java集合
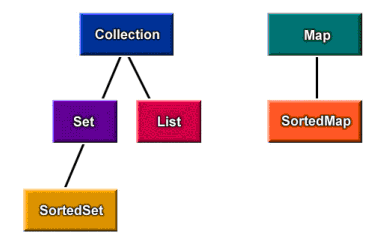
集合包:Collection(存放单个对象),map(key-value)
collection:List(支持放入重复对象),set(不能有重复对象)
List接口常见的类:ArrayList,LinkedList,vector,stack
set接口常见类:treeset,hashset
ma接口常见类:treemap,hashmap
java.util.Collection [I]
+--java.util.List [I]
+--java.util.ArrayList [C]
+--java.util.LinkedList [C]
+--java.util.Vector [C]
+--java.util.Stack [C]
+--java.util.Set [I]
+--java.util.HashSet [C]
+--java.util.SortedSet [I]
+--java.util.TreeSet [C]
java.util.Map [I]
+--java.util.SortedMap [I]
+--java.util.TreeMap [C]
+--java.util.Hashtable [C]
+--java.util.HashMap [C]
+--java.util.LinkedHashMap [C]
+--java.util.WeakHashMap [C]
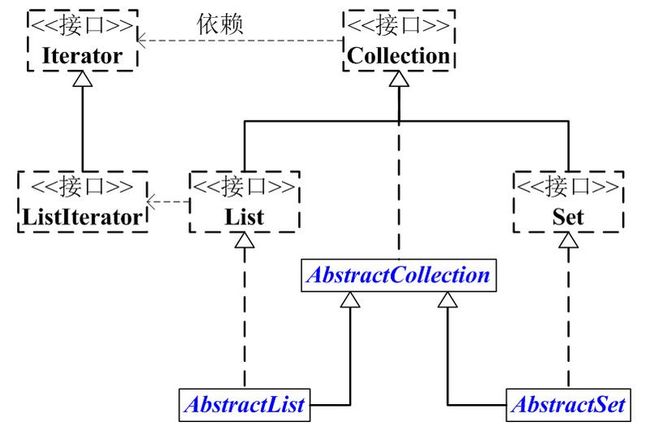
接口:
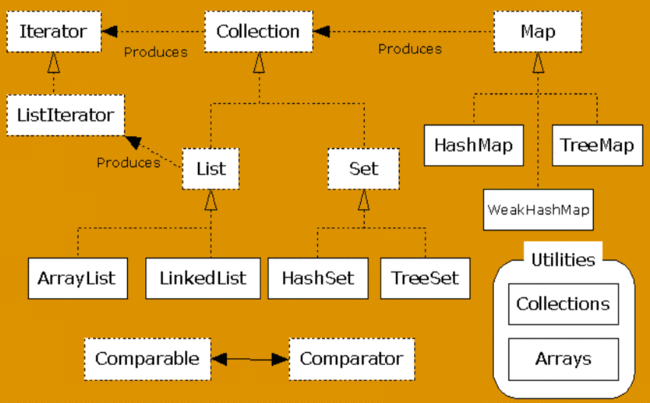
总体结构
ArrayList
采用数组方式存储对象,无容量的限制
插入对象:已有元素添加1,如果超过数组容量
(01) ArrayList 实际上是通过一个数组去保存数据的。当我们构造ArrayList时;若使用默认构造函数,则ArrayList的默认容量大小是10。
(02) 当ArrayList容量不足以容纳全部元素时,ArrayList会重新设置容量:新的容量=“(原始容量x3)/2 + 1”。
删除元素不减小数组的容量(减小可以调用trimToSize)
非线程安全
http://git.oschina.net/memristor/javalab/blob/master/javalab/src/collection/list/ArrayListExample.java
LinkedeList
双向链表机制,集合每个元素都知道其前一个元素与后一个元素的位置。
插入元素,切换相应元素的前后指针引用,查找需要遍历链表,删除先遍历链表找到删除元素然后删除元素
非线程安全
http://git.oschina.net/memristor/javalab/blob/master/javalab/src/collection/list/LinkedListExample.java
Vector
基于数组实现,默认创建10个元素数组
add方法加了synchronize,线程安全,扩大数组的方法与ArrayList也不同。如果capcacityIncrement大于1,则扩充为现有数组size+capacityIncrement,如果capcacityIncrement小于0,扩充为现有大小的两倍,容量控制策略更加可控
indexof,remove,get都加了synchronized关键字
线程安全
Stack
实现基于Vector,后进先出,push,pop,peek
hashset
set中不允许元素重复,采用基于hashmap实现
hashset构造函数要先创建一个hashmap对象,add方法调用hashmap的put(object,object)完成操作,将需要增加的元素作为map的key,value则传入一个之前已经创建的对象
其他都是调用hashmap的接口
非线程安全
TreeSet
treeset与hashset的区别是treeset提供对排序的支持,基于TreeMap实现
非线程安全
hashMap
将loadFactor设为0.75, threshold设置为12,创建一个大小为16的Entry对象数组
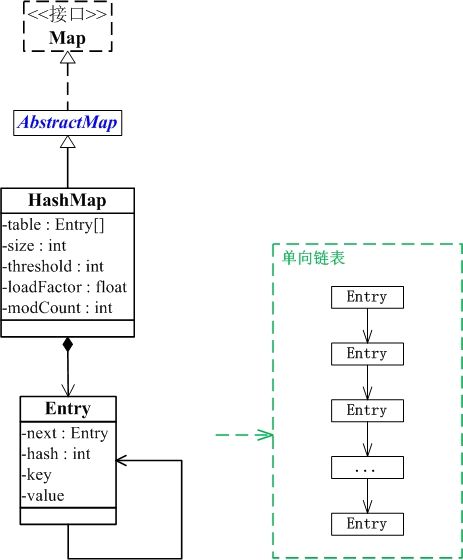
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
size是HashMap的大小,它是HashMap保存的键值对的数量。
threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值="容量*加载因子",当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
loadFactor就是加载因子。
HashMap的构造函数
http://www.cnblogs.com/skywang12345/p/3310835.html
// 默认构造函数。
public HashMap() {
// 设置“加载因子”
this.loadFactor = DEFAULT_LOAD_FACTOR;
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
// 创建Entry数组,用来保存数据
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
// 指定“容量大小”和“加载因子”的构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// HashMap的最大容量只能是MAXIMUM_CAPACITY
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
// 设置“加载因子”
this.loadFactor = loadFactor;
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(capacity * loadFactor);
// 创建Entry数组,用来保存数据
table = new Entry[capacity];
init();
}
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 包含“子Map”的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
// 将m中的全部元素逐个添加到HashMap中
putAllForCreate(m);
}
数组存储的是一个链表,当有冲突的时候采用链表的方式
非线程安全的
TreeMap
支持排序的map实现,基于红黑树实现,非线程安全
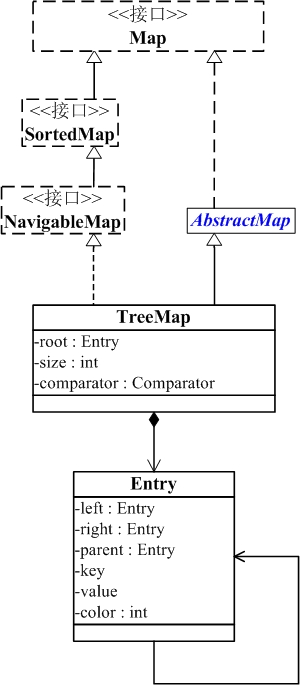
(01) TreeMap实现继承于AbstractMap,并且实现了NavigableMap接口。
(02) TreeMap的本质是R-B Tree(红黑树),它包含几个重要的成员变量: root, size, comparator。
root 是红黑数的根节点。它是Entry类型,Entry是红黑数的节点,它包含了红黑数的6个基本组成成分:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)。Entry节点根据key进行排序,Entry节点包含的内容为value。
红黑数排序时,根据Entry中的key进行排序;Entry中的key比较大小是根据比较器comparator来进行判断的。
size是红黑数中节点的个数。
WeakHashMap
http://www.cnblogs.com/skywang12345/p/3311092.html
和HashMap一样,WeakHashMap 也是一个散列表,它存储的内容也是键值对(key-value)映射,而且键和值都可以是null。不过WeakHashMap的键是“弱键”。在 WeakHashMap 中,当某个键不再正常使用时,会被从WeakHashMap中被自动移除。更精确地说,对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。某个键被终止时,它对应的键值对也就从映射中有效地移除了。
这个“弱键”的原理呢?大致上就是,通过WeakReference和ReferenceQueue实现的。 WeakHashMap的key是“弱键”,即是WeakReference类型的;ReferenceQueue是一个队列,它会保存被GC回收的“弱键”。实现步骤是:
(01) 新建WeakHashMap,将“键值对”添加到WeakHashMap中。
实际上,WeakHashMap是通过数组table保存Entry(键值对);每一个Entry实际上是一个单向链表,即Entry是键值对链表。
(02) 当某“弱键”不再被其它对象引用,并被GC回收时。在GC回收该“弱键”时,这个“弱键”也同时会被添加到ReferenceQueue(queue)队列中。
(03) 当下一次我们需要操作WeakHashMap时,会先同步table和queue。table中保存了全部的键值对,而queue中保存被GC回收的键值对;同步它们,就是删除table中被GC回收的键值对。
这就是“弱键”如何被自动从WeakHashMap中删除的步骤了。

(01) WeakHashMap继承于AbstractMap,并且实现了Map接口。
(02) WeakHashMap是哈希表,但是它的键是"弱键"。WeakHashMap中保护几个重要的成员变量:table, size, threshold, loadFactor, modCount, queue。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
size是Hashtable的大小,它是Hashtable保存的键值对的数量。
threshold是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的
queue保存的是“已被GC清除”的“弱引用的键”。
“弱键”是一个“弱引用(WeakReference)”,在Java中,WeakReference和ReferenceQueue 是联合使用的。在WeakHashMap中亦是如此:如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。 接着,WeakHashMap会根据“引用队列”,来删除“WeakHashMap中已被GC回收的‘弱键’对应的键值对”。
http://git.oschina.net/memristor/javalab/blob/master/javalab/src/collection/Test/WeakHashMapTest.java
HashTable
和HashMap一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射。
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。此外,Hashtable中的映射不是有序的。
hashmap与hashtable
执行效率与线程安全:A.HashMap是非线程安全的,是Hashtable的轻量级实现,效率较高;B.Hashtable是线程安全的,效率较低
put方法对key和value的要求不同:A.HashMap允许Entry的key或value为null B.Hashtable不允许Entry的key或value为null,否则出现NullPointerException
有无contains方法 A.HashMap没有contains方法 B.Hashtable有contains方法
对集合操作的工具类
Java提供了java.util.Collections,以及java.util.Arrays类简化对集合的操作
java.util.Collections主要提供一些static方法用来操作或创建Collection,Map等集合。
java.util.Arrays主要提供static方法对数组进行操作。。
fail-fast机制
fail-fast 机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。
package collection.Test;
import java.util.*;
import java.util.concurrent.*;
/*
* @desc java集合中Fast-Fail的测试程序。
*
* fast-fail事件产生的条件:当多个线程对Collection进行操作时,若其中某一个线程通过iterator去遍历集合时,该集合的内容被其他线程所改变;则会抛出ConcurrentModificationException异常。
* fast-fail解决办法:通过util.concurrent集合包下的相应类去处理,则不会产生fast-fail事件。
*
* 本例中,分别测试ArrayList和CopyOnWriteArrayList这两种情况。ArrayList会产生fast-fail事件,而CopyOnWriteArrayList不会产生fast-fail事件。
* (01) 使用ArrayList时,会产生fast-fail事件,抛出ConcurrentModificationException异常;定义如下:
* private static List<String> list = new ArrayList<String>();
* (02) 使用时CopyOnWriteArrayList,不会产生fast-fail事件;定义如下:
* private static List<String> list = new CopyOnWriteArrayList<String>();
*
* @author skywang
*/
public class FastFailTest {
private static List<String> list = new ArrayList<String>();
//private static List<String> list = new CopyOnWriteArrayList<String>();
public static void main(String[] args) {
// 同时启动两个线程对list进行操作!
new ThreadOne().start();
new ThreadTwo().start();
}
private static void printAll() {
System.out.println("");
String value = null;
Iterator iter = list.iterator();
while(iter.hasNext()) {
value = (String)iter.next();
System.out.print(value+", ");
}
}
/**
* 向list中依次添加0,1,2,3,4,5,每添加一个数之后,就通过printAll()遍历整个list
*/
private static class ThreadOne extends Thread {
public void run() {
int i = 0;
while (i<6) {
list.add(String.valueOf(i));
printAll();
i++;
}
}
}
/**
* 向list中依次添加10,11,12,13,14,15,每添加一个数之后,就通过printAll()遍历整个list
*/
private static class ThreadTwo extends Thread {
public void run() {
int i = 10;
while (i<16) {
list.add(String.valueOf(i));
printAll();
i++;
}
}
}
}
0,
0, 10,
0, 10, 11,
0, 10, 11, 12,
0, 10, 11, 12, 13,
0, 10, 11, 12, 13, 14, Exception in thread "Thread-0"
0, 10, 11, 12, 13, 14, 15, java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:859)
at java.util.ArrayList$Itr.next(ArrayList.java:831)
at collection.Test.FastFailTest.printAll(FastFailTest.java:37)
at collection.Test.FastFailTest.access$1(FastFailTest.java:31)
at collection.Test.FastFailTest$ThreadOne.run(FastFailTest.java:50)
结果说明:
(01) FastFailTest中通过 new ThreadOne().start() 和 new ThreadTwo().start() 同时启动两个线程去操作list。
ThreadOne线程:向list中依次添加0,1,2,3,4,5。每添加一个数之后,就通过printAll()遍历整个list。
ThreadTwo线程:向list中依次添加10,11,12,13,14,15。每添加一个数之后,就通过printAll()遍历整个list。
(02) 当某一个线程遍历list的过程中,list的内容被另外一个线程所改变了;就会抛出ConcurrentModificationException异常,产生fail-fast事件。
fail-fast机制,是一种错误检测机制。它只能被用来检测错误,因为JDK并不保证fail-fast机制一定会发生。若在多线程环境下使用fail-fast机制的集合,建议使用“java.util.concurrent包下的类”去取代“java.util包下的类”。所以,本例中只需要将ArrayList替换成java.util.concurrent包下对应的类即可。
(01) 和ArrayList继承于AbstractList不同,CopyOnWriteArrayList没有继承于AbstractList,它仅仅只是实现了List接口。
(02) ArrayList的iterator()函数返回的Iterator是在AbstractList中实现的;而CopyOnWriteArrayList是自己实现Iterator。
(03) ArrayList的Iterator实现类中调用next()时,会“调用checkForComodification()比较‘expectedModCount’和‘modCount’的大小”;但是,CopyOnWriteArrayList的Iterator实现类中,没有所谓的checkForComodification(),更不会抛出ConcurrentModificationException异常!
Iterator和Enumeration
package java.util;public interface Enumeration<E> {
boolean hasMoreElements();
E nextElement();
}
public interface Iterator<E> {
boolean hasNext();
E next();
void remove();
}
(01) 函数接口不同
Enumeration只有2个函数接口。通过Enumeration,我们只能读取集合的数据,而不能对数据进行修改。
Iterator只有3个函数接口。Iterator除了能读取集合的数据之外,也能数据进行删除操作。
(02) Iterator支持fail-fast机制,而Enumeration不支持。
Enumeration 是JDK 1.0添加的接口。使用到它的函数包括Vector、Hashtable等类,这些类都是JDK 1.0中加入的,Enumeration存在的目的就是为它们提供遍历接口。Enumeration本身并没有支持同步,而在Vector、Hashtable实现Enumeration时,添加了同步。而Iterator 是JDK 1.2才添加的接口,它也是为了HashMap、ArrayList等集合提供遍历接口。Iterator是支持fail-fast机制的:当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件,因此Enumeration 比 Iterator 的遍历速度更快