面试收集--关于链表的一些面试题
链表相关的面试题是经常出现的,今天总结一下~
1.如何判断一个链表是否有环?如果有,找到环的入口?
设置快慢指针,快指针步长为2,慢指针步长为1,如果有环,最终快慢指针会相遇,代码如下:
bool hasCircle(Node* head, Node* &encounter){Node *fast = head, *slow = head;while(fast && fast->next){fast = fast->next->next;slow = slow->next;if(fast == low){encounter = fast;return true;}}// fast == NULL || fast->next == NULLencounter = NULL;return false;}
至于如何确定环入口,请看下图

设入口点距链表头部head有x步,由于必然相遇,设相遇点距入口点有y步,环长度为r(表示环中有r+1个节点),那么有判断相遇的算法可知
(x+y)*2=nr+(x+y) => nr=x+y =>(n-1)r+r-y=x
由上面的分析可知,设置两个指针,一个初始为head,另一个初始为encounter,同步前进,一旦相遇就是入口,于是有了下面的代码:
Node* findEntry(Node* head, Node* encounter){Node *p1 = head, *p2 = encounter;while(p1 != p2){p1 = p1->next;p2 = p2->next;}return p1;}来源:http://hi.baidu.com/iwitggwg/item/7ad684119a27fefc9c778a5c
2. 假设有两个单链表,给出头指针 head1 和 head 2,判断两个链表是否有交点?
先判断是否有环,不过题目一般会给定无环条件。如果没有给出,可以判断,判断算法如下:
如果无环,遍历两个链表,得到两个链表的长度m和n,先遍历较长链表|m-n|次,接着同步遍历两个链表,一旦相同,则找到相同节点,否则返回null。
3. 只给定单链表中某个结点p(并非最后一个结点,即p->next!=NULL)指针,删除该结点。
这个题目有个trick,正常的思路是利用p前面一个节点才能删掉p,但是现在只有p的地址,得不到p前面的地址,那么只能删除p后面的节点,删除之前把p->next的内容复制到p中,注意这个算法删除不了最后一个元素。
4.只给定单链表中某个结点p,在p前面插入一个结点?
思路同3,先在p后面插入一个节点,然后将p的数据复制到p->next中,在将插入的结点的数据复制到p中
5.给定单链表的头结点head,删除链表中倒数第k个结点
同样是快慢指针问题,设置快指针p_fast,慢指针p_slow,初始均指向head,快指针先走k步,走完k步之后快慢指针同步走,每次走一步,直至快指针走到队尾。这里没有考虑有环的状况,有环这个题目就无法解了, 如果严谨的话要先判断是否有环。下面是一个不太严谨的算法。
Node *(Node *head,int k){assert(head!=NULL);Node *p_fast=head;Node *p_slow=head;int count=k;while(count>0&&p_fast!=NULL){p_fast=p_fast->next;count--;}if(count>0)return NULL;while(p_fast!=NULL){p_fast=p_fast->next;p_slow=p_slow->next;}return p_slow;}
6.找出链表的中间元素(无环)
同样是快慢指针的问题,快指针慢指针初始都指向head,快指针每次行进两步,慢指针一步,一旦快指针指向链表尾部,慢指针指向的就是中间元素。实际写代码要考虑一些奇偶情况。
7.链表的就地逆置
头插法,但是要注意一些特殊情况,代码如下:
Node* reverseList(Node* head){Node *p1, *p2 , *p3;//链表为空,或是单结点链表直接返回头结点if (head == NULL || head->next == NULL){return head;}p1 = head;p2 = head->next;while (p2 != NULL){p3 = p2->next;p2->next = p1;p1 = p2;p2 = p3;}head->next = NULL;head = p1;return head;}
8.复杂链表的复制
这个是程序员面试精选的第49题,思路很巧妙,题目意思见链接,链表复杂就复杂在于除了有一个m_pNext指针指向下一个结点外,还有一个m_pSibling指向链表中的任一结点或者NULL。其结点的C++定义如下:
struct ComplexNode{int m_nValue;ComplexNode* m_pNext;ComplexNode* m_pSibling;};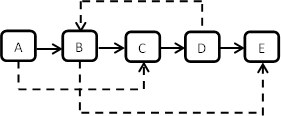 解法一旦知晓就没什么神秘的了,答案参看链接。
解法一旦知晓就没什么神秘的了,答案参看链接。
9.已知两个链表head1 和head2 各自有序,请把它们合并成一个链表依然有序,保留所有结点,即便大小相同,递归实现,假设都是升序排列。
Node * merge(Node * head1,Node *head2){Node *ret=NULL;if(head1==NULL)return head2;if(head2==NULL)return head1;if(head1->val<head2->val){ret=head1;ret->next=merge(head1->next,head2);}else{ret=head2;ret->next=merge(head1,head2->next);}return ret;}
10.从一个未排序的链表中删除重复的元素,给出一种算法,如果要求不适用额外的空间呢?
如果能用hash表的话,只需要遍历一次链表,如果发现元素不在hash表中,就插入hash表,反之则删除。
如果不用额外的空间的话,有个O(N2)的算法:
LinkList RemoveDupNode(LinkList L)//删除重复结点的算法{LinkList p,q,r;p=L->next;while(p) // p用于遍历链表{q=p;while(q->next) // q遍历p后面的结点,并与p数值比较{if(q->next->data==p->data){r=q->next; // r保存需要删掉的结点q->next=r->next; // 需要删掉的结点的前后结点相接free(r);}elseq=q->next;}p=p->next;}return L;}