Node.js的学习--使用cheerio抓取网页数据 - 疯狂的原始人
打算要写一个公开课网站,缺少数据,就决定去网易公开课去抓取一些数据。
前一阵子看过一段时间的Node.js,而且Node.js也比较适合做这个事情,就打算用Node.js去抓取数据。
关键是抓取到网页之后如何获取到想要的数据呢?然后就发现了cheerio,用来解析html非常方便,就像在浏览器中使用jquery一样。
使用如下命令安装cheerio
npm install cheerio
Cheerio安装完成, 我们就可以开始工作了。 首先让我们来看一段javascript代码 这段代码可以下载任意一个网页的内容。将其放入到curl.js中,并导出。
// Utility function that downloads a URL and invokes
// callback with the data.
function download(url, callback) {
http.get(url, function(res) {
var data = "";
res.on('data', function (chunk) {
data += chunk;
});
res.on("end", function() {
callback(data);
});
}).on("error", function() {
callback(null);
});
}
exports.download = download;
然后是使用cheerio解析html,找到想要的数据。
我们先来自己分析一下页面。我们要抓取 http://v.163.com/special/opencourse/englishs1.html这个页面中的视频,视频的地址都在下载的按钮里。其中一个下载按钮的html的代码如下:
我们取到其中的href属性,只需要进行如下选择即可
在是现实,我们可以在index.js中写入如下代码
var server = require("./curl");
var url = "http://v.163.com/special/opencourse/englishs1.html"
server.download(url, function(data) {
if (data) {
//console.log(data);
var $ = cheerio.load(data);
$("a.downbtn").each(function(i, e) {
console.log($(e).attr("href"));
});
console.log("done");
} else {
console.log("error");
}
});
然后执行
node index.js
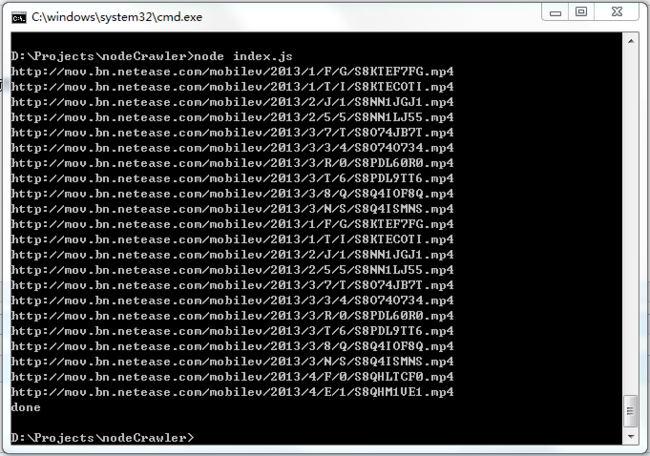
这样就可以在命令框里面打印出页面上所有的视频地址。如下图
cheerio中文API [ 参考]
我们将用到的标记示例
<li class="apple">Apple</li>
<li class="orange">Orange</li>
<li class="pear">Pear</li>
</ul>
这是我们将会在所有的API例子中用到的HTML标记
Loading
首先你需要加载HTML。这一步对jQuery来说是必须的,since jQuery operates on the one, baked-in DOM。通过Cheerio,我们需要把HTML document 传进去。
这是首选:
$ = cheerio.load('<ul id="fruits">...</ul>');
或者通过传递字符串作为内容来加载HTML:
$('ul','<ul id="fruits">...</ul>');
Or as the root:
$('li','ul','<ul id="fruits">...</ul>');
你也可以传递一个额外的对象给.load()如果你需要更改任何的默认解析选项的话:
ignoreWhitespace:true,
xmlMode:true});
这些解析选项都是直接来自htmlparser ,因此任何在htmlparser里有效的选项在Chreeio里也是行得通的。默认的选项如下:
ignoreWhitespace:false,
xmlMode:false,
lowerCaseTags:false
}
Selectors
Cheerio的选择器用起来几乎和jQuery一样,所以API也很相似。
$(selectior,[context],[root])
选择器在 Context 范围内搜索,Context又在Root范围内搜索。selector 和context可是是一个字符串表达式,DOM元素,和DOM元素的数组,或者chreeio对象。root 是通常是HTML 文档字符串。
//=> Apple
$('ul .pear').attr('class')
//=> pear
$('li[class=orange]').html()
//=> <li class="orange">Orange</li>
Attributes
获得和修改属性
.attr(name,value)
获得和修改属性。在匹配的元素中只能获得第一元素的属性。如果设置一个属性的值为null,则移除这个属性。你也可以传递一对键值,或者一个函数。
//=> fruits
$('.apple').attr('id','favorite').html()
//=> <li class="apple" id="favorite">Apple</li>
.val([value])
获得和修改input,select,textarea的value.注意: 对于传递键值和函数的支持还没有被加进去。
//=> input_text
$('input[type="text"]').val('test').html()
//=><input type="text" value="test"/>
.removeAttr(name)
通过name删除属性
//=> <li>Pear</li>
.hasClass( className )
检查匹配的元素是否有给出的类名
//=> true
$('apple').hasClass('fruit')
//=> false
$('li').hasClass('pear')
//=> true
.addClass(className)
增加class(es)给所有匹配的elements.也可以传函数。
//=> <li class="pear fruit">Pear</li>
$('.apple').addClass('fruit red').html()
//=> <li class="apple fruit red">Apple</li>
.removeClass([className])
从选择的elements里去除一个或多个有空格分开的class。如果className 没有定义,所有的classes将会被去除,也可以传函数。
//=> <li class="">Pear</li>
$('.apple').addClass('red').removeClass().html()
//=> <li class="">Apple</li>
.toggleClass( className, [switch] )
添加或删除class,依赖于当前是否有该class.
//=> <li class="apple fruit red">Apple</li>
$('.apple.green').toggleClass('fruit green red', true).html()
//=> <li class="apple green fruit red">Apple</li>
.is( selector )
.is( element )
.is( selection )
.is( function(index) )
有任何元素匹配selector就返回true。如果使用判定函数,判定函数在选中的元素中执行,所以this指向当前的元素。
Traversing
.find(selector)
获得一个在匹配的元素中由选择器滤过的后代。
//=> 3
.parent([selector])
获得每个匹配元素的parent,可选择性的通过selector筛选。
//=> fruits
.parents([selector])
获得通过选择器筛选匹配的元素的parent集合。
// => 2
$('.orange').parents('#fruits').length
// => 1
.closest([selector])
对于每个集合内的元素,通过测试这个元素和DOM层级关系上的祖先元素,获得第一个匹配的元素
$('.orange').closest('.apple')// => []
$('.orange').closest('li')// => [<li class="orange">Orange</li>]
$('.orange').closest('#fruits')// => [<ul id="fruits"> ... </ul>]
.next()
获得第一个本元素之后的同级元素
//=> true
.nextAll()
获得本元素之后的所有同级元素
//=> [<li class="orange">Orange</li>, <li class="pear">Pear</li>]
.prev()
获得本元素之前的第一个同级元素
//=> true
.preAll()
//=> [<li class="orange">Orange</li>, <li class="apple">Apple</li>]
获得本元素前的所有同级元素
.slice(start,[end])
获得选定范围内的元素
//=> 'Orange'
$('li').slice(1,2).length
//=> 1
.siblings(selector)
获得被选择的同级元素,不包括本身
//=> 2
$('.pear').siblings('.orange').length
//=> 1
.children(selector)
获被选择元素的子元素
//=> 3
$('#fruits').children('.pear').text()
//=> Pear
.each(function(index,element))
迭代一个cheerio对象,为每个匹配元素执行一个函数。When the callback is fired, the function is fired in the context of the DOM element, so this refers to the current element, which is equivalent to the function parameter element.要提早跳出循环,返回false.
$('li').each(function(i, elem){
fruits[i]= $(this).text();});
fruits.join(', ');
//=> Apple, Orange, Pear
.map(function(index,element))
迭代一个cheerio对象,为每个匹配元素执行一个函数。Map会返回一个迭代结果的数组。the function is fired in the context of the DOM element, so this refers to the current element, which is equivalent to the function parameter element
// this === el
return $(this).attr('class');
}).join(', ');
//=> apple, orange, pear
.filter(selector)
.filter(function(index))
迭代一个cheerio对象,滤出匹配选择器或者是传进去的函数的元素。如果使用函数方法,这个函数在被选择的元素中执行,所以this指向的手势当前元素。
Selector:
//=> orange
Function:
// this === el
return $(this).attr('class')==='orange';
}).attr('class')
//=> orange
.first()
会选择chreeio对象的第一个元素
//=> Apple
.last()
//=> Pear
会选择chreeio对象的最后一个元素
.eq(i)
通过索引筛选匹配的元素。使用.eq(-i)就从最后一个元素向前数。
//=> Apple
$('li').eq(-1).text()
//=> Pear
Manipulation
改变DOM结构的方法
.append(content,[content...])
在每个元素最后插入一个子元素
$.html()
//=> <ul id="fruits">
// <li class="apple">Apple</li>
// <li class="orange">Orange</li>
// <li class="pear">Pear</li>
// <li class="plum">Plum</li>
// </ul>
.prepend(content,[content,...])
在每个元素最前插入一个子元素
$.html()
//=> <ul id="fruits">
// <li class="plum">Plum</li>
// <li class="apple">Apple</li>
// <li class="orange">Orange</li>
// <li class="pear">Pear</li>
// </ul>
.after(content,[content,...])
在每个匹配元素之后插入一个元素
$.html()
//=> <ul id="fruits">
// <li class="apple">Apple</li>
// <li class="plum">Plum</li>
// <li class="orange">Orange</li>
// <li class="pear">Pear</li>
// </ul>
.before(content,[content,...])
在每个匹配的元素之前插入一个元素
$.html()
//=> <ul id="fruits">
// <li class="plum">Plum</li>
// <li class="apple">Apple</li>
// <li class="orange">Orange</li>
// <li class="pear">Pear</li>
// </ul>
.remove( [selector] )
从DOM中去除匹配的元素和它们的子元素。选择器用来筛选要删除的元素。
$.html()
//=> <ul id="fruits">
// <li class="apple">Apple</li>
// <li class="orange">Orange</li>
// </ul>
.replaceWith( content )
替换匹配的的元素
$('.pear').replaceWith(plum)
$.html()
//=> <ul id="fruits">
// <li class="apple">Apple</li>
// <li class="orange">Orange</li>
// <li class="plum">Plum</li>
// </ul>
.empty()
清空一个元素,移除所有的子元素
$.html()
//=> <ul id="fruits"></ul>
.html( [htmlString] )
获得元素的HTML字符串。如果htmlString有内容的话,将会替代原来的HTML
//=> Orange
$('#fruits').html('<li class="mango">Mango</li>').html()
//=> <li class="mango">Mango</li>
.text( [textString] )
获得元素的text内容,包括子元素。如果textString被指定的话,每个元素的text内容都会被替换。
//=> Orange
$('ul').text()
//=> Apple
// Orange
// Pear
Rendering
如果你想呈送document,你能使用html多效用函数。
//=> <ul id="fruits">
// <li class="apple">Apple</li>
// <li class="orange">Orange</li>
// <li class="pear">Pear</li>
// </ul>
如果你想呈送outerHTML,你可以使用 $.html(selector)
//=> <li class="pear">Pear</li>
By default, html will leave some tags open. Sometimes you may instead want to render a valid XML document. For example, you might parse the following XML snippet:
... and later want to render to XML. To do this, you can use the 'xml' utility function:
Miscellaneous
不属于其它地方的DOM 元素方法
.toArray()
取得所有的在DOM元素,转化为数组、
//=> [ {...}, {...}, {...} ]
.clone()
克隆cheerio对象
Utilities
$.root
Sometimes you need to work with the top-level root element. To query it, you can use $.root().
//=> <ul id="fruits">...</ul><ul id="vegetables"></ul>
$.contains( container, contained )
查看cotained元素是否是container元素的子元素
$.parseHTML( data [, context ] [, keepScripts ] )
将字符串解析为DOM节点数组。context参数对chreeio没有意义,但是用来维护APi的兼容性。
今天就到这里了~~有机会把前面的小程序完善成一个网页爬虫~~
本文链接: Node.js的学习--使用cheerio抓取网页数据,转载请注明。