spark总体概况
1. spark vs hadoop

PS:Databricks团队特别说明,为了和Hadoop对比,这次用于排序的Spark集群没有使用它们的内存缓存机制,他们也是用硬盘存储的中间结果!
http://tieba.yunxunmi.com/mtieba-hadoop-kz-58b9e430a78747f7fb1ea9f9e6374597.html
但是我们要明白,spark的目标是与hadoop共存的,就算很多地方把hadoop优秀,但spark绝对不是替代hadoop的,目前 spark的standalone模式还是有很多局限性,而在中国 像董西成这样hadoop 以及YARN的布道者,导致中国很多人对YARN的理解和使用超过mesos
2. spark 整体框架
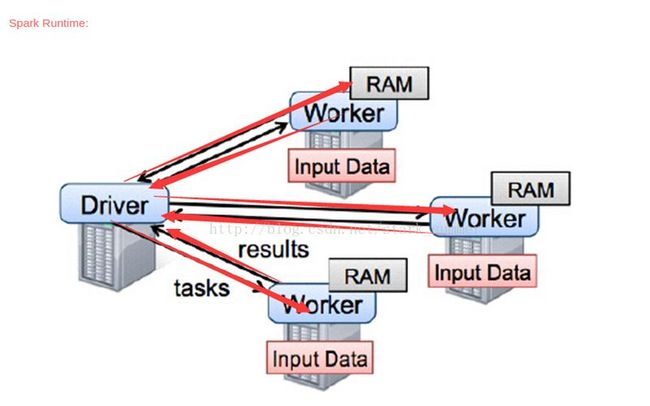
部署图: 
从部署图中可以看到
整个集群分为 Master 节点和 Worker 节点,相当于 Hadoop 的 Master 和 Slave 节点。
Master 节点上常驻 Master 守护进程,负责管理全部的 Worker 节点。
Worker 节点上常驻 Worker 守护进程,负责与 Master 节点通信并管理 executors。
Driver 官方解释是 “The process running the main() function of the application and creating the SparkContext”。 核心就算创建SparkContext
Application 就是用户自己写的 Spark 程序(driver program),比如 WordCount.scala。如果 driver program 在 Master 上运行,比如在 Master 上运行
目前Hadoop1.x(JobTracker and TaskTracker),JobTracker是单点的,Hadoop2.x(ResourceManager,NodeManager,ApplicationManager),ResourceManager也是单点
那 spark master也是单点么?
NO,可以支持多master
在SPARK_HOME/conf/spark_env.sh配置如下信息:
- ZOOKEEPER实现HA:
spark.deploy.recoveryMode=ZOOKEEPER
spark.deploy.zookeeper.url=zk_server_1:2181,zk_server_2:2181
spark.deploy.zookeeper.dir=/dir
or
export SPARK_DAEMON_JAVA_OPTS=”-Dspark.deploy.recoveryMode=ZOOKEEPER ”
export SPARK_DAEMON_JAVA_OPTS=”${SPARK_DAEMON_JAVA_OPTS} -Dspark.deploy.zookeeper.url=zk_server1:2181,zk_server_2:2181”
- FILESYSTEM:
export SPARK_DAEMON_JAVA_OPTS=”-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/nfs/spark/recovery”
但是要注意,当我们配置完多master后,启动在提交任务或者启动spark-shell时,需要增加MASTER=spark://master001:7077,master002:7077
最简单的wordcount: 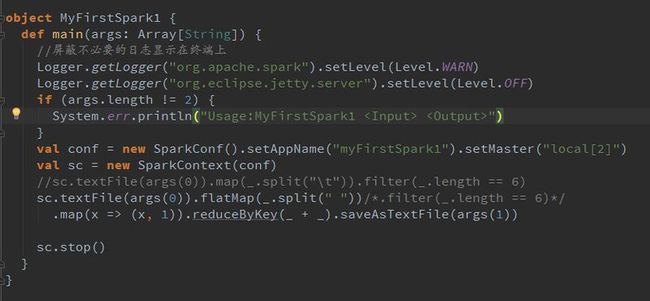
spark 任务分析: 
具体到Your Program: 
what is RDD?


what is transformation?
map,filter, flatMap, mapPartitions, mapPartitionsWithIndex, sample, pipe, union, intersection,distinct, groupByKey, reduceByKey, sortByKey, join, cogroup, cartesian, coalesce,repartition 这些都是transformation,属于lazy execution,主要做数据转换what is action?
reduce, collect, count, take,first, takeSample, saveAsTextFile, saveAsSequenceFile, saveAsObjectFile, countByKey,foreach这些操作会触发spark真正任务执行




3. shuffle
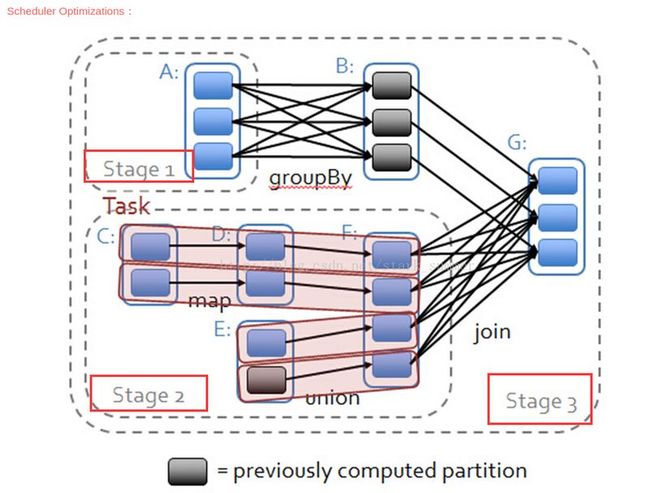
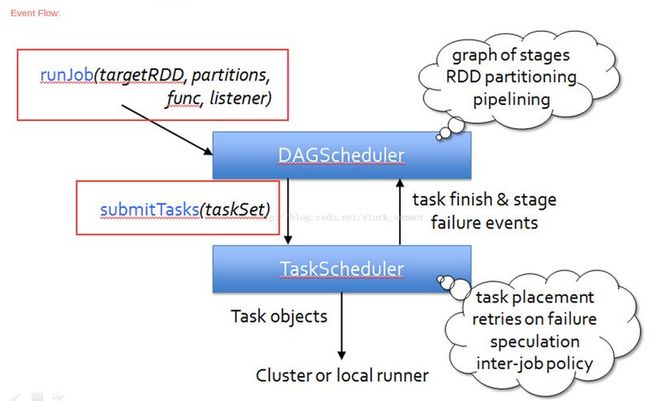
在 Spark 中,没有这样功能明确的阶段。Spark将用户定义的计算过程转化为一个被称作Job逻辑执行图的有向无环图(DAG),图中的顶点代表RDD,边代表RDD之间的依赖关系。再将这个逻辑执行图转化为物理执行图,具体方法是:从逻辑图后往前推算,遇到 ShuffleDependency 就断开,最后根据断开的次数n,将其化分为(n+1)个stage。每个 stage 里面 task 的数目由该 stage 最后一个 RDD 中的 partition 个数决定。因此,Spark的Job的shuffle数是不固定的。
在Spark早期的版本中,Spark使用的是hash-based的shuffle,通常使用 HashMap 来对 shuffle 来的数据进行聚合,不会对数据进行提前排序。而Hadoop MapReduce 一直使用的就是 sort-based shuffle,进入 combine和 reduce的数据都会先经过排序(mapper 对每段数据先做排序,reducer 的 shuffle 对排好序的每段数据做归并)。不过在Spark1.1已经支持sorted-basedshuffle,在这一点上做到了扬长避短。这次排序比赛中所使用的是Spark 1.2,采用的就是sorted-based shuffle。
此外,Databricks还创建了一个外部shuffle服务,该服务和Spark执行器(executor)本身是分离的。这个服务使得即使是Spark 执行器在因GC导致的暂停时仍然可以正常进行shuffle。
Shuffle write
由于不要求数据有序,shuffle write 的任务很简单:将数据 partition 好,并持久化。之所以要持久化,一方面是要减少内存存储空间压力,另一方面也是为了 fault-tolerance。
shuffle write 的任务很简单,那么实现也很简单:将 shuffle write 的处理逻辑加入到 ShuffleMapStage(ShuffleMapTask 所在的 stage) 的最后,该 stage 的 final RDD 每输出一个 record 就将其 partition 并持久化。图示如下: 
上图有 4 个 ShuffleMapTask 要在同一个 worker node 上运行,CPU core 数为 2,可以同时运行两个 task。每个 task 的执行结果(该 stage 的 finalRDD 中某个 partition 包含的 records)被逐一写到本地磁盘上。每个 task 包含 R 个缓冲区,R = reducer 个数(也就是下一个 stage 中 task 的个数),缓冲区被称为 bucket,其大小为spark.shuffle.file.buffer.kb ,默认是 32KB(Spark 1.1 版本以前是 100KB)。
其实 bucket 是一个广义的概念,代表 ShuffleMapTask 输出结果经过 partition 后要存放的地方,这里为了细化数据存放位置和数据名称,仅仅用 bucket 表示缓冲区。
ShuffleMapTask 的执行过程很简单:先利用 pipeline 计算得到 finalRDD 中对应 partition 的 records。每得到一个 record 就将其送到对应的 bucket 里,具体是哪个 bucket 由partitioner.partition(record.getKey()))决定。每个 bucket 里面的数据会不断被写到本地磁盘上,形成一个 ShuffleBlockFile,或者简称 FileSegment。之后的 reducer 会去 fetch 属于自己的 FileSegment,进入 shuffle read 阶段。
这样的实现很简单,但有几个问题:
产生的 FileSegment 过多。每个 ShuffleMapTask 产生 R(reducer 个数)个 FileSegment,M 个 ShuffleMapTask 就会产生 M * R 个文件。一般 Spark job 的 M 和 R 都很大,因此磁盘上会存在大量的数据文件。
缓冲区占用内存空间大。每个 ShuffleMapTask 需要开 R 个 bucket,M 个 ShuffleMapTask 就会产生 M * R 个 bucket。虽然一个 ShuffleMapTask 结束后,对应的缓冲区可以被回收,但一个 worker node 上同时存在的 bucket 个数可以达到 cores * R 个(一般 worker 同时可以运行 cores 个 ShuffleMapTask),占用的内存空间也就达到了cores * R * 32 KB。对于 8 核 1000 个 reducer 来说,占用内存就是 256MB。
目前来看,第二个问题还没有好的方法解决,因为写磁盘终究是要开缓冲区的,缓冲区太小会影响 IO 速度。但第一个问题有一些方法去解决,下面介绍已经在 Spark 里面实现的 FileConsolidation 方法。先上图: 
可以明显看出,在一个 core 上连续执行的 ShuffleMapTasks 可以共用一个输出文件 ShuffleFile。先执行完的 ShuffleMapTask 形成 ShuffleBlock i,后执行的 ShuffleMapTask 可以将输出数据直接追加到 ShuffleBlock i 后面,形成 ShuffleBlock i’,每个 ShuffleBlock 被称为 FileSegment。下一个 stage 的 reducer 只需要 fetch 整个 ShuffleFile 就行了。这样,每个 worker 持有的文件数降为 cores * R。FileConsolidation 功能可以通过spark.shuffle.consolidateFiles=true来开启。
Shuffle read
先看一张包含 ShuffleDependency 的物理执行图,来自 reduceByKey: 
很自然地,要计算 ShuffleRDD 中的数据,必须先把 MapPartitionsRDD 中的数据 fetch 过来。那么问题就来了:
在什么时候 fetch,parent stage 中的一个 ShuffleMapTask 执行完还是等全部 ShuffleMapTasks 执行完?
边 fetch 边处理还是一次性 fetch 完再处理?
fetch 来的数据存放到哪里?
怎么获得要 fetch 的数据的存放位置?
解决问题:
在什么时候 fetch?当 parent stage 的所有 ShuffleMapTasks 结束后再 fetch。理论上讲,一个 ShuffleMapTask 结束后就可以 fetch,但是为了迎合 stage 的概念(即一个 stage 如果其 parent stages 没有执行完,自己是不能被提交执行的),还是选择全部 ShuffleMapTasks 执行完再去 fetch。因为 fetch 来的 FileSegments 要先在内存做缓冲,所以一次 fetch 的 FileSegments 总大小不能太大。Spark 规定这个缓冲界限不能超过 spark.reducer.maxMbInFlight,这里用 softBuffer 表示,默认大小为 48MB。一个 softBuffer 里面一般包含多个 FileSegment,但如果某个 FileSegment 特别大的话,这一个就可以填满甚至超过 softBuffer 的界限。
边 fetch 边处理还是一次性 fetch 完再处理?边 fetch 边处理。本质上,MapReduce shuffle 阶段就是边 fetch 边使用 combine() 进行处理,只是 combine() 处理的是部分数据。MapReduce 为了让进入 reduce() 的 records 有序,必须等到全部数据都 shuffle-sort 后再开始 reduce()。因为 Spark 不要求 shuffle 后的数据全局有序,因此没必要等到全部数据 shuffle 完成后再处理。那么如何实现边 shuffle 边处理,而且流入的 records 是无序的?答案是使用可以 aggregate 的数据结构,比如 HashMap。每 shuffle 得到(从缓冲的 FileSegment 中 deserialize 出来)一个
4.akka
消息队列系统
在spark中 作为消息系统为master,worker,driver等通信
sender ! RegisteredWorker(masterUrl, masterWebUiUrl)
// Master to Worker
case class RegisteredWorker(masterUrl: String, masterWebUiUrl: String) extends DeployMessage 
http://hongbinzuo.github.io/2014/12/16/Akka-Tutorial-with-Code-Conncurrency-and-Fault-Tolerance/
5.tachyon
分布式文件系统,介于内存和磁盘之间的存储介质
http://tachyon-project.org/index.html
架构图: 
6. netty
目前在spark中主要作为spark shuffle处理后 从各个解决拉取shuffle数据
7.安装和启动
. 配置SPARK_HOME/conf/spark-env.sh文件 
. 配置SPARK_HOME/conf/slaves文件 
. 启动spark&验证 ![]()
尊重原创,未经允许不得转载:http://blog.csdn.net/stark_summer/article/details/45917603