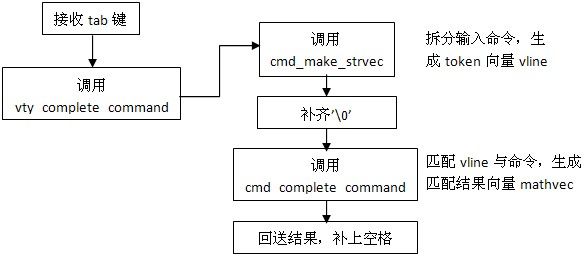
整个流程的主体是cmd_complete_command(),它调用了cmd_filter_by_completion()匹配已输入字符 串,返回匹配结果,结果分为 了10种
| no_match |
extend_match |
Ipv4_prefix_match |
Ipv4_match |
Ipv6_prefix_match |
| Ipv6_match |
range_match |
vararg_match |
partly_match |
exact_match |
大部分是zebra支持的变量的匹配类型,partly_match表示只是部分匹配,exact_match表示一个
token的完全匹配,no_match表示不 匹配,这三个状态是我们所关心的。
例子: 输入’configure’,输入tab补齐,返回’configure(空格)’
输入’configure(空格)’,输入tab补齐,返回’configure(空格)terminal’
输入’c’,输入tab补齐,返回’co’
输入’terminal(空格)’,输入tab补齐,返回’terminal(空格)’ ‘length monitor no’
上面就是补齐的基本情况了(为了标注空格,上面的空格都以中文写出)
1. 对于输入的命令字符串分拆成token后存储为vector,程序中则是(以’configure ter’为例):
2. 假设vline有n个token,则对于vline的前n-1个token与每个命令的对应token比较,如果不是 exact_match,则返回
3. 对于vline的第n个token,匹配每个命令的第n个token前几位是否为’ter’,并记录下
![]()
所有匹配的token,生成匹配向量matchvec:
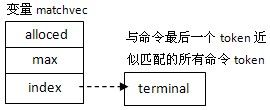
4. 结果回送给终端,在输出完匹配结果后,再输出一个空格,即上例的实际输出结果为:
‘configure terminal ’(注意:最后多了个空格)
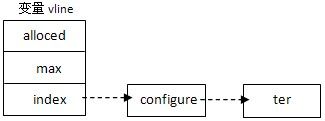
空格的作用:补上空格的意义在于,如果检测输入命令的最后一个字符是空格,则在命令向
![]()
量vline最后补上’/0’,如输入’configure ’,则生成vline如下图:
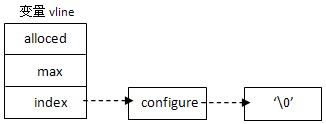
在匹配vline的第二个token时,由于是空字符,所以它与所有的字符都相匹配,达到自动补齐下 一个可选token的作用
接收?,显示所有命令,执行函数: vty_describe_command()
