ZooKeeper 使用
我觉得我需要先介绍一下 zookeeper的基础算法
Paoxs算法
Paoxs算法是Lamport在98年提出的 之后一直在改进 改进幅度最大的
动作最大的莫过于05年发布的Fast Paoxs 算法 主要改进了性能与吞吐量之间的权衡
为了区分两者 前者也成为Classic Paoxs
ZooKeeper 基础配置
详情见 http://blog.csdn.net/cxhzqhzq/article/details/6538491
TickTime=2000
initLimit=5
syncLimit=2
clientPort=2181
dataDir=/tmp/zk_data/server1/data
dataLogDir=/tmp/zk_data/server1/dataLog
server.1=127.0.0.1:2888:3888
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:3890
ZooKeeper 数据模型
ZooKeeper 使用一种继承命名空间, 很像是一个分布式文件系统.
唯一的不同是zookeeper命名空间中每个node和他的子节点数据是存在关联的
It is like having a file system that allows a file to also be a directory. Paths to nodes are always expressed as canonical, absolute, slash-separated paths; there are no relative reference.
Path可以使用任意Unicode字符表示
Any unicode character can be used in a path subject to the following constraints:
The null character (\u0000) cannot be part of a path name. (This causes problems with the C binding.)
The following characters can't be used because they don't display well, or render in confusing ways: \u0001 - \u0019 and \u007F - \u009F.
The following characters are not allowed: \ud800 -uF8FFF, \uFFF0-uFFFF, \uXFFFE - \uXFFFF (where X is a digit 1 - E), \uF0000 - \uFFFFF.
The "." character can be used as part of another name, but "." and ".." cannot alone be used to indicate a node along a path, because ZooKeeper doesn't use relative paths. The following would be invalid: "/a/b/./c" or "/a/b/../c".
The token "zookeeper" is reserved.
Zookeeper对权限的控制是节点级别的,而且不继承,即对父节点设置权限,其子节点不继承父节点的权限。
Zookeeper提供了几种认证方式
* world:有个单一的ID,anyone,表示任何人。
* auth:不使用任何ID,表示任何通过验证的用户(是通过ZK验证的用户?连接到此ZK服务器的用户?)。
* digest:使用 用户名:密码 字符串生成MD5哈希值作为ACL标识符ID。权限的验证通过直接发送用户名密码字符串的方式完成,
* ip:使用客户端主机ip地址作为一个ACL标识符,ACL表达式是以 addr/bits 这种格式表示的。ZK服务器会将addr的前bits位与客户端地址的前bits位来进行匹配验证权限。
ZNodes
Every node in a ZooKeeper tree is refered to as a znode. Znodes maintain a stat structure that includes version numbers for data changes, acl changes. The stat structure also has timestamps. The version number, together with the timestamp allow ZooKeeper to validate the cache and to coordinate updates. Each time a znode's data changes, the version number increases. For instance, whenever a client retrieves data, it also receives the version of the data. And when a client performs an update or a delete, it must supply the version of the data of the znode it is changing. If the version it supplies doesn't match the actual version of the data, the update will fail. (This behavior can be overridden. For more information see... )
Znodes are the main enitity that a programmer access. They have several characteristics that are worth mentioning here.
Watches
Clients can set watches on znodes. Changes to that znode trigger the watch and then clear the watch. When a watch triggers, ZooKeeper sends the client a notification. More information about watches can be found in the section ZooKeeper Watches.
Data Access
命名空间中每个节点存储的数据读写都是原子操作,读操作得到znode的字节数组,写操作将替换原有的数据
每个node有一个访问控制列表用来决定用户权限
Ephemeral Nodes
ZooKeeper also has the notion of ephemeral nodes.
These znodes exists as long as the session that created the znode is active.
When the session ends the znode is deleted. Because of this behavior ephemeral znodes are not allowed to have children.
Data File Management
ZooKeeper的数据文件和TLog文件分别存储在两个目录下 但是默认情况下这两个目录是一个
TLog 存储在单独的存储设备上有助于提高吞吐量以及降低延迟
1. When the session of the client creator ends, either by expiration or because it ex‐plicitly closed.
2. When a client, not necessarily the creator, deletes it.
This directory has two files in it:
myid - contains a single integer in human readable ASCII text that represents the server id.
snapshot.<zxid> - holds the fuzzy snapshot of a data tree.
目前临时节点还不支持子节点
ZooKeeper在分布式系统中主要解决了三个问题:Master crashes Worker crashes Communication failures
Master Crashes:主要是在原Master宕机之后 有一个备份Master启动代替原Master提供服务
Sequential znodes:
znode可以设置一组序列,Sequential znodes可以被设置一个单调递增的整数序列
create znode的时候可把序号添加在路径后
for example : client新建一个seq-znode 在/tasks/ ZooKeeper分配序号1
新建的节点即为/tasks/task-1
总结一下 Create ZNode 有四种方式:
persistent, ephemeral, persistent_sequential, and ephemeral_sequential
Watch & Notification机制
client向zookeeper注册节点改变事件,当指定节点数据发生变化的时候,触发client设置的watch。
ZooKeeper Command Four Letter Word:
| conf | Print details about serving configuration 输出相关服务配置的详细信息 |
| cons | List session details connected to this server 列出所有连接到服务器的客户端的完全的连接 / 会话的详细信息 包括“接受 / 发送”的包数量、会话 id 、操作延迟、最后的操作执行等等信息。 |
| crst | Reset session statistics for all connections. |
| dump | Lists outstanding sessions and ephemeral nodes 列出未经处理的会话和临时节点。 |
| envi | Print details about serving environment 输出关于服务环境的详细信息 |
| ruok | Testing if server is running in a non-error state 测试服务是否处于正确状态。如果确实如此,那么服务返回“imok ”,否则不做任何相应。 |
| srst | Reset server statistics |
| srvr | Lists full details for the server |
| stat | Lists brief details for the server and clients 输出关于性能和连接的客户端的列表。 |
| wchs | Lists brief information on watches 列出服务器 watch 的详细信息。 |
| wchc | Lists detailed information on watches 通过 session 列出服务器 watch 的详细信息,它的输出是一个与watch 相关的会话的列表。 |
| wchp | Lists detailed information on watches 通过路径列出服务器 watch 的详细信息。它输出一个与 session相关的路径。 |
| mntr | Output a list of variable monitoring health cluster |
ZooKeeper 日志清理:
bin/zkCleanup.sh --> cleans up old transaction logs and snapshots
bin/zkCleanup.sh --help
PurgeTxnLog dataLogDir [snapDir] -n count
dataLogDir -- path to the txn log directory
snapDir -- path to the snapshot directory
count -- the number of old snaps/logs you want to keep
ZooKeeper中的ACL不同于传统文件系统 znode的ACL不存在继承关系
ZK的ACL可以从三个维度理解 scheme user permission
通常表示为scheme:id:permissions
简单说使用了一下ZK
利用 ZooKeeper实现 分布式lock
主要是通过一个Node来代表一个Lock,
当一个client去拿锁的时候,会在这个Node下创建一个自增序列的child,
然后通过getChildren()方式来check创建的child是不是最靠前的,如果是则拿到锁,
否则就调用exist()来check第二靠前的child,并加上watch来监视。
当拿到锁的child执行完后归还锁,归还锁仅仅需要删除自己创建的child,
这时watch机制会通知到所有没有拿到锁的client,这些child就会根据前面所讲的拿锁规则来竞争锁。
Zookeeper分层配额机制:
文档上举了一个例子……
首先 对server进行分组 组之间添加一个空行 用空行标示不同的组 并为每个组分配权重
group.1=1:2:3
group.2=4:5:6
group.3=7:8:9
weight.1=1
weight.2=1
weight.3=1
weight.4=1
weight.5=1
weight.6=1
weight.7=1
weight.8=1
weight.9=1
这个例子里面配置了三组 每组三个server 并为每个server分配权重为1
Zookeeper 中分为三种角色: leader,follower,observer 四种状态:leading,following,observing,looking
observer 是在zookeeper3.3版本中引入用来解决拜占庭将军问题
observer 与 follower 作用一致
Zookeeper服务自身组成一个集群(2n+1个服务允许n个失效)。
Zookeeper服务有两个角色,
一个是leader,负责写服务和数据同步,
剩下的是follower,提供读服务,leader失效后会在follower中重新选举新的leader。
client 可以连接到每一个server 每个server都会保留一份完整的数据
每个follower 都和leader 保持连接 同步leader数据变更
server记录快照和持久存储到文件系统
Zookeeper 特点
顺序一致性:按照客户端发送请求的顺序更新数据。
原子性:更新要么成功,要么失败,不会出现部分更新。
单一性 :无论客户端连接哪个server,都会看到同一个视图。
可靠性:一旦数据更新成功,将一直保持,直到新的更新。
及时性:客户端会在一个确定的时间内得到最新的数据。
我累了 未完待续
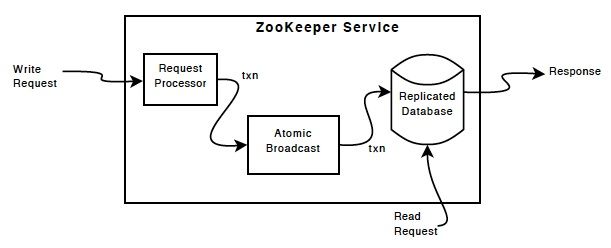
Atomic Broadcast
Zookeeper内部使用slf4J作为日志抽象层,log4J作为日志具体实现
参考文献:
O'Reilly ZooKeeper.Distributed Process Coord
ZooKeeper: Because Coordinating Distributed Systems is a Zoo http://zookeeper.apache.org/doc/r3.4.6/
http://www.infoq.com/presentations/Misconfiguration-ZooKeeper
http://marcin.cylke.com.pl/blog/2013/03/21/zookeeper-tips/
http://zookeeper.apache.org/doc/r3.4.6/zookeeperAdmin.html
说说zookeeper中的ACL : http://www.wuzesheng.com/?p=2438&cpage=1
http://blog.csdn.net/cutesource/article/details/5822459
http://bbs.csdn.net/topics/390329494