Storm :twitter的实时数据处理工具
昨天在家里一直发不出文章,于是干脆先发到了iteye上。
Twitter在9月19日的Strange Loop大会上公布Storm的代码。这个类似于Hadoop的即时数据处理工具是BackType开发的,后来被Twitter收购用于Twitter。
Twitter列举了Storm的三大类应用:
1. 信息流处理{Stream processing}
Storm可用来实时处理新数据和更新数据库,兼具容错性和可扩展性。
2. 连续计算{Continuous computation}
Storm可进行连续查询并把结果即时反馈给客户端。比如把Twitter上的热门话题发送到浏览器中。
3. 分布式远程程序调用{Distributed RPC}
Storm可用来并行处理密集查询。Storm的拓扑结构是一个等待调用信息的分布函数,当它收到一条调用信息后,会对查询进行计算,并返回查询结果。 举个例子Distributed RPC可以做并行搜索或者处理大集合的数据。
storm集群的组成部分
Storm集群类似于一个Hadoop集群。 然而你在Hadoop的运行“MapReduce job”,在storm上你运行“topologies (不好翻译)”。 “job”和“topologies ”本身有很大的不同 - 一个关键的区别是,MapReduce的工作最终完成,而topologies 处理消息永远保持(或直到你杀了它)。
Strom集群有主要有两类节点:主节点和工作节点。 主节点上运行一个叫做“Nimbus ”的守护进程,也就是类似Hadoop的“JobTracker”。 Nimbus 负责在集群分发的代码,将任务分配给其他机器,和故障监测。
每个工作节点运行一个叫做”Supervisor”的守护进程 。 Supervisor监听分配给它的机器,根根据Nimbus 的委派在必要时启动和关闭工作进程。 每个工作进程执行topology 的一个子集。一个运行中的topology 由很多运行在很多机器上的工作进程组成。
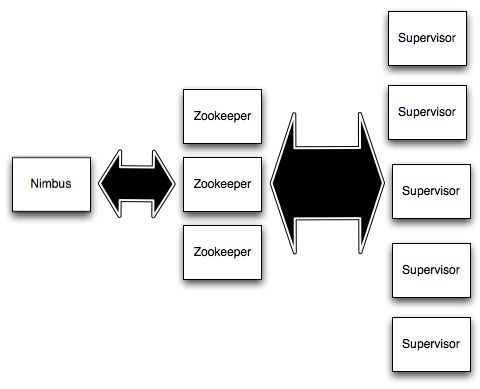
Nimbus 和Supervisors 之间所有的协调工作是通过 一个Zookeeper 集群。 此外,Nimbus的守护进程和Supervisors 守护进程是无法连接和无状态的;所有的状态维持在Zookeeper中 或保存在本地磁盘上。这意味着你可以kill -9 Nimbus 或Supervisors 进程,所以他们不需要做备份。 这种设计导致storm集群具有令人难以置信的稳定性。
运行STORM TOPOLOGY
运行一个topology 非常简单。 首先,你打包成一个单独jar,并设置要依赖关系。 然后,您可以运行如下命令:
storm jar all-my-code.jar backtype.storm.MyTopology arg1 arg2
这运行参数arg1和 arg2类backtype.storm.MyTopology。 主要功能是定义topology 的结构,并提交给Nimbus 。 Storm JAR的一部分连接到Nimbus 和上传的jar。
由于topology 的定义只是Thrift 的结构,Nimbus 是一个Thrift 服务,您可以使用任何语言创建和提交的topology 。 上面的例子是最简单的方式。
流和拓扑结构
让我们深入到抽象的storm,揭露其可扩展的实时计算。 为了方便理解这个抽象概念,我会配合连同strom topology 的一个具体的例子一切。
在storm的核心概念是“流(stream)”。 流是一个无限序列的元组。 Storm提供了一个分布式的和可靠的方式将一个流到一个新流的转换组件。 例如,你可以转变一个消息到一个热门主题。
Strom提供为流转换的基本组件:“spouts (喷口)”和“bolts(螺栓 ) ”。 spouts 和bolts提供的接口,可以让你的应用程序继承这些接口并具体实现。
一个spouts 是一个流的源头。 例如,一个spouts 可以读取元组的一个Kestrel队列并且 并发流出。 或spouts 连接到Twitter的API,并发表消息流。
Bolts用来单步流转换。 它基于其输入流创建新的流。 其复杂的流转换,犹如从信息流中计算出流行趋势的流,需要多个步骤,因此需要多种Bolts。
多个步骤的流转换打包成“topology ”,这是您提交给strom集群执行的最高级的抽象。 topology 是一个流转换图,其中每个节点是一个spouts 或Bolts。 在图中的边表示Bolts订阅哪些流。 当spouts 或Bolts发出一个元组到流,它发送到每一个订阅该流的Bolts。
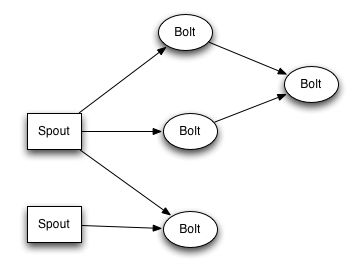
任何事物都在storm中已分布式的方式并行运行。 spouts 和bolts在集群中的许多线程中执行,他们在一个分布式的方式中传递相互的信息。 信息从来没有通过任何中央路由器,而且没有中间队列。 一个元组是通过直接从谁创造了它,需要消耗它的线程的线程。
storm保证每个经过的topology 的消息都将被处理,即使一台机器出现故障,这条消息会丢弃。 storm如何实现无需任何中间排队这是它的工作原理和如此之快的关键。
让我们看一下嘴,bolts的一个具体的例子,和topology 来巩固概念。
一个简单的例子拓扑
Topology的例子展示“单词频率的流” 。 Topology包含一个spout用来发出句子,并最终由bolt发出的每个单词在所有句子出现的次数。 每一个单词的次数更新时,一个新的计数放出。 Topology看起来像这样:

这里是你如何在java中定义Topology:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(1, new KestrelSpout("kestrel.backtype.com",
22133,
"sentence_queue",
new StringScheme()));
builder.setBolt(2, new SplitSentence(), 10)
.shuffleGrouping(1);
builder.setBolt(3, new WordCount(), 20)
.fieldsGrouping(2, new Fields("word"));
这种Topology的spout从句子队列中读取句子,在kestrel.backtype.com位于一个Kestrel的服务器端口22133。
Spout用setSpout方法插入一个独特的id到Topology。 Topology中的每个节点必须给予一个ID,ID是由其他bolts用于订阅该节点的输出流。 KestrelSpout在Topology中id为1。
setBolt是用于在Topology中插入bolts。 在Topology中定义的第一个bolts 是切割句子的bolts。 这个bolts 将句子流转成成单词流。 让我们看看SplitSentence实施:
publicclassSplitSentenceimplementsIBasicBolt{
public void prepare(Map conf, TopologyContext context) {
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
关键的方法是 execute方法。 正如你可以看到,它将句子拆分成单词,并发出每个单词作为一个新的元组。 另一个重要的方法是declareOutputFields,其中宣布bolts输出元组的架构。 在这里宣布,它发出一个域为word的元组
bolts可以实现在任何语言。 下面是在Python中实现相同的bolts:
Import storm
classSplitSentenceBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
setBolt的最后一个参数是你想为bolts的并行量。 SplitSentence bolts 是10个并发,这将导致在storm集群中有十个线程并行执行。 你所要做的的是增加bolts的并行量在遇到Topology的瓶颈时。
setBolt方法返回一个对象,bolts的输入。 例如,SplitSentence螺栓订阅组件“1”使用随机分组的输出流。 “1”是指已经定义KestrelSpout。 我将解释在某一时刻的随机分组的一部分。 到目前为止,最要紧的是,SplitSentence bolts会消耗KestrelSpout发出的每一个元组。
blots可以订阅多个输入流,通过链接输入报关单的,像这样:
builder.setBolt(4,newMyBolt(),12)
.shuffleGrouping(1)
.shuffleGrouping(2)
.fieldsGrouping(3, new Fields("id1", "id2"));
You would use this functionality to implement a streaming join, for instance.
The final bolt in the streaming word count topology, WordCount, reads in the words emitted by SplitSentence and emits updated counts for each word. Here’s the implementation of WordCount:
public class WordCount implements IBasicBolt {
private Map<String, Integer> _counts = new HashMap<String, Integer>();
public void prepare(Map conf, TopologyContext context) {
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);
int count;
if(_counts.containsKey(word)) {
count = _counts.get(word);
} else {
count = 0;
}
count++;
_counts.put(word, count);
collector.emit(new Values(word, count));
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
WordCount maintains a map in memory from word to count. Whenever it sees a word, it updates the count for the word in its internal map and then emits the updated count as a new tuple. Finally, in declareOutputFields the bolt declares that it emits a stream of 2-tuples named “word” and “count”.
The internal map kept in memory will be lost if the task dies. If it’s important that the bolt’s state persist even if a task dies, you can use an external database like Riak, Cassandra, or Memcached to store the state for the word counts. An in-memory HashMap is used here for simplicity purposes.
Finally, the WordCount bolt declares its input as coming from component 2, theSplitSentence bolt. It consumes that stream using a “fields grouping” on the “word” field.
“Fields grouping”, like the “shuffle grouping” that I glossed over before, is a type of “stream grouping”. “Stream groupings” are the final piece that ties topologies together.
STREAM GROUPINGS
A stream grouping tells a topology how to send tuples between two components. Remember, spouts and bolts execute in parallel as many tasks across the cluster. If you look at how a topology is executing at the task level, it looks something like this:
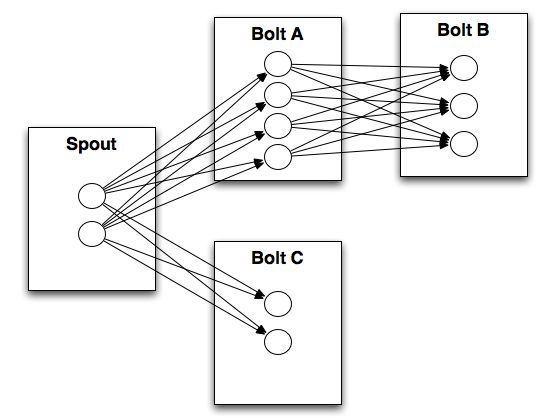
When a task for Bolt A emits a tuple to Bolt B, which task should it send the tuple to?
A “stream grouping” answers this question by telling Storm how to send tuples between sets of tasks. There’s a few different kinds of stream groupings.
The simplest kind of grouping is called a “shuffle grouping” which sends the tuple to a random task. A shuffle grouping is used in the streaming word count topology to send tuples from KestrelSpout to the SplitSentence bolt. It has the effect of evenly distributing the work of processing the tuples across all of SplitSentence bolt’s tasks.
A more interesting kind of grouping is the “fields grouping”. A fields grouping is used between the SplitSentence bolt and the WordCount bolt. It is critical for the functioning of the WordCount bolt that the same word always go to the same task. Otherwise, more than one task will see the same word, and they’ll each emit incorrect values for the count since each has incomplete information. A fields grouping lets you group a stream by a subset of its fields. This causes equal values for that subset of fields to go to the same task. Since WordCount subscribes to SplitSentence‘s output stream using a fields grouping on the “word” field, the same word always goes to the same task and the bolt produces the correct output.
Fields groupings are the basis of implementing streaming joins and streaming aggregations as well as a plethora of other use cases. Underneath the hood, fields groupings are implemented using consistent hashing.
There are a few other kinds of groupings, but talking about those is beyond the scope of this post.
With that, you should now have everything you need to understand the streaming word count topology. The topology doesn’t require that much code, and it’s completely scalable and fault-tolerant. Whether you’re processing 10 messages per second or 100K messages per second, this topology can scale up or down as necessary by just tweaking the amount of parallelism for each component.
THE COMPLEXITY THAT STORM HIDES
The abstractions that Storm provides are ultimately pretty simple. A topology is composed of spouts and bolts that you connect together with stream groupings to get data flowing. You specify how much parallelism you want for each component, package everything into a jar, submit the topology and code to Nimbus, and Storm keeps your topology running forever. Here’s a glimpse at what Storm does underneath the hood to implement these abstractions in an extremely robust way.
- 有保证的消息处理: Storm guarantees that each tuple coming off a spout will be fully processed by the topology. To do this, Storm tracks the tree of messages that a tuple triggers. If a tuple fails to be fully processed, Storm will replay the tuple from the Spout. Storm incorporates some clever tricks to track the tree of messages in an efficient way.
- 强大的流程管理: One of Storm’s main tasks is managing processes around the cluster. When a new worker is assigned to a supervisor, that worker should be started as quickly as possible. When that worker is no longer assigned to that supervisor, it should be killed and cleaned up.
An example of a system that does this poorly is Hadoop. When Hadoop launches a task, the burden for the task to exit is on the task itself. Unfortunately, tasks sometimes fail to exit and become orphan processes, sucking up memory and resources from other tasks.
In Storm, the burden of killing a worker process is on the supervisor that launched it. Orphaned tasks simply cannot happen with Storm, no matter how much you stress the machine or how many errors there are. Accomplishing this is tricky because Storm needs to track not just the worker processes it launches, but also subprocesses launched by the workers (a subprocess is launched when a bolt is written in another language).
The nimbus daemon and supervisor daemons are stateless and fail-fast. If they die, the running topologies aren’t affected. The daemons just start back up like nothing happened. This is again in contrast to how Hadoop works.
- 故障检测和自动重新分配: Tasks in a running topology heartbeat to Nimbus to indicate that they are running smoothly. Nimbus monitors heartbeats and will reassign tasks that have timed out. Additionally, all the tasks throughout the cluster that were sending messages to the failed tasks quickly reconnect to the new location of the tasks.
- 高效的消息传递: No intermediate queuing is used for message passing between tasks. Instead, messages are passed directly between tasks using ZeroMQ. This is simpler and way more efficient than using intermediate queuing. ZeroMQ is a clever “super-socket” library that employs a number of tricks for maximizing the throughput of messages. For example, it will detect if the network is busy and automatically batch messages to the destination.
Another important part of message passing between processes is serializing and deserializing messages in an efficient way. Again, Storm automates this for you. By default, you can use any primitive type, strings, or binary records within tuples. If you want to be able to use another type, you just need to implement a simple interface to tell Storm how to serialize it. Then, whenever Storm encounters that type, it will automatically use that serializer.
- 本地模式和分布式模式: Storm has a “local mode” where it simulates a Storm cluster completely in-process. This lets you iterate on your topologies quickly and write unit tests for your topologies. You can run the same code in local mode as you run on the cluster.
Storm is easy to use, configure, and operate. It is accessible for everyone from the individual developer processing a few hundred messages per second to the large company processing hundreds of thousands of messages per second.
RELATION TO “COMPLEX EVENT PROCESSING”
Storm exists in the same space as “Complex Event Processing” systems like Esper,Streambase, and S4. Among these, the most closely comparable system is S4. The biggest difference between Storm and S4 is that Storm guarantees messages will be processed even in the face of failures whereas S4 will sometimes lose messages.
Some CEP systems have a built-in data storage layer. With Storm, you would use an external database like Cassandra or Riak alongside your topologies. It’s impossible for one data storage system to satisfy all applications since different applications have different data models and access patterns. Storm is a computation system and not a storage system. However, Storm does have some powerful facilities for achieving data locality even when using an external database.
SUMMARY
I’ve only scratched the surface on Storm. The “stream” concept at the core of Storm can be taken so much further than what I’ve shown here — I didn’t talk about things like multi-streams, implicit streams, or direct groupings. I showed two of Storm’s main abstractions, spouts and bolts, but I didn’t talk about Storm’s third, and possibly most powerful abstraction, the “state spout”. I didn’t show how you do distributed RPC over Storm, and I didn’t discuss Storm’s awesome automated deploy that lets you create a Storm cluster on EC2 with just the click of a button.
For all that, you’re going to have to wait until September 19th. Until then, I will be working on adding documentation to Storm so that you can get up and running with it quickly once it’s released. We’re excited to release Storm, and I hope to see you there at Strange Loop when it happens.
原文:http://engineering.twitter.com/2011/08/storm-is-coming-more-details-and-plans.html
| 猜你喜欢: |
| |
| |
| |
| |
| |
| 无觅 |