本地搭建deepseek并提供给其它人使用(最全,完整可用)
最近deepseek非常火,可以称得上是国人的骄傲了。也导致他的网站和api都比较卡。因为是开源的,我们可以很方便的架设其蒸馏模型到自己的主机上。
PS:虽然也可以Cpu运行模型,但是如果没有8G以上的显存卡的话,只能搭建7B以下的模型,体验效果并不太好。
一、安装 Ollama
1.1 在线安装(推荐方式,需要科学上网)
在 Ubuntu 终端中直接执行下面的命令,下载安装脚本会自动下载适合你系统架构的 Ollama 二进制文件并安装到系统中:
curl -fsSL https://ollama.com/install.sh | sh
安装过程中需要 sudo 权限,并会自动创建系统用户、配置 systemd 服务等 。
安装完成后,你可以通过下面的命令检查版本:
ollama -v
若显示版本号(例如 0.5.7),则说明安装成功。
1.2 手动安装
如果你遇到网络或其他问题,也可以选择手动安装:
下载适合你的系统架构的二进制文件(例如,对于 x86_64 架构):
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama
PS:如果下载太慢,可直接下我的资源
赋予可执行权限:
sudo chmod +x /usr/bin/ollama
二、配置 Ollama 以支持局域网访问
默认情况下,Ollama 服务可能只绑定在 localhost 上。要使局域网内的其他机器也能访问,需要修改其监听地址。
2.1 修改 systemd 服务文件
编辑 /etc/systemd/system/ollama.service(如果是在线安装方式,该文件一般会自动生成),修改或添加以下内容:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=root
Group=root
Restart=always
RestartSec=3
Environment="OLLAMA_MODELS=/path/to/ollama_models" # 模型存放路径
Environment="OLLAMA_HOST=0.0.0.0:11434" # 监听所有IP,端口11434
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
[Install]
WantedBy=default.target
注意:
- 修改
User和Group为你实际使用的 Linux 用户。 - 确保
OLLAMA_MODELS指向你希望存储模型数据的目录。 ExecStart的位置也有可能是/usr/bin/ollama serve
2.2 安装nvidia GPU驱动
如果没有安装GPU驱动,Ollama默认会使用CPU运行,速度很慢。
安装参考我的另一篇文章:ubuntu安装深度学习环境
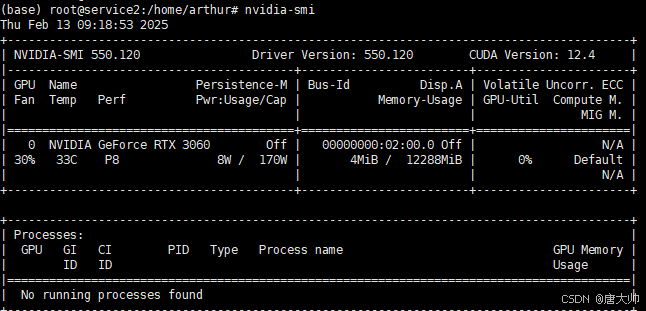
运行:nvidia-smi 显示如下即可
2.3 重载并重启服务
执行:
sudo systemctl daemon-reload
sudo systemctl restart ollama.service
sudo systemctl status ollama.service
如果显示如下,就说明已经安装Ollma成功了
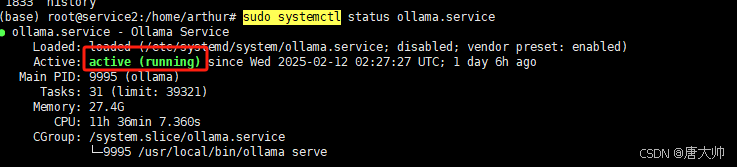
这样 Ollama 就会监听在 0.0.0.0:11434 上,局域网内其他机器可以通过 http:// 访问其 API
PS:如果配置失败,使用journalctl -e -u ollama 查看错误日志
三、部署 DeepSeek 模型
DeepSeek 模型在 Ollama 的模型库中已经发布(例如 DeepSeek-R1 系列)。你可以根据自己的硬件配置选择合适的参数版本(例如 1.5b、7b、14b 等)。
3.1 选择并运行模型
在终端中运行以下命令(以 1.5b 版本为例):
ollama run deepseek-r1:1.5b
这条命令会自动拉取模型数据并启动模型。下载和初始化过程可能需要一些时间,完成后你可以在命令行中与模型进行交互测试 。
PS:如果没有科学上网,可能会比较慢,可以直接下载我的模型文件使用。下载地址
根据实际需求,如果你的硬件条件允许,也可以尝试部署更高参数的版本,比如 7b(70亿参数)等。
3.2 配置需求
DeepSeek 蒸馏模型硬件要求
| 模型版本 | CPU要求 | 内存要求 | 硬盘要求 | 显卡要求 | 适用场景 |
|---|---|---|---|---|---|
| DeepSeek-R1-1.5B | 4 核(推荐多核处理器) | 8GB+ | 3GB+ | 非必需(CPU推理);GPU可选 4GB 显存 | 低资源设备部署,如树莓派、旧款笔记本、物联网设备等 |
| DeepSeek-R1-7B | 8 核以上(推荐现代多核 CPU) | 16GB+ | 8GB+ | 推荐 8GB 显存(如 RTX 3070/4060) | 中小型企业本地开发测试,轻量级多轮对话系统 |
| DeepSeek-R1-8B | 8 核以上(推荐现代多核 CPU) | 16GB+ | 8GB+ | 推荐 8GB 显存(如 RTX 3070/4060) | 轻量级任务,如代码生成、逻辑推理 |
| DeepSeek-R1-14B | 12 核以上 | 32GB+ | 15GB+ | 推荐 12GB 显存(如 RTX 4090/A5000) | 企业级复杂任务、长文本理解与生成 |
| DeepSeek-R1-32B | 16 核以上(如 AMD Ryzen 9/i9) | 64GB+ | 30GB+ | 24GB 显存(如 A100 40GB) | 高精度专业领域任务、多模态任务预处理 |
| DeepSeek-R1-70B | 32 核以上(服务器级 CPU) | 128GB+ | 70GB+ | 多卡并行(如 2x A100 80GB) | 科研机构/大型企业、高复杂度生成任务 |
| DeepSeek-R1-671B | 64 核以上(服务器集群) | 512GB+ | 300GB+ | 多节点分布式训练(8x A100/H100) | 超大规模 AI 研究、通用人工智能(AGI)探索 |
四、提供 Web 交互界面(可选)
如果你希望通过浏览器进行更友好、直观的交互,可以部署 Open-WebUI。它基于 Docker 部署,能够将 Ollama 后端的模型通过一个网页界面展示出来。
直接安装open-webui
- Create a Conda Environment:
conda create -n open-webui python=3.11
- Activate the Environment:
conda activate open-webui
- Install Open WebUI:
pip install open-webui
- Start the Server:
open-webui serve
或者后台运行
nohup open-webui serve > /dev/null 2>error.log &
启动成功后,你可以让局域网内其他机器通过访问 http://<机器局域网IP>:8080(默认端口为 8080)来使用 Web 界面 (需要防火墙开放8080端口)
4.1 通过Docker安装open-webui
可参考官方安装指南:
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
使用以下 Docker 命令启动 Open-WebUI,并指定 Ollama 的 API 地址(注意使用 host 网络模式保证能访问本机服务):
sudo docker run -d --network=host -e OLLAMA_BASE_URL=http://127.0.0.1:11434 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
启动成功后,你可以让局域网内其他机器通过访问 http://<机器局域网IP>:3000(默认端口为 3000)来使用 Web 界面 (需要防火墙开放3000端口)
五、局域网访问验证
在 Ubuntu 主机上确认 Ollama 服务正常运行并监听在 0.0.0.0:11434:
sudo systemctl status ollama.service
在同一局域网内其他机器上,通过浏览器访问:
http://<Ubuntu_IP>:11434
或者如果部署了 Open-WebUI,则访问:
http://<Ubuntu_IP>:8080
这样就能直接与 DeepSeek 模型交互。
六、其它问题
open-webui登录后空白
open-webui上传文件报错