Android表情的处理方案记录
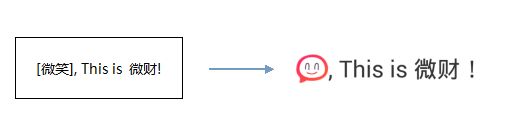
我们的目标,就是把表情的编码变成图片显示在文字中。在Android中,TextView本身已经支持了图文混排的样式。因此,在文字中插入一张表情图片并不困难,用下面的代码就可以做到了:
ImageSpan faceSpan = new ImageSpan(context, bmFace); spannable.setSpan(faceSpan, faceStrat, faceEnd, Spannable.SPAN_EXCLUSIVE_EXCLUSIVE);
不过,事情往往没那么简单,让我们逐步看看会遇到什么问题。
1. 不同屏幕的表情如何适配?
为了尽量减少安装包的大小,表情肯定只能放一份在drawable中。那么,为了让表情在不同屏幕中显示的效果保持一致,我们就要设计成让表情图片可以按照dp的单位进行缩放。
faceSize = dpToPx(dp); Bitmap bmFace = Bitmap.createScaledBitmap(bmSrcFace, faceSize, faceSize, true);
在表情不多的情况下,每一次都对表情图片进行缩放处理是没有什么问题的,但是我们都不知道用户究竟会输入多少表情。所以,为了减少表情的处理,我们需要对缩放后的表情图片进行缓存,以后直接取缩放的图片就好了。
2. 如何对缩放后的表情进行缓存?
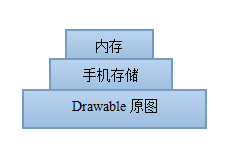
在客户端的缓存设计中,一般都是采用这种三级的缓存策略,其中最下面的那层可能是来自远程服务器的。
这样,我们可以把表情的key值设计成:
drawable://drawableName?w=10&h=10
其中,drawableName是R.drawable.expression_smile 中的 "expression_smile" 部分, w为要取得表情图片的宽度,h为高度。
单个表情的加载逻辑就大致如下:
Bitmap bmFace = memeryCache.getKey(faceDrawableUri);
if(bmFace == null){
bmFace = diskCache.getKey(faceDrawableUri);
if(bmFace == null){
int drawableId = getDrawableIdFromUri(faceDrawableUri);
int width = getDestWidth(faceDrawableUri);
int height = getDestHeight(faceDrawableUri);
Bitmap srcBitmap = loadFromDrawable(drawableId);
bmFace = resize(srcBitmap , width , height );
saveToDisk(bmFace);
memeryCache.putKey(faceDrawableUri,bmFace);
}
}
return bmFace;
当然,这里还会牵涉到比较复杂的各级缓存池管理问题,我们在这里不展开。如果你是采用universalimageloader这个库的,那么你要做的就只是继承BaseImageDownloader,然后重写getStreamFromDrawable方法就可以了。
这里值得一提的是:为什么要用图片的名字,而不是drawable的Id值呢?要在drawable中加载图片是要使用int类型的Id值的呀!原因就是系统在R文件中生成的Id值每一次重新编译后产生的值都是不一样的,因此不能作为缓存的key, 所以需要多一步的反射R文件,把drawable的Id值取出来:
public static int getDrawableIdByName(String faceValue){
if(DRAWABLE_ID_MAP.containsKey(faceValue)){ // DRAWABLE_ID_MAP用来缓存Drawable的Id
return DRAWABLE_ID_MAP.get(faceValue);
}
try {
Class<?> drawableClazz = R.drawable.class;
java.lang.reflect.Field field = drawableClazz.getField(faceValue);
int drawableId = field.getInt(DRAWABLE_INSTANCE);
DRAWABLE_ID_MAP.put(faceValue, drawableId);
return drawableId;
} catch (NoSuchFieldException e) {
DLog.e("the drawable " + faceValue + " doesn't exsits...");
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return -1;
}
到这里为止,我们的表情图片尽可能快地获取到了。我们总结一下表情是如何加载到我们的文字中的先:
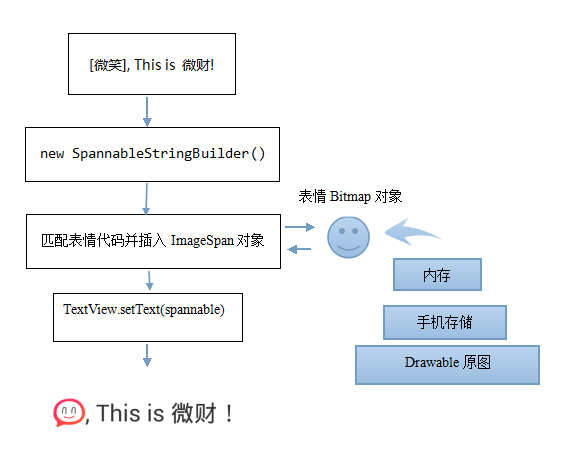
这里的关键就是ImageSpan对象所需要的表情图片的处理过程了,优先取内存中处理好的表情,这样的处理无疑可以加快了表情图片的加载速度,代价就是需要损耗更多的存储空间,对于用户体验的提示,这点空间不算太大,比如:
这里的表情有两种大小,那么,最终最多会在手机端产生3中尺寸的表情,按照表情的原大小5K一个计算,那一百个也就是1M左右,这是完全可以接受的。
3. 如何在ListView中进一步优化流畅度?
表情的处理到这里还没结束,如果你是要在ListView的Item中添加大量的表情,到目前为止,你还是会感到有比较强烈的卡顿现象的。没猜错的话,你应该是在ListAdapter的getView方法中对字符串进行了处理:
@Override
public View getView(final int position, View convertView, ViewGroup parent) {
...
Model data = listData.get(position);
CharSequence textSpannable = addFaceStyle(data.content);
textView.setText(textSpannable);
}
这样相当于在UI线程进行了表情的处理,优化思路也比较明确,把addFaceStyle()的过程在后台返回的过程中就处理好,这样,content一开始就是添加了各种样式(包括表情,@人等样式)的Spannable类型对象。
//backgroud thread
public void doBackgroud(){
Model data = requestRemote();
data.content = addFaceStyle(data.content);
}
到此为此,出现较多的表情的ListView也能得到不错的流畅度了,优化是永无止境的,让我们先告一段落吧。
也可以阅读: http://www.darcye.com/article/63343732