Browser-Use + LightRAG Agent:利用LLM抓取99%网站的高效方案

在这个故事中,我将提供一个快速教程,展示如何使用浏览器使用、LightRAG和本地LLM创建一个强大的聊天机器人,以开发一个能够抓取您选择的任何网站的AI代理。此外,您可以询问有关您的数据的问题,这将为您提供该问题的回答。
免责声明:本文仅用于教育目的。我们不鼓励任何人抓取网站,特别是那些可能有反对此类行为的条款和条件的网络属性。
现有的RAG系统存在显著的局限性,包括依赖扁平数据表示和缺乏上下文意识,导致答案碎片化以及无法捕捉复杂的相互依赖关系。
为了解决这些挑战,我们提出LightRAG和浏览器使用
浏览器使用是一个开源的网络自动化库,支持与任何语言模型(LLM)进行交互。
通过一个简单的接口,用户可以使LLM与网站交互并执行数据抓取和信息查询等任务。
LightRAG将图结构集成到文本索引和检索过程中。这个创新框架采用两级检索系统,以增强从低级和高级知识发现中全面信息检索的能力。
那么,让我给您快速演示一个实时聊天机器人,向您展示我的意思。
我想抓取一个网站,所以我问了代理两个问题。我的第一个问题是:“去亚马逊找出最便宜的16GB VRAM和RTX 3080或RTX 4090 GPU的笔记本电脑。”
结果令人惊讶!浏览器使用大型语言模型提取数据,自动定位交互元素。如果您仔细观察,您会看到代理在找不到元素或LLM出错时会自我纠正。它还使用视觉模型进行截图并提取信息。
对于我的第二个问题,我问代理:“去google.com寻找关于监督LLM的文章,然后提取关于监督微调的所有内容。”如果您想了解更多关于微调的信息,我在我上一个视频中进行了详细解释和研究。
一旦数据加载完成,我们实现LightRAG,以便LLM能够同时处理多个元素——实体、关系和描述。它测试了LLM的理解,分拆任务可以减少压力,但可能会增加令牌使用。
模型的源代码提前指定了实体类型,这可能不适用于新领域,类似于在传统知识图谱中定义模式的挑战。
在更高的层面上,关键词指导相关信息的回忆,但回忆质量取决于这些关键词。最终,这个过程提高了最终答案的质量。
什么是 LightRAG?
LightRAG 是一个快速高效的信息检索和生成系统,旨在解决传统 RAG 系统的问题。一个典型的 RAG 系统旨在将 LLM 与外部知识链接,以生成更准确的用户问题答案。
然而,传统系统受限于扁平的数据表示,缺乏上下文。LightRAG 将图结构纳入数据索引和搜索,以克服这些限制,并提供高效且具有上下文的信息。
LightRag 的工作原理
LightRAG 首先应用基于图的数据结构,在信息检索过程中对外部数据库中的实体及其关系进行预处理。
该过程包括多个步骤:
-
• 实体和关系的提取
-
• 检索键值对的生成
-
• 信息的去重
通过这些步骤,LightRAG 不仅提取具有特定语义的实体,还加深了对抽象概念的理解,使系统在面对复杂问题时能够进行更准确的信息检索和生成。
例如
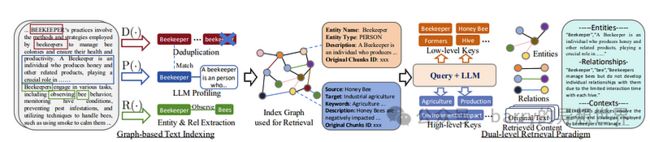
基于图的文本索引
LightRAG 从文档中提取实体(人、地点、概念等)及其之间的关系,并利用这些信息构建知识图谱。
例如,从句子“Andrew Yan 在 Google Brain 团队研究人工智能”中,我们提取以下信息:
-
• 实体:Andrew Yan(人),Google Brain 团队(组织),人工智能(概念)
-
• 关系:Andrew Yan — 研究 — 人工智能,Andrew Yan — 隶属 — Google Brain 团队
以这种方式创建的知识图谱可以有效地表示复杂的信息关系。图 1 的左侧对应于这个过程。
双阶段搜索范式
LightRAG 搜索分为两个阶段,低级和高级,如图 1 中间部分所示。
-
• 低级搜索:寻找具体的实体或关系,例如特定的名称或概念,如“Andrew Yan”或“The Google Brain team”。
-
• 高级搜索:寻找更抽象的主题或对象,例如广泛的主题,如“谷歌 AI 研究的前沿”。
这种双层次的方法允许平衡的信息检索,既捕捉具体事实,又展现更大的全局。
LightRAG 与 GraphRAG
LightRAG 在效率、检索和处理复杂查询方面优于 GraphRAG。它使用双层检索系统,将令牌使用量减少到 100 以下,仅需一次 API 调用,而 GraphRAG 则需要 610,000 个令牌和多次调用。
LightRAG 提供了更多样化的响应,有效捕捉特定和广泛的主题,并在复杂查询中表现出色,而 GraphRAG 的适应性较差,成本更高。LightRAG 更加高效、灵活,适合动态数据环境。

什么是 Browser-Use?
Browser-use 是一个开源的网页自动化库,允许大型语言模型(LLMs)执行诸如检查航班、搜索信息、总结热门帖子等任务。
它自动检测可点击元素,处理 Cookie 提示和弹出窗口,并允许在多个标签页之间切换。它还可以填写表单、提取网页信息、截取屏幕截图和读取图像内容。
该工具通过分析当前页面内容做出智能决策,以确定下一步行动——是点击、输入文本还是翻页。此外,它具有记忆功能,能够回忆之前访问的页面和收集的信息。它支持与 LangChain 兼容的模型,包括 GPT-4、Claude 3.5 和 LLama。
开始编码
在我们深入应用程序之前,我们将创建一个理想的环境以便代码能够正常工作。为此,我们需要安装所需的 Python 库。首先,我们将开始安装支持模型的库。为此,我们将执行 pip install requirements。由于演示使用了 OpenAI 大模型,因此您必须首先设置 OpenAI API 密钥。
pip install -r requirements.txt
安装完成后,我们导入 browser_use、langchain_openai 和 lightrag。
from browser_use import Agent, Controller from dotenv import load_dotenv from langchain_openai import ChatOpenAI import os from lightrag.lightrag import LightRAG, QueryParam from lightrag.llm import gpt_4o_mini_complete
然后,我们使用 Controller 来管理和保持多个代理之间的浏览器状态。它允许代理共享浏览会话,保持 Cookie、会话和标签页的一致性。
## 在代理之间保持浏览器状态 controller = Controller()
我们将初始化代理,以通过在 Google 中搜索 “LoRA LLM” 来查找和提取信息。然后,我们使用 chatOpenai 模型来处理和分析与 controller 连接的内容,以保持浏览器状态。
## 初始化浏览器代理 agent = Agent( task="Go to google.com and find the article about Lora llm and extract everything about Lora", llm=ChatOpenAI(model="gpt-4o", timeout=25, stop=None), controller=controller)
此外,我们可以初始化另一个代理,但这不是必需的,具体取决于您希望在代码中包含多少代理。它们可以执行不同的任务,但您需要将每个代理管理到不同的任务中。
agent = Agent( task="Go to google.com and find the article Supervised llm and extract everything about Supervised Fine-Tuning", llm=ChatOpenAI(model="gpt-4o", timeout=25, stop=None), controller=controller)
然后,我们定义一个异步函数以实现任务的并发执行,我们将代理的最大步骤限制设置为 20,但可以根据需要设置任何数字。在每一步中,代理执行一个动作,表示代理计划下一步要做的事情,结果包含该步骤的输出,包括任务是否完成和任何提取的数据。如果任务完成,提取的内容将保存到名为 text.txt 的文件中,过程终止。
async defmain(): max_steps = 20 # 逐步运行代理 for i inrange(max_steps): print(f'\n 步骤 {i+1}') action, result = await agent1.step() print('动作:', action) print('结果:', result) if result.done: print('\n✅ 任务成功完成!') print('提取的内容:', result.extracted_content) # 将提取的内容保存到文本文件 withopen('text.txt', 'w') as file: file.write(result.extracted_content) print("提取的内容已保存到 text.txt") break asyncio.run(main())
现在我们定义工作目录并检查当前工作目录中是否存在名为 dickens 的目录。如果不存在,程序将创建它。这确保了该目录可用于存储文件或其他资源。
WORKING_DIR = "./dickens" if not os.path.exists(WORKING_DIR): os.mkdir(WORKING_DIR)
主要步骤是使用必要的参数配置 LightRAG 实例。我们使用工作目录(./dickens)和轻量级 GPT-4o 模型(gpt_4o_mini_complete)作为默认语言模型进行初始化。此设置对于增强检索任务是高效的,如果需要,可以灵活使用更强大的模型(gpt_4o_complete)。
rag = LightRAG( working_dir=WORKING_DIR, llm_model_func=gpt_4o_mini_complete # 使用 gpt_4o_mini_complete LLM 模型 # llm_model_func=gpt_4o_complete # 可选,使用更强的模型 )
我们从指定路径读取 text.txt 的内容,并使用 rag.insert() 将其插入 RAG 系统。
with open("C:/Users/mrtar/Desktop/lightrag/text.txt") as f: rag.insert(f.read())
我们对查询 “What is Supervised Fine-Tuning” 在 RAG 系统中执行 简单搜索。在简单搜索模式下,系统查找直接包含查询中关键字的文档或条目,而不考虑这些术语周围的任何关系或上下文。对于不需要复杂推理的简单查询,它非常有用。它将仅基于关键字匹配返回结果。
## 执行简单搜索 print(rag.query("what is Supervised Fine-Tuning", param=QueryParam(mode="naive")))
此外,我们对查询 “What is Supervised Fine-Tuning?” 执行 局部搜索。在局部搜索模式下,系统检索与查询及其直接邻居(直接相关的实体)相关的信息。它将提供额外的上下文,专注于与 “Supervised Fine-Tuning” 直接相关的紧密关系。
搜索比简单搜索更详细,当您需要更多关于直接连接或关系的上下文时非常有价值。
## 执行局部搜索 print(rag.query("what is Supervised Fine-Tuning", param=QueryParam(mode="local")))
现在,我们对查询 “What is Supervised Fine-Tuning” 使用 全局搜索。在全局搜索模式下,系统考虑整个知识图谱,查看更广泛范围内的直接和间接关系。它检查与 “Supervised Fine-Tuning” 相关的所有可能连接,而不仅仅是直接的。它提供了全面的概述,适合需要广泛上下文或全局关系视角的查询。
## 执行全局搜索 print(rag.query("what is Supervised Fine-Tuning", param=QueryParam(mode="global")))
最后,我们对查询 "What is Supervised Fine-Tuning” 执行 混合搜索。混合搜索模式结合了局部搜索和全局搜索的优点。它根据直接关系(如局部搜索)检索信息,但也考虑间接或全局关系(如全局搜索)。它提供了平衡和全面的上下文,适合大多数场景,特别是在理解整体和特定上下文时至关重要。
## 执行混合搜索 print(rag.query("what is Supervised Fine-Tuning", param=QueryParam(mode="hybrid")))\
结论:
不仅仅是技术进步,LightRAG 和 Browser-Use 潜在地可以从根本上改变我们与信息的互动方式。它们提供更准确和全面的搜索能力、对复杂问题的精确回答,以及始终反映最新知识的响应。
如果这些目标得以实现,它们可能会彻底改变教育、研究和商业等领域。LightRAG 和 Browser-Use 代表了开创性的技术,将开启下一代信息搜索和生成。我非常期待看到它们在未来的发展!
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

学会后的收获:
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】
