linux的一些命令 -查看cc攻击-网口ip统计等
Linux和UNIX上的数据库监控工具包括监控CPU、内存、磁盘、网络、安全性和用户的监控工具。下面罗列了我们找到的有用工具及其简单描述。
ps 显示系统上运行的进程列表
top 显示根据CPU使用率排序的活动进程
vmstat 显示内存、分页、块传输和CPU活动的相关信息
uptime 显示系统运行了多长时间。并显示了用户登录数量,以及在1分钟、5分钟、15分钟的系统平均负荷量
free 显示内存使用率
iostat 显示平均磁盘活动和处理器负载情况
sar 显示系统活动报告。允许你收集和报告各种系统活动
pmap 显示各种进程分别占用内存的情况
mpstat 显示多处理器的CPU使用率
netstat 显示网络活动的相关信息
ifconfig 显示系统中网络接口的列表,其中包括每个网络接口的状态和设置
cron 可以让你安排进程执行的子系统。你可以安排这些使用程序的执行,故可以随着时间的推移定期收集统计信息,并可以在特定时间(如在高负载或低负载 间)查看统计信息
查看所有80端口的连接数
- netstat -nat|grep -i '80'|wc -l
- 对连接的IP按连接数量进行排序
- netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -n
- 查看TCP连接状态
- netstat -nat |awk '{print $6}'|sort|uniq -c|sort -rn
- netstat -n | awk '/^tcp/ {++S[$NF]};END {for(a in S) print a, S[a]}'
- netstat -n | awk '/^tcp/ {++state[$NF]}; END {for(key in state) print key,"\t",state[key]}'
- netstat -n | awk '/^tcp/ {++arr[$NF]};END {for(k in arr) print k,"\t",arr[k]}'
- netstat -n |awk '/^tcp/ {print $NF}'|sort|uniq -c|sort -rn
- netstat -ant | awk '{print $NF}' | grep -v '[a-z]' | sort | uniq -c
- 查看80端口连接数最多的20个IP
- netstat -anlp|grep 80|grep tcp|awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort -nr|head -n20
- netstat -ant |awk '/:80/{split($5,ip,":");++A[ip[1]]}END{for(i in A) print A,i}' |sort -rn|head -n20
- 用tcpdump嗅探80端口的访问看看谁最高
- tcpdump -i eth0 -tnn dst port 80 -c 1000 | awk -F"." '{print $1″."$2″."$3″."$4}' | sort | uniq -c | sort -nr |head -20
- 查找较多time_wait连接
- netstat -n|grep TIME_WAIT|awk '{print $5}'|sort|uniq -c|sort -rn|head -n20
- 查找较多的SYN连接
- netstat -an | grep SYN | awk '{print $5}' | awk -F: '{print $1}' | sort | uniq -c | sort -nr | more
================================
防范DDOS攻击脚本
#防止SYN攻击 轻量级预防
iptables -N syn-flood
iptables -A INPUT -p tcp –syn -j syn-flood
iptables -I syn-flood -p tcp -m limit –limit 3/s –limit-burst 6 -j RETURN
iptables -A syn-flood -j REJECT
#防止DOS太多连接进来,可以允许外网网卡每个IP最多15个初始连接,超过的丢弃
iptables -A INPUT -i eth0 -p tcp –syn -m connlimit –connlimit-above 15 -j DROP
iptables -A INPUT -p tcp -m state –state ESTABLISHED,RELATED -j ACCEPT
#用Iptables抵御DDOS (参数与上相同)
iptables -A INPUT -p tcp --syn -m limit --limit 12/s --limit-burst 24 -j ACCEPT
iptables -A FORWARD -p tcp --syn -m limit --limit 1/s -j ACCEPT
##########################################################
防范CC攻击
当apache站点受到严重的cc攻击,我们可以用iptables来防止web服务器被CC攻击,实现自动屏蔽IP的功能。
1.系统要求
(1)LINUX 内核版本:2.6.9-42ELsmp或2.6.9-55ELsmp(其它内核版本需要重新编译内核,比较麻烦,但是也是可以实现的)。
(2)iptables版本:1.3.7
2. 安装
安装iptables1.3.7和系统内核版本对应的内核模块kernel-smp-modules-connlimit
3. 配置相应的iptables规则
示例如下:
(1)控制单个IP的最大并发连接数
- iptables -I INPUT -p tcp --dport 80 -m connlimit --connlimit-above 50 -j REJECT
#默认iptables模块不包含connlimit,需要自己单独编译加载,请参考该地址
http://sookk8.blog.51cto.com/455855/280372 不编译内核加载connlimit模块
(2)控制单个IP在一定的时间(比如60秒)内允许新建立的连接数
- iptables -A INPUT -p tcp --dport 80 -m recent --name BAD_HTTP_ACCESS --update --seconds 60 --hitcount 30 -j REJECT iptables -A INPUT -p tcp --dport 80 -m recent --name BAD_HTTP_ACCESS --set -j ACCEPT
#单个IP在60秒内只允许最多新建30个连接
4. 验证
(1)工具:flood_connect.c(用来模拟攻击)
(2)查看效果:
使用
- watch 'netstat -an | grep:21 | grep<模拟攻击客户机的IP>| wc -l'
实时查看模拟攻击客户机建立起来的连接数,
使用
- watch 'iptables -L -n -v | \grep<模拟攻击客户机的IP>'
查看模拟攻击客户机被 DROP 的数据包数。
5.注意
为了增强iptables防止CC攻击的能力,最好调整一下ipt_recent的参数如下:
- #cat/etc/modprobe.conf options ipt_recent ip_list_tot=1000 ip_pkt_list_tot=60
#记录1000个IP地址,每个地址记录60个数据包 #modprobe ipt_recent
===========================
Nginx 版本信息:
nginx version: nginx/0.8.53
Nginx日志配置项:
- access_log /data0/logs/access.log combined;
Nginx日志格式:
- $remote_addr – $remote_user [$time_local] $request $status $apache_bytes_sent $http_referer $http_user_agent
- 127.0.0.1 - - [24/Mar/2011:12:45:07 +0800] "GET /fcgi_bin/xxx.fcgi?id=xxx HTTP/1.0" 200 160 "-" "Mozilla/4.0"
通过日志查看当天访问页面排前10的url:
- #>cat access.log | grep "24/Mar/2011" | awk '{print $7}' | sort | uniq -c | sort -nr | head -n 10
通过日志查看当天ip连接数,统计ip地址的总连接数
- #>cat access.log | grep "24/Mar/2011" | awk '{print $1}' | sort | uniq -c | sort –nr
- 38 112.97.192.16
- 20 117.136.31.145
- 19 112.97.192.31
- 3 61.156.31.20
- 2 209.213.40.6
- 1 222.76.85.28
通过日志查看当天访问次数最多的10个IP ,只需要在上一个命令后加上head命令
- #>cat access.log | grep "24/Mar/2011" |awk '{print $3}'|sort |uniq -c|sort -nr|head –n 10
- 38 112.97.192.16
- 20 117.136.31.145
- 19 112.97.192.31
- 3 61.156.31.20
- 2 209.213.40.6
- 1 222.76.85.28
通过日志查看当天访问次数最多的10个IP
- #>awk '{print $1}' access.log |sort |uniq -c|sort -nr|head
- 10680 10.0.21.17
- 1702 10.0.20.167
- 823 10.0.20.51
- 504 10.0.20.255
- 215 58.60.188.61
- 192 183.17.161.216
- 38 112.97.192.16
- 20 117.136.31.145
- 19 112.97.192.31
- 6 113.106.88.10
通过日志查看当天指定ip访问次数过的url和访问次数:
- #>cat access.log | grep "10.0.21.17" | awk '{print $7}' | sort | uniq -c
- cat access.log | grep "10.0.21.17" | awk '{print $7}' | uniq -c | sort -nr | head -n 20
- 224 /test/themes/default/img/logo_index.gif
- 224 /test/themes/default/img/bg_index_head.jpg
- 224 /test/themes/default/img/bg_index.gif
- 219 /test/vc.php
- 219 /
- 213 /misc/js/global.js
- 211 /misc/jsext/popup.ext.js
- 211 /misc/js/common.js
- 210 /sladmin/home
- 197 /misc/js/flib.js
通过日志查看当天访问次数最多的时间段
- #>awk '{print $4}' access.log | grep "24/Mar/2011" |cut -c 14-18|sort|uniq -c|sort -nr|head
- 24 16:49
- 19 16:17
- 16 16:51
- 11 16:48
- 4 16:50
- 3 16:52
- 1 20:09
- 1 20:05
- 1 20:03
- 1 19:55
rails日志查询ip访问的排行榜
- cat production.log | grep '2010-10-31' | awk '{print $4}'| sort -u | wc
-----------------
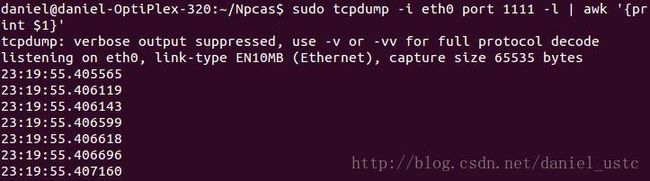
持续的监视某块网卡的数据流量
其中 eht0 对应你想要监视的网卡 bytes 对应中文版系统的“字节”
1 代表 1秒钟刷新一次
- watch -n 1 "/sbin/ifconfig eth0 | grep bytes"
------------------
# sar -n DEV -u 1 10
看看当前网络流量
# iostat -t 1 10
看看当前硬盘读写速度
----------------------
查看文件大小
du -h --max-depth=1 /路径
1 删除0字节文件
find-type f -size 0 -exec rm -rf {} \;
2 查看进程
按内存从大到小排列
ps -e -o "%C : %p : %z : %a"|sort -k5 -nr
3 按cpu利用率从大到小排列
ps -e -o "%C : %p : %z : %a"|sort -nr
4 打印说cache里的URL
grep -r -a jpg /data/cache/* | strings | grep "http:" |awk-F'http:' '{print "http:"$2;}'
5 查看http的并发请求数及其TCP连接状态:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
6 sed-i '/Root/s/no/yes/' /etc/ssh/sshd_config sed在这个文里Root的一行,匹配Root一行,将no替换成yes.
7 如何杀掉mysql进程:
ps aux|grep mysql|grep -v grep|awk '{print $2}'|xargs kill -9 (从中了解到awk的用途)
pgrep mysql |xargs kill -9
killall -TERM mysqld
kill -9 `cat /usr/local/apache2/logs/httpd.pid` 试试查杀进程PID
8 显示运行3级别开启的服务:
ls /etc/rc3.d/S* |cut -c 15- (从中了解到cut的用途,截取数据)
9 如何在编写SHELL显示多个信息,用EOF
cat << EOF
+--------------------------------------------------------------+
| === Welcome to Tunoff services === |
+--------------------------------------------------------------+
EOF
10 for 的巧用(如给mysql建软链接)
cd /usr/local/mysql/bin
for i in *
do ln /usr/local/mysql/bin/$i /usr/bin/$i
done
11 取IP地址:
ifconfig eth0 |grep "inet addr:" |awk '{print $2}'|cut -c 6- 或者
ifconfig | grep 'inet addr:'| grep -v '127.0.0.1' | cut -d: -f2 | awk '{ print $1}'
12 内存的大小:
free -m |grep "Mem" | awk '{print $2}'
13
netstat -an -t | grep ":80" | grep ESTABLISHED | awk '{printf "%s %s\n",$5,$6}' | sort
14 查看Apache的并发请求数及其TCP连接状态:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
15 因为同事要统计一下服务器下面所有的jpg的文件的大小,写了个shell给他来统计.原来用xargs实现,但他一次处理一部分,搞的有多个总和....,下面的命令就能解决啦.
find / -name *.jpg -exec wc -c {} \;|awk '{print $1}'|awk '{a+=$1}END{print a}'
CPU的数量(多核算多个CPU,cat /proc/cpuinfo |grep -c processor)越多,系统负载越低,每秒能处理的请求数也越多。
-------------------------------------------------------------------------------
16 CPU负载 # cat /proc/loadavg
检查前三个输出值是否超过了系统逻辑CPU的4倍。
18 CPU负载 #mpstat 1 1
检查%idle是否过低(比如小于5%)
19 内存空间 # free
检查free值是否过低 也可以用 # cat /proc/meminfo
20 swap空间 # free
检查swap used值是否过高 如果swap used值过高,进一步检查swap动作是否频繁:
# vmstat 1 5
观察si和so值是否较大
21 磁盘空间 # df -h
检查是否有分区使用率(Use%)过高(比如超过90%) 如发现某个分区空间接近用尽,可以进入该分区的挂载点,用以下命令找出占用空间最多的文件或目录:
# du -cks * | sort -rn | head -n 10
22 磁盘I/O负载 # iostat -x 1 2
检查I/O使用率(%util)是否超过100%
23 网络负载 # sar -n DEV
检查网络流量(rxbyt/s, txbyt/s)是否过高
24 网络错误 # netstat -i
检查是否有网络错误(drop fifo colls carrier) 也可以用命令:# cat /proc/net/dev
25 网络连接数目 # netstat -an | grep -E “^(tcp)” | cut -c 68- | sort | uniq -c | sort -n
26 进程总数 # ps aux | wc -l
检查进程个数是否正常 (比如超过250)
27 可运行进程数目 # vmwtat 1 5
列给出的是可运行进程的数目,检查其是否超过系统逻辑CPU的4倍
28 进程 # top -id 1
观察是否有异常进程出现
29 网络状态 检查DNS, 网关等是否可以正常连通
30 用户 # who | wc -l
检查登录用户是否过多 (比如超过50个) 也可以用命令:# uptime
31 系统日志 # cat /var/log/rflogview/*errors
检查是否有异常错误记录 也可以搜寻一些异常关键字,例如:
# grep -i error /var/log/messages
# grep -i fail /var/log/messages
# egrep -i 'error|warn' /var/log/messages 查看系统异常
32 核心日志 # dmesg
检查是否有异常错误记录
33 系统时间 # date
检查系统时间是否正确
34 打开文件数目 # lsof | wc -l
检查打开文件总数是否过多
35 日志 # logwatch –print 配置/etc/log.d/logwatch.conf,将 Mailto 设置为自己的email 地址,启动mail服务 (sendmail或者postfix),这样就可以每天收到日志报告了。
缺省logwatch只报告昨天的日志,可以用# logwatch –print –range all 获得所有的日志分析结果。
可以用# logwatch –print –detail high 获得更具体的日志分析结果(而不仅仅是出错日志)。
36 杀掉80端口相关的进程
lsof -i :80|grep -v "PID"|awk '{print "kill -9",$2}'|sh
37 清除僵死进程。
ps -eal | awk '{ if ($2 == "Z") {print $4}}' | kill -9
38 tcpdump 抓包 ,用来防止80端口被人攻击时可以分析数据
# tcpdump -c 10000 -i eth0 -n dst port 80 > /root/pkts
39 然后检查IP的重复数 并从小到大排序 注意 "-t\ +0" 中间是两个空格
# less pkts | awk {'printf $3"\n"'} | cut -d. -f 1-4 | sort | uniq -c | awk {'printf $1" "$2"\n"'} | sort -n -t\ +0
40 查看有多少个活动的php-cgi进程
netstat -anp | grep php-cgi | grep ^tcp | wc -l
41 利用iptables对应简单攻击
netstat -an | grep -v LISTEN | awk ‘{print $5}’ |grep -v 127.0.0.1|grep -v 本机ip|sed “s/::ffff://g”|awk ‘BEGIN { FS=”:” } { Num[$1]++ } END { for(i in Num) if(Num>8) { print i} }’ |grep ‘[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}’| xargs -i[] iptables -I INPUT -s [] -j DROP
Num>8部分设定值为阀值,这条句子会自动将netstat -an 中查到的来自同一IP的超过一定量的连接的列入禁止范围。本机ip改成你的服务器的ip地址
选择性的删除某些行:
# 删除所有空白行 (类似于 "grep '.' ")
awk NF
awk '/./'
# 删除重复连续的行 (模拟 "uniq")
awk 'a !~ $0; {a=$0}'
# 删除重复的、非连续的行
awk '! a[$0]++' # 最简练
awk '!($0 in a) {a[$0];print}' # 最有效
查询系统状态的指令集:
cat 文件名 一屏查看文件内容
more 文件名 分页查看文件内容
less 文件名 可控分页查看文件内容
grep -l -r 字符串 路径 显示包含字符串的文件名
grep -L -r 字符串 路径 显示不包含字符串的文件名
lsof -p 进程号(例如:lsof -p 2428)查看进程打开的文件
lsof abc.txt 显示开启文件abc.txt的进程
lsof -i :22 显示22端口现在运行什么程序
lsof -c nsd 显示nsd进程现在打开的文件
nohup 程序 & 在后台运行程序,退出登录后,并不结束程序
strace -f -F -o outfile <cmd> 详细显示程序的运行信息
arping IP地址 根据IP查网卡地址
nmblookup -A IP地址 根据IP查电脑名
linux删除特殊文件名的文件
假设Linux系统中有一个文件名叫“-ee”,如果我们想对它进行操作,例如要删除它,按照一般的删除方法在命令行中输入rm -ee命令,界面会提示我们是“无效选项”(invalid option),原来由于文件名的第一个字符为“-”,Linux把文件名当作选项了,我们可以使用“–”符号来解决这个问题,输入“rm — -ee”命令便可顺利删除名为“-ee”的文件。如果是其他特殊字符的话可以在特殊字符前加一个“”符号,或者用双引号把整个文件名括起来。
如,/usr/lcoal/目录下有个--exclude 文件,通过命令
rm -- --exclude
删除此文件
一句话快速查找PHP木马的方法
find ./ -name "*.php" -type f -print0|xargs -0 egrep "(phpspy|c99sh|milw0rm|eval\(base64_decode|eval\(gzinflate\(base64_decode|eval\(gzinflate\(str_rot13\(base64_decode|spider_bc)"|awk -F: '{print $1}'|sort|uniq
如何删去重复行并保持顺序不变?
awk '{ if (!seen[$0]++) { print $0; } }' $file_path
perl -lne 'print unless $seen{$_}++ ' $file_path
--------------------------------------------系统连接状态篇:
1.查看TCP连接状态
netstat -nat |awk '{print $6}'|sort|uniq -c|sort -rn
netstat -n | awk '/^tcp/ {++S[$NF]};END {for(a in S) print a, S[a]}' 或
netstat -n | awk '/^tcp/ {++state[$NF]}; END {for(key in state) print key,"\t",state[key]}'
netstat -n | awk '/^tcp/ {++arr[$NF]};END {for(k in arr) print k,"\t",arr[k]}'
netstat -n |awk '/^tcp/ {print $NF}'|sort|uniq -c|sort -rn
netstat -ant | awk '{print $NF}' | grep -v '[a-z]' | sort | uniq -c
2.查找请求数请20个IP(常用于查找攻来源):
netstat -anlp|grep 80|grep tcp|awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort -nr|head -n20
netstat -ant |awk '/:80/{split($5,ip,":");++A[ip[1]]}END{for(i in A) print A[i],i}' |sort -rn|head -n20
3.用tcpdump嗅探80端口的访问看看谁最高
tcpdump -i eth0 -tnn dst port 80 -c 1000 | awk -F"." '{print $1″."$2″."$3″."$4}' | sort | uniq -c | sort -nr |head -20
4.查找较多time_wait连接
netstat -n|grep TIME_WAIT|awk '{print $5}'|sort|uniq -c|sort -rn|head -n20
5.找查较多的SYN连接
netstat -an | grep SYN | awk '{print $5}' | awk -F: '{print $1}' | sort | uniq -c | sort -nr | more
6.根据端口列进程
netstat -ntlp | grep 80 | awk '{print $7}' | cut -d/ -f1
------------------------------ 网站日志分析篇1(Apache):
1.获得访问前10位的ip地址
cat access.log|awk '{print $1}'|sort|uniq -c|sort -nr|head -10
cat access.log|awk '{counts[$(11)]+=1}; END {for(url in counts) print counts[url], url}'
2.访问次数最多的文件或页面,取前20
cat access.log|awk '{print $11}'|sort|uniq -c|sort -nr|head -20
3.列出传输最大的几个exe文件(分析下载站的时候常用)
cat access.log |awk '($7~/\.exe/){print $10 " " $1 " " $4 " " $7}'|sort -nr|head -20
4.列出输出大于200000byte(约200kb)的exe文件以及对应文件发生次数
cat access.log |awk '($10 > 200000 && $7~/\.exe/){print $7}'|sort -n|uniq -c|sort -nr|head -100
5.如果日志最后一列记录的是页面文件传输时间,则有列出到客户端最耗时的页面
cat access.log |awk '($7~/\.php/){print $NF " " $1 " " $4 " " $7}'|sort -nr|head -100
6.列出最最耗时的页面(超过60秒的)的以及对应页面发生次数
cat access.log |awk '($NF > 60 && $7~/\.php/){print $7}'|sort -n|uniq -c|sort -nr|head -100
7.列出传输时间超过 30 秒的文件
cat access.log |awk '($NF > 30){print $7}'|sort -n|uniq -c|sort -nr|head -20
8.统计网站流量(G)
cat access.log |awk '{sum+=$10} END {print sum/1024/1024/1024}'
9.统计404的连接
awk '($9 ~/404/)' access.log | awk '{print $9,$7}' | sort
10. 统计http status.
cat access.log |awk '{counts[$(9)]+=1}; END {for(code in counts) print code, counts[code]}'
cat access.log |awk '{print $9}'|sort|uniq -c|sort -rn
10.蜘蛛分析
查看是哪些蜘蛛在抓取内容。
/usr/sbin/tcpdump -i eth0 -l -s 0 -w - dst port 80 | strings | grep -i user-agent | grep -i -E 'bot|crawler|slurp|spider'
--------------------------------------网站日分析2(Squid篇)
2.按域统计流量
zcat squid_access.log.tar.gz| awk '{print $10,$7}' |awk 'BEGIN{FS="[ /]"}{trfc[$4]+=$1}END{for(domain in trfc){printf "%s\t%d\n",domain,trfc[domain]}}'
效率更高的perl版本请到此下载:http://docs.linuxtone.org/soft/tools/tr.pl
------------------------------ 数据库篇
1.查看数据库执行的sql
/usr/sbin/tcpdump -i eth0 -s 0 -l -w - dst port 3306 | strings | egrep -i 'SELECT|UPDATE|DELETE|INSERT|SET|COMMIT|ROLLBACK|CREATE|DROP|ALTER|CALL'
---------------------------------- 系统Debug分析篇
1.调试命令
strace -p pid
2.跟踪指定进程的PID
gdb -p pid
1.按内存从大到小排列进程:
ps -eo "%C : %p : %z : %a"|sort -k5 -nr
2.查看当前有哪些进程;查看进程打开的文件:
ps -A ;lsof -p PID
3.获取当前IP地址(从中学习grep,awk,cut的作用)
ifconfig eth0 |grep "inet addr:" |awk '{print $2}'|cut -c 6-
4.统计每个单词出现的频率,并排序
awk '{arr[$1]+=1 }END{for(i in arr){print arr"\t"i}}' 文件名 | sort -rn
5.显示10条最常用的命令
sed -e "s/| /\n/g" ~/.bash_history | cut -d ' ' -f 1 | sort | uniq -c | sort -nr | head
6.杀死Nginx进程(杀死某一进程)
ps -ef|grep -v grep |grep nginx|awk '{print $2}' 或
for i in `ps aux | grep nginx | grep -v grep | awk {'print $2'}` ; do kill $i; done
7.列出当前文件夹目录大小,以G,M,K显示。
du -b --max-depth 1 | sort -nr | perl -pe 's{([0-9]+)}{sprintf"%.1f%s", $1>=2**30? ($1/2**30, "G"): $1>=2**20? ($1/2**20, "M"):$1>=2**10? ($1/2**10, "K"): ($1, "")}e'
shaw答案 :du -hs $(du -sk ./`ls -F |grep /` |sort -nr |awk '{print $NF}')
也可 以实现,不过不是特别完美。但好记。
8.清空linux buffer cache
sync && echo 3 > /proc/sys/vm/drop_caches
9.将当前目录文件名全部转换成小写
for i in *; do mv "$i" "$(echo $i|tr A-Z a-z)"; done
10.消除vim中的^M的几种方法
1)dos2uninx filename
2)sed -e 's/^M//' filename
3)vim中 :s/^M//gc
4)col -bx < dosfile > newfile
5)tr -s "\r\n" "\n" < file > newfile
11. 清除所有arp缓存
arp -n|awk '/^[1-9]/ {print "arp -d "$1}'|sh
12. 绑定已知机器的arp地址
cat /proc/net/arp | awk '{print $1 " " $4}' |sort -t. -n +3 -4 > /etc/ethers
补perl的可以不?
13. perl -ne 'm/^([^#][^\s=]+)\s*(=.*|)/ && printf("%-35s%s\n", $1, $2)' /etc/my.cnf
------------------- 修改linux系统的时间CST与EDT
初始时间:2012年 09月 14日 星期五 18:15:33 EDT
[root@test ~]# mv /etc/localtime /etc/localtime.bak
[root@test ~]# ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
[root@test ~]# date
修改后的时间:
2012年 09月 15日 星期六 18:25:00 CST
-------------------sudo权限
sudo权限的用户即可)登录系统,打开终端运行:
sudo vim /etc/sudoers
修改此配置文件,最后一行添加:
hello ALL=(ALL)ALL
注销用户,用户重登录。
------------------- 加入到PATH
export PATH=$PATH:/usr/local/mysql/bin
-------------------- history查看用户操作记录及时间
#vim /etc/profile 在文件的末尾加上如下代码:
export HISTTIMEFORMAT="%F %T `whoami` "
保存后,再执行 source /etc/profile 使配置生效。
再执行 history 命令,显示出了执行命令的时间和对应用户。
---------------------linux cp命令如何拷贝整个目录下所有文件
如何在Linux下拷贝一个目录呢?这好像是再简单不过的问题了。
比如要把/home/usera拷贝到/mnt/temp,首先想到的就是
cp -R /home/usera/* /mnt/temp
但是这样有一个问题,/home/usera下的隐藏文件都不会被拷贝,子目录下的隐藏文件倒是会的。
那如何才是正确的方法呢?有人说用-a选项,有人说用find加管道。
其实没这么复杂,Google了之后,学了一招。原来只有用“.”当前目录代替“*”就好了。
\cp -R /home/usera/. /mnt/temp
\cp -rf /home/usera/. /mnt/temp
--------------------- 问一个很笨的问题,请问如何删除一个中文的目录??
ls -i
然后按照inode去删除
rm -rf *AYXX-201205-01*
---------------------- kill killall pkill
kill 命令用于终止进程
例如: kill -9 [PID]
-9表示强迫进程立即停止
通常用ps 查看进程PID ,用kill命令终止进程
killall 通过程序的名字,直接杀死所有进程
killall -p php-fpm
pkill 和killall 应用方法差不多,也是直接杀死运行中的程序;如果您想杀掉单个进程,请用kill 来杀掉
pkill fpm
批量删除该服务的所有进程号:
ps -ef | grep ejb3 | grep -v grep | awk '{print $2" "$3}' | xargs kill -9 = pkill ejb3
killall -9 httpd 或者 kill -9 `ps aux |grep -i httpd |grep -v grep |awk '{print $2}' ` = kill -9 `pgrep httpd`
还有这个命令 ---------pgrep 也很好用。
ps aux | grep php | awk '{print $2 }' | xargs kill
ps aux|grep 进程名 | awk '{print $2 }' | xargs kill
--------------------- 查看 目录文件 磁盘空间大小
------根目录占用最多/dev/sda1
cd /,然后du -sh *,会列出每个目录的大小,找出占用最大,进入该目录,
再执行du -sh * ,以此类推,就能找到哪个文件占用的多,看是否需要删除
-------查看目录大小 df du
#df -h 查询磁盘信息,以M和G的格式显示
#du -h
#du -sh kushu001/ 查看当前目录下目录的大小,并不想看其他目录以及其子目录
16G kushu001/
#du -s kushu001/
16399552 kushu001/
#du -h .
查看当前目录下所有目录以及子目录的大小(会列出所有的子目录), “.”代表当前目录下。也可以换成一个明确的路径
#du -ah user 会列出每个目录和每个文件
列出user目录及其子目录下所有目录和文件的大小
#fdisk -l
查询磁盘信息
----------------------linux top zombie 僵死进程
# top
top - 14:25:15 up 8:14, 12 users, load average: 0.56, 1.93, 2.51
Tasks: 144 total, 2 running, 141 sleeping, 0 stopped, 1 zombie
Cpu(s): 2.2%us, 1.0%sy, 0.0%ni, 90.0%id, 0.2%wa, 2.7%hi, 4.0%si, 0.0%st
Mem: 3085636k total, 1275820k used, 1809816k free, 194212k buffers
Swap: 2097144k total, 0k used, 2097144k free, 662936k cached
# ps -ef |grep defunct
root 10342 28542 0 14:24 pts/9 00:00:00 grep defunct
root 10985 10980 0 10:50 ? 00:00:00 [sh] <defunct>
##kill子进程无效
# kill -9 10985
# ps -ef |grep defunct
root 10471 28542 0 14:25 pts/9 00:00:00 grep defunct
root 10985 10980 0 10:50 ? 00:00:00 [sh] <defunct>
# ps -ef | grep 10980
root 10348 28542 0 14:24 pts/9 00:00:00 grep 10980
root 10980 1 0 10:50 ? 00:00:00 CROND
root 10985 10980 0 10:50 ? 00:00:00 [sh] <defunct>
smmsp 11019 10980 0 10:50 ? 00:00:00 /usr/sbin/sendmail -FCronDaemon -i -odi -oem -oi -t -f root
## kill父进程
# ps -ef |grep defunct
root 10471 28542 0 14:25 pts/9 00:00:00 grep defunct
root 10985 10980 0 10:50 ? 00:00:00 [sh] <defunct>
# kill -9 10980
# ps -ef |grep defun
root 10550 28542 0 14:26 pts/9 00:00:00 grep defun
----------------------alias unalias
命 令: alias
功能说明:设置指令的别名。
语 法:alias[别名]=[指令名称]
补充说明:用户可利用alias,自定指令的别名。若仅输入alias,则可列出目前所有的别名设置。 alias的效力仅及于该次登入的操作。若要每次登入是即自动设好别名,可在/etc/profile或自己的~/.bashrc中设定指令的别名。
还有,如果你想给每一位用户都生效的别名,请把alias la='ls -al' 一行加在/etc/bashrc最后面,bashrc是环境变量的配置文件 /etc/bashrc和~/.bashrc 区别就在于一个是设置给全系统一个是设置给单用户使用.
参 数:若不加任何参数,则列出目前所有的别名设置。 资料来自 www.linuxso.com Linux安全网
CentOS5.6自带的alias定义
取消别名的方法是在命令前加\,比如 \mkdir
[[email protected] ~]#alias
alias cp='cp -i'
alias l.='ls -d .* --color=tty'
alias ll='ls -l --color=tty'
alias ls='ls --color=tty'
alias mv='mv -i'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
有的系统里没有ll这个命令,原因就是没有定义ll='ls -l --color=tty'这个别名
利用alias可以把很长的命令变成任意我们喜欢的简短的
设置和修改alias命令别名格式很简单
alias ll='ls -l --color=tty'
如果想永久生效,就把这条写入到 /etc/bashrc或~/.bashrc
为安装命令apt-get install创建别名:
alias install='sudo apt-get install'
删除:
unalias 命令
----------------------tree
以树状图逐级列出目录的内容命令
命令格式
tree <选项或者是参数> <分区或者是目录>
-a 显示所有文件和目录。
-d 显示目录名称而非内容。
-f 在每个文件或目录之前,显示完整的相对路径名称。
-F 在执行文件,目录,Socket,符号连接,管道名称名称,各自加上"*","/","=","@","|"号。
-r 以相反次序排列
-t 用文件和目录的更改时间排序。
-L n 只显示 n 层目录 (n 为数字)
--dirsfirst 目录显示在前文件显示在后
-A 使用ASNI绘图字符显示树状图而非以ASCII字符组合。
-C 在文件和目录清单加上色彩,便于区分各种类型。
-D 列出文件或目录的更改时间。
-g 列出文件或目录的所属群组名称,没有对应的名称时,则显示群组识别码。
-i 不以阶梯状列出文件或目录名称。
-I 不显示符合范本样式的文件或目录名称。
-l 如遇到性质为符号连接的目录,直接列出该连接所指向的原始目录。
-n 不在文件和目录清单加上色彩。
-N 直接列出文件和目录名称,包括控制字符。
-p 列出权限标示。
-P 只显示符合范本样式的文件或目录名称。
-q 用"?"号取代控制字符,列出文件和目录名称。
-s 列出文件或目录大小。
-u 列出文件或目录的拥有者名称,没有对应的名称时,则显示用户识别码。
-x 将范围局限在现行的文件系统中,若指定目录下的某些子目录,其存放于另一个文件系统上,则将该子目录予以排除在寻找范围外。
# tree -a
----------------------wc
wc命令用来计算一个文件或者指定的多个文件中的行数,单词数和字符数。如:
wc filename
第一列显示行数,第二列显示单词数,第三列显示字符数。
wc 有四个参数可选,分别是l,c,m,w
wc -l filename 报告行数
wc -c filename 报告字节数
wc -m filename 报告字符数
wc -w filename 报告单词数
-L 打印最长行的长度 wc file -L
ls -l|wc -l 用来统计当前目录下的文件数
$ wc -lcw file1 file2
4 33 file1
7 52 file2
11 11 85 total
---------------------- 切换目录 pushd popd dirs
pushd:切换到作为参数的目录,并把原目录和当前目录压入到一个虚拟的堆栈中
如果不指定参数,则会回到前一个目录,并把堆栈中最近的两个目录作交换
popd: 弹出堆栈中最近的目录
dirs: 列出当前堆栈中保存的目录列表
看例子:
[root@localhost ~]# pushd /usr/local/sbin/
/usr/local/sbin ~
[root@localhost sbin]# dirs
/usr/local/sbin ~
[root@localhost sbin]# dirs -p -v
0 /usr/local/sbin
1 ~
[root@localhost sbin]# pushd /usr/share/kde4/apps/kget/
/usr/share/kde4/apps/kget /usr/local/sbin ~
[root@localhost kget]# dirs -p -v
0 /usr/share/kde4/apps/kget
1 /usr/local/sbin
2 ~
说明: dirs的 -p参数可以每行一个目录的形式显示堆栈中的目录列表
-v参数可以在目录前加上编号
注意:有 -v时,不添加 -p也可以每行一个目录的形式显示
说明之二:我们可以看到:最近压入堆栈的目录位于最上面
2,如何在最近的两个目录之间切换?
在最近的两个目录之间切换:用pushd不加参数即可
[root@localhost kget]# pushd /boot/grub/
/boot/grub /usr/share/kde4/apps/kget /usr/local/sbin ~
[root@localhost grub]# dirs -v
0 /boot/grub
1 /usr/share/kde4/apps/kget
2 /usr/local/sbin
3 ~
[root@localhost grub]# pushd
/usr/share/kde4/apps/kget /boot/grub /usr/local/sbin ~
[root@localhost kget]# dirs -v
0 /usr/share/kde4/apps/kget
1 /boot/grub
2 /usr/local/sbin
3 ~
[root@localhost kget]# pushd
/boot/grub /usr/share/kde4/apps/kget /usr/local/sbin ~
[root@localhost grub]# dirs -v
0 /boot/grub
1 /usr/share/kde4/apps/kget
2 /usr/local/sbin
3 ~
说明:可以看到,用pushd不加参数在最近的两个目录之间切换时,
当前目录总是位于堆栈的最上面
3,如何在多个目录之间切换?
用 pushd +n即可
说明:
n是一个数字,有此参数时,是切换到堆栈中的第n个目录,并把此目录以堆栈循环的方式推到堆栈的顶部
需要注意: 堆栈从第0个开始数起
看例子:
[root@localhost grub]# dirs -v
0 /boot/grub
1 /usr/share/kde4/apps/kget
2 /usr/local/sbin
3 ~
[root@localhost grub]# pushd +2
/usr/local/sbin ~ /boot/grub /usr/share/kde4/apps/kget
[root@localhost sbin]# dirs -v
0 /usr/local/sbin
1 ~
2 /boot/grub
3 /usr/share/kde4/apps/kget
4,如何把目录从堆栈中删除?
用popd即可
看例子:
[root@localhost sbin]# dirs -v
0 /usr/local/sbin
1 ~
2 /boot/grub
3 /usr/share/kde4/apps/kget
[root@localhost sbin]# popd
~ /boot/grub /usr/share/kde4/apps/kget
[root@localhost ~]# dirs -v
0 ~
1 /boot/grub
2 /usr/share/kde4/apps/kget
[root@localhost ~]# popd +1
~ /usr/share/kde4/apps/kget
[root@localhost ~]# dirs -v
0 ~
1 /usr/share/kde4/apps/kget
说明:可以看到popd不加参数的运行情况:popd把堆栈顶端的目录从堆栈中删除,并切换于位于新的顶端的目录
说明之二: popd 加有参数 +n时,n是堆栈中的第n个目录,表示把堆栈中第n个目录从堆栈中删除
四,多学一点知识
1,pushd和popd都可以只影响堆栈而不切换目录,用 -n参数即可
看例子:
[root@localhost ~]# dirs -v
0 ~
1 /usr/share/kde4/apps/kget
[root@localhost ~]# pushd -n /boot/grub
~ /boot/grub /usr/share/kde4/apps/kget
[root@localhost ~]# dirs -v
0 ~
1 /boot/grub
2 /usr/share/kde4/apps/kget
2, dirs可以清空目录堆栈,用 -c参数即可
看例子:
[root@localhost ~]# dirs -v
0 ~
1 /boot/grub
2 /usr/share/kde4/apps/kget
[root@localhost ~]# dirs -c
[root@localhost ~]# dirs -v
0 ~
说明: 位于堆栈顶部的目录是当前目录,它不能被pop出去的
------------------ ls 排序
ls -l -t为按时间排序显示,默认为新的排在前面,可用下面的命令更改升降序:
ls -lrt 最新的文件排在后面(升序)
ls -lnt 最新的文件排在前面(降序)
-------------------- diff
diff -options oldfile/dir newfile/dir
常用的选项有:
-r 比较目录
-u 将差异的文件输出到文件中
$diff -ru file_one file_two > file_diff.diff
将file_one和file_two的区别输出到file_diff.diff文件中
--------------------- 备份数据库
cp -a /data/mysql/mysql_3302 /data/mysql/mysql_3302_back20120504 &
#查看是否备份完
jobs
#确认备份大小
du -sh /data/mysql/*
--------------------- 系统相关:
1.cat /proc/cpuinfo ##查看CPU的核数
2.cat /proc/version ##查看linux版本
3.ulimit -n ##显示当前文件描述符
4.ulimit -HSn 65536 ##修改当前用户环境下的文件描述符为65536
5.getconf LONG_BIT ##查看linux系统的位数,是32或还是64, 较实用
6.lsof ##列出当前系统打开文件, 特实用,可grep出你的进程或软件正在操作什么文件
7.ps -eLf | grep java | wc -l ##查看java的线程数,如果是单个java容器,就指这个容器的,多个指所有的总数
8.cat /etc/resolv.conf ##DNS域名解析的配置文件, 内部DNS用得多的系统经常使用
9.cat /etc/hosts ##查看host配置
--------------------- 连接状态:
(1). netstat -nat |awk '{print $6}'|sort|uniq -c|sort -rn 或
netstat -n | awk '/^tcp/ {++S[$NF]};END {for(a in S) print a, S[a]}' ##查看各tcp连接各状态的连接情况
(2). netstat -anlp|grep 80|grep tcp|awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort -nr|head -n30 ##查找80端口请求连接量最大的前30个IP(常用于查找攻来源,爬虫分析)
(3). netstat -n|grep TIME_WAIT|awk '{print $5}'|sort|uniq -c|sort -rn|head -n10 ##查找time_wait状态连接量前10
(4). netstat -nat -n | awk -F: '/tcp/{a[$(NF-1)]++}END{for(i in a)if(a>5)print i}' ##查询同时连接量大于5个连接的端口和IP
--------------------- 网站日志分析(apache或nginx):
1). cat access.log|awk '{print $1}'|sort|uniq -c|sort -nr|head -10 #取10,按量的倒序排 或cat access.log|awk '{counts[$(1)]+=1}; END {for(url in counts) print counts[url], url}'
##获得访问次数前10位的ip地址,具体print出来的第几项,还需要看log_format,那项是$remote_addr
2).cat access.log |awk '{print $10}'|sort|uniq -c|sort -nr|head -10 ##访问次数最多的文件或页面,取前10 还需要看log_format,第10项为页面
3).cat access.log |awk '{print $1}'|grep 'article.html' sort|uniq -c|sort -nr|head -10 ##查询文章页访问次数最多的前个IP
4).awk '($9 ~/404/)' access.log | awk '{print $9,$10}' | sort ##统计404的情况
5).cat access.log |awk '($NF > 10){print $NF " "$1" "$10 }'|sort -nr|head -30 ##查出前30个访问时间超过10秒的请求, 包括请求时间、IP、页面
1、linux启动过程
开启电源 --> BIOS开机自检 --> 引导程序lilo或grub --> 内核的引导(kernel boot)--> 执行init(rc.sysinit、rc)--> mingetty(建立终端) --> shell
2、网卡绑定多IP
ifconfig eth0:1 192.168.1.99 netmask 255.255.255.0
3、设置DNS、网关
echo "nameserver 202.16.53.68" >> /etc/resolv.conf
route add default gw 192.168.1.1
4、弹出、收回光驱
eject
eject -t
5、用date查询昨天的日期
date --date=yesterday
6、查询file1里面空行的所在行号
grep ^$ file
7、查询file1以abc结尾的行
grep abc$ file1
8、打印出file1文件第1到第三行
sed -n '1,3p' file1
head -3 file1
9、清空文件
true > 1.txt
echo "" > 1.txt
> 1.txt
cat /dev/null > 1.txt
10、删除所有空目录
find /data -type d -empty -exec rm -rf {} \;
11、linux下批量删除空文件(大小等于0的文件)的方法
find /data -type f -size 0c -exec rm -rf {} \;
find /data -type f -size 0c|xargs rm –f
12、删除五天前的文件
find /data -mtime +5 -type f -exec rm -rf {} \;
13、删除两个文件重复的部份,打印其它
cat 1.txt 3.txt |sort |uniq
14、攻取远程服务器主机名
echo `ssh $IP cat /etc/sysconfig/network|awk -F = '/HOSTNAME/ {print $2}'`
15、实时监控网卡流量(安装iftop)
/usr/local/iftop/sbin/iftop -i eth1 -n
16、查看系统版本
lsb_release -a
17、强制踢出登陆用户
pkill -KILL -t pts/1
18、tar增理备份、还原
tar -g king -zcvf kerry_full.tar.gz kerry
tar -g king -zcvf kerry_diff_1.tar.gz kerry
tar -g king -zcvf kerry_diff_2.tar.gz kerry
tar -zxvf kerry_full.tar.gz
tar -zxvf kerry_diff_1.tar.gz
tar -zxvf kerry_diff_2.tar.gz
19、将本地80端口的请求转发到8080端口,当前主机外网IP为202.96.85.46
-A PREROUTING -d 202.96.85.46 -p tcp -m tcp --dport 80 -j DNAT --to-destination 192.168.9.10:8080
20、在11月份内,每天的早上6点到12点中,每隔2小时执行一次/usr/bin/httpd.sh
crontab -e
0 6-12/2 * 11 * /usr/bin/httpd.sh
21、查看占用端口8080的进程
netstat -tnlp | grep 8080
lsof -i:8080
22、在Shell环境下,如何查看远程Linux系统运行了多少时间?
ssh user@被监控主机ip "uptime"
23、查看CPU使用情况的命令
""每5秒刷新一次,最右侧有CPU的占用率的数据
vmstat 5
""top 然后按Shift+P,按照进程处理器占用率排序
top
24、查看内存使用情况的命令
""用free命令查看内存使用情况
free -m
""top 然后按Shift+M, 按照进程内存占用率排序
top
25、查看磁盘i/o
""用iostat查看磁盘/dev/sdc3的磁盘i/o情况,每两秒刷新一次
iostat -d -x /dev/sdc3 2
26、修复文件系统
fsck –yt ext3 /
-t 指定文件系统
-y 对发现的问题自动回答yes
27、read 命令5秒后自动退出
read -t 5
28、grep -E -P 是什么意思
-E, --extended-regexp 采用扩展正规表达式。
-P,--perl-regexp 采用perl正规表达式
29、vi编辑器(涉及到修改,添加,查找)
插入(insert)模式
i 光标前插入
I 光标行首插入
a 光标后插入
A 光标行尾插入
o 光标所在行下插入一行,行首插入
O 光标所在行上插入一行,行首插入
G 移至最后一行行首
nG 移至第n行行首
n+ 下移n行,行首
n- 上移n行,行首
:/str/ 从当前往右移动到有str的地方
:?str? 从当前往左移动到有str的地方
:s/str1/str2/ 将找到的第一个str1替换为str2
:s/str2/str2/g 将当前行找到的所有str1替换为str2
:n1,n2s/str1/str2/g 将从n1行至n2行找到的所有的str1替换为str2
:1,.s/str1/str2/g 将从第1行至当前行的所有str1替换为str2
:.,$s/str1/str2/g 将从当前行至最后一行的所有str1替换为str2
30、linux服务器之间相互复制文件
copy 本地文件1.sh到远程192.168.9.10服务器的/data/目录下
scp /etc/1.sh [email protected]:/data/
copy远程192.168.9.10服务器/data/2.sh文件到本地/data/目录
scp [email protected]:/data/2.sh /data/
31、使用sed命令把test.txt文件的第23行的TEST换成TSET.
sed -i '23s/TEST/TSET/' test.txt
sed -i '23 s/TEST/TSET/' test.txt
32、使history命令能显示时间
export HISTTIMEFORMAT="%F %T "
33、如何查看目标主机192.168.0.1开放那些端口
nmap -PS 192.168.0.1
34、如何查看网络连接
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
35、如何查看当前系统使用了那些库文件
ldconfig -v
36、如何查看网卡的驱动版本
ethtool -i eth0
37、使用tcpdump来监视主机192.168.0.1的tcp的80端口
tcpdump tcp port 80 host 192.168.0.1
38、 如何看其它用户的邮件列表
mial -u king
39、对大文件进行切割
按每个文件1000行来分割
split -l 1000 httperr8007.log httperr
按照每个文件5m来分割
split -b 5m httperr8007.log httperr
40、合并文件
取出两个文件的并集(重复的行只保留一份)
cat file1 file2 | sort | uniq
取出两个文件的交集(只留下同时存在于两个文件中的文件)
cat file1 file2 | sort | uniq -d
删除交集,留下其他的行
cat file1 file2 | sort | uniq –u
41、打印文本模式下运行的服务
chkconfig --list|awk '$5~/on/{print $1,$5}'
系统连接状态篇:
1.查看TCP连接状态
netstat -nat |awk '{print $6}'|sort|uniq -c|sort -rn
netstat -n | awk '/^tcp/ {++S[$NF]};END {for(a in S) print a, S[a]}' 或
netstat -n | awk '/^tcp/ {++state[$NF]}; END {for(key in state) print key,"\t",state[key]}'
netstat -n | awk '/^tcp/ {++arr[$NF]};END {for(k in arr) print k,"\t",arr[k]}'
netstat -n |awk '/^tcp/ {print $NF}'|sort|uniq -c|sort -rn
netstat -ant | awk '{print $NF}' | grep -v '[a-z]' | sort | uniq -c
2.查找请求数请20个IP(常用于查找攻来源):
netstat -anlp|grep 80|grep tcp|awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort -nr|head -n20
netstat -ant |awk '/:80/{split($5,ip,":");++A[ip[1]]}END{for(i in A) print A[i],i}' |sort -rn|head -n20
3.用tcpdump嗅探80端口的访问看看谁最高
tcpdump -i eth0 -tnn dst port 80 -c 1000 | awk -F"." '{print $1"."$2"."$3"."$4}' | sort | uniq -c | sort -nr |head -20
4.查找较多time_wait连接
netstat -n|grep TIME_WAIT|awk '{print $5}'|sort|uniq -c|sort -rn|head -n20
5.找查较多的SYN连接
netstat -an | grep SYN | awk '{print $5}' | awk -F: '{print $1}' | sort | uniq -c | sort -nr | more
6.根据端口列进程
netstat -ntlp | grep 80 | awk '{print $7}' | cut -d/ -f1
网站日志分析篇1(Apache):
1.获得访问前10位的ip地址
cat access.log|awk '{print $1}'|sort|uniq -c|sort -nr|head -10
cat access.log|awk '{counts[$(11)]+=1}; END {for(url in counts) print counts[url], url}'
2.访问次数最多的文件或页面,取前20
cat access.log|awk '{print $11}'|sort|uniq -c|sort -nr|head -20
3.列出传输最大的几个exe文件(分析下载站的时候常用)
cat access.log |awk '($7~/\.exe/){print $10 " " $1 " " $4 " " $7}'|sort -nr|head -20
4.列出输出大于200000byte(约200kb)的exe文件以及对应文件发生次数
cat access.log |awk '($10 > 200000 && $7~/\.exe/){print $7}'|sort -n|uniq -c|sort -nr|head -100
5.如果日志最后一列记录的是页面文件传输时间,则有列出到客户端最耗时的页面
cat access.log |awk '($7~/\.php/){print $NF " " $1 " " $4 " " $7}'|sort -nr|head -100
6.列出最最耗时的页面(超过60秒的)的以及对应页面发生次数
cat access.log |awk '($NF > 60 && $7~/\.php/){print $7}'|sort -n|uniq -c|sort -nr|head -100
7.列出传输时间超过 30 秒的文件
cat access.log |awk '($NF > 30){print $7}'|sort -n|uniq -c|sort -nr|head -20
8.统计网站流量(G)
cat access.log |awk '{sum+=$10} END {print sum/1024/1024/1024}'
9.统计404的连接
awk '($9 ~/404/)' access.log | awk '{print $9,$7}' | sort
10. 统计http status.
cat access.log |awk '{counts[$(9)]+=1}; END {for(code in counts) print code, counts[code]}'
cat access.log |awk '{print $9}'|sort|uniq -c|sort -rn
10.蜘蛛分析
查看是哪些蜘蛛在抓取内容。
/usr/sbin/tcpdump -i eth0 -l -s 0 -w - dst port 80 | strings | grep -i user-agent | grep -i -E 'bot|crawler|slurp|spider'
网站日分析2(Squid篇)
2.按域统计流量
zcat squid_access.log.tar.gz| awk '{print $10,$7}' |awk 'BEGIN{FS="[ /]"}{trfc[$4]+=$1}END{for(domain in trfc){printf "%s\t%d\n",domain,trfc[domain]}}'
效率更高的perl版本请到此下载:http://docs.linuxtone.org/soft/tools/tr.pl
数据库篇
1.查看数据库执行的sql
/usr/sbin/tcpdump -i eth0 -s 0 -l -w - dst port 3306 | strings | egrep -i 'SELECT|UPDATE|DELETE|INSERT|SET|COMMIT|ROLLBACK|CREATE|DROP|ALTER|CALL'
系统Debug分析篇
1.调试命令
strace -p pid
2.跟踪指定进程的PID
gdb -p pid
一、Screen OS抓包
debug:跟踪防火墙对数据包的处理过程
1. Set ffilter src-ip x.x.x.x dst-ip x.x.x.x dst-port xx
设置过滤列表,定义捕获包的范围
2、clear dbuf
清除防火墙内存中缓存的分析包
3、debug flow basic
开启debug数据流跟踪功能
4、发送测试数据包或让小部分流量穿越防火墙
5、undebug all
关闭所有debug功能
6、get dbuf stream
检查防火墙对符合过滤条件数据包的分析结果
7、unset ffilter
清除防火墙debug过滤列表
8、clear dbuf
清除防火墙缓存的debug信息
9、get debug
查看当前debug设置
Snoop:捕获进出防火墙的数据包,与Sniffer嗅包软件功能类似
1. Snoop filter ip src-ip x.x.x.x dst-ip x.x.x.x dst-port xx
设置过滤列表,定义捕获包的范围
2、clear dbuf
清除防火墙内存中缓存的分析包
3、snoop
开启snoop功能捕获数据包
4、发送测试数据包或让小部分流量穿越防火墙
5、snoop off
停止snoop
6、get db stream
检查防火墙对符合过滤条件数据包的分析结果
7、snoop filter delete
清除防火墙snoop过滤列表
8、clear dbuf
清除防火墙缓存的debug信息
9、snoop info
查看snoop设置
二、SRX 抓包
debug:跟踪防火墙对数据包的处理过程
SRX对应ScreenOS debug flow basic跟踪报文处理路径的命令:
set security flow traceoptions flag basic-datapath 开启SRX基本报文处理Debug
set security flow traceoptions file filename.log 将输出信息记录到指定文件中
set security flow traceoptions file filename.log size <file-size> 设置该文件大小,缺省128k
set security flow traceoptions packet-filter filter1 destination-prefix 5.5.5.2 设置报文跟踪过滤器
run file show filename.log 查看该Log输出信息
tcpdump介绍
tcpdump 是一个运行在命令行下的抓包工具。它允许用户拦截和显示发送或收到过网络连接到该计算机的TCP/IP和其他数据包。tcpdump 适用于
大多数的类Unix系统操作系统(如linux,BSD等)。类Unix系统的 tcpdump 需要使用libpcap这个捕捉数据的库就像 windows下的WinPcap。
在学习tcpdump前最好对基本网络的网络知识有一定的认识。
tcpdump命令格式及常用参数
Tcpdump的大概形式如下:
例:tcpdump –i eth0 ’port 1111‘ -X -c 3
tcpdump采用命令行方式,它的命令格式为:
tcpdump [ -adeflnNOpqStvx ] [ -c 数量 ] [ -F 文件名 ]
[ -i 网络接口 ] [ -r 文件名] [ -s snaplen ]
[ -T 类型 ] [ -w 文件名 ] [表达式 ]
tcpdump的选项介绍
-a 将网络地址和广播地址转变成名字;
-d 将匹配信息包的代码以人们能够理解的汇编格式给出;
-dd 将匹配信息包的代码以c语言程序段的格式给出;
-ddd 将匹配信息包的代码以十进制的形式给出;
-e 在输出行打印出数据链路层的头部信息;
-f 将外部的Internet地址以数字的形式打印出来;
-l 使标准输出变为缓冲行形式;
-n 不把网络地址转换成名字;
-t 在输出的每一行不打印时间戳;
-v 输出一个稍微详细的信息,例如在ip包中可以包括ttl和服务类型的信息;
-vv 输出详细的报文信息;
-c 在收到指定的包的数目后,tcpdump就会停止;
-F 从指定的文件中读取表达式,忽略其它的表达式;
-i 指定监听的网络接口;
-r 从指定的文件中读取包(这些包一般通过-w选项产生);
-w 直接将包写入文件中,并不分析和打印出来;
-T 将监听到的包直接解释为指定的类型的报文,常见的类型有rpc (远程过程调用)和snmp(简单网络管理协议;)
如键入命令: tcpdump –i eth0 ‘port 1111’ -X -c 3

-i 是interface的含义,是指我们有义务告诉tcpdump希望他去监听哪一个网卡,
-X告诉tcpdump命令,需要把协议头和包内容都原原本本的显示出来(tcpdump会以16进制和ASCII的形式显示),这在进行协议分析时是绝对的利器。
port 1111我们只关心源端口或目的端口是1111的数据包.
-c 是Count的含义,这设置了我们希望tcpdump帮我们抓几个包。
其中还有另外一个比较重要的参数– l 使得输出变为行缓冲
-l选项的作用就是将tcpdump的输出变为“行缓冲”方式,这样可以确保tcpdump遇到的内容一旦是换行符即将缓冲的内容输出到标准输出,以便于利用管道
或重定向方式来进行后续处理。
Linux/UNIX的标准I/O提供了全缓冲、行缓冲和无缓冲三种缓冲方式。标准错误是不带缓冲的,终端设备常为行缓冲,而其他情况默认都是全缓冲的。
例如我们只想提取包的每一行的第一个域(时间域),这种情况下我们就需要-l将默认的全缓冲变为行缓冲了。
参数–w -r
-w 直接将包写入文件中(即原始包,如果使用 重定向 > 则只是保存显示的结果,而不是原始文件),即所谓的“流量保存”---就是把抓到的网络包能存储到磁盘上,
保存下来,为后续使用。参数-r 达到“流量回放”---就是把历史上的某一时间段的流量,重新模拟回放出来,用于流量分析。

通过-w选项将流量都存储在cp.pcap(二进制格式)文件中了.可以通过 –r 读取raw packets文件 cp.pcap.
如:sudo tcpdump i- eth0 'port 1111' -c 3 -r cp.pcap 即可进行流量回放。
 tcpdump的输出结果介绍
tcpdump的输出结果介绍
键入命令:sudo tcpdump -i eth0 -e -nn -X -c 2 'port1111' 所截获包内容如下:
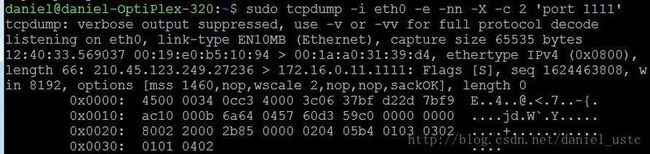
第一行:“tcpdump: verbose output suppressed, use -v or -vv for fullprotocol decode”
提示使用选项-v和-vv,可以看到更全的输出内容。
第二行“listening on eth0, link-type EN10MB (Ethernet), capture size 65535bytes”
我们监听的是通过eth0这个NIC设备的网络包,且它的链路层是基于以太网的,要抓的包大小限制是65535字节。包大小限制值可以通过-s选项来设置。
第三行”12:40:33.569037 00:19:e0:b5:10:94 > 00:1a:a0:31:39:d4, ethertypeIPv4 (0x0800),”
12:40:33.569037 分别对应着这个包被抓到的“时”、“分”、“秒”、“微妙”。
00:19:e0:b5:10:94 > 00:1a:a0:31:39:d4 表示MAC地址00:19:e0:b5:10:94发送到MAC地址为00:1a:a0:31:39:d4的主机,ethertype IPv4 (0x0800)表示
Ethernet帧的协议类型为ipv4(即代码为0x0800)。
第四行”length 66: 210.45.123.249.27236 > 172.16.0.11.1111: Flags [S],seq 1624463808,
length 66表示以太帧长度为66。 210.45.123.249.27236表示这个包的源IP为210.45.123.249,源端口为27236,’>’表示数据包的传输方向, 172.16.0.11.1111,
表示这个数据包的目的端ip为172.16.0.11,目标端口为1111,1111端口是我的一个web服务器监听端口。Flags是[S],表明是syn建立连接包(即三次握手的第一次
握手),seq1624463808 序号为1624463808,这个其实就是TCP三次握手的第一次握手:client(210.45.123.249)发送syn请求建立连接包。
第五行” win 8192, options [mss 1460,nop,wscale 2,nop,nop,sackOK], length 0”
win 8192 表示窗口大小为8192字节。options[mss 1460,nop,wscale 2,nop,nop,sackOK]为tcp首部可选字段mss 1460表示mss是发送端(客户端)通告的最大
报文段长度,发送端将不接收超过这个长度的TCP报文段(这个值和MTU有一定关系)。nop是一个空操作选项, wscale指出发送端使用的窗口扩大因子为2, sackOK
表示发送端支持并同意使用SACK选。
下面几行分别是IP,TCP首部 ,这里不再敷述。
tcpdump过滤语句介绍
可以给tcpdump传送“过滤表达式”来起到网络包过滤的作用,而且可以支持传入单个或多个过滤表达式。
可以通过命令 man pcap-filter 来参考过滤表达式的帮助文档
过滤表达式大体可以分成三种过滤条件,“类型”、“方向”和“协议”,这三种条件的搭配组合就构成了我们的过滤表达式。
关于类型的关键字,主要包括host,net,port, 例如 host 210.45.114.211,指定主机 210.45.114.211,net 210.11.0.0 指明210.11.0.0是一个网络地址,port 21 指明
端口号是21。如果没有指定类型,缺省的类型是host.
关于传输方向的关键字,主要包括src , dst ,dst or src, dst and src ,
这些关键字指明了传输的方向。举例说明,src 210.45.114.211 ,指明ip包中源地址是210.45.114.211, dst net 210.11.0.0 指明目的网络地址是210.11.0.0 。如果没有指明
方向关键字,则缺省是srcor dst关键字。
关于协议的关键字,主要包括 ether,ip,ip6,arp,rarp,tcp,udp等类型。这几个关键字指明了监听的包的协议内容。如果没有指定任何协议,则tcpdump将会监听所有协议的
信息包。
如我们只想抓tcp的包命令为: sudo tcpdump -i eth0 -nn -c1 'tcp'

除了这三种类型的关键字之外,其他重要的关键字如下:
gateway, broadcast,less,greater,还有三种逻辑运算,取非运算是 'not ' '! ', 与运算是'and','&&';或运算是'or' ,'||';
可以利用这些关键字进行组合,从而组合为比较强大的过滤条件。下面举例说明
(1)只想查目标机器端口是21或80的网络包,其他端口的我不关注:
sudo tcpdump -i eth0 -c 10 'dst port 21 or dst port 80'
(2) 想要截获主机172.16.0.11 和主机210.45.123.249或 210.45.123.248的通信,使用命令(注意括号的使用):
sudo tcpdump -i eth0 -c 3 'host 172.16.0.11 and (210.45.123.249 or210.45.123.248)'
(3)想获取使用ftp端口和ftp数据端口的网络包
sudo tcpdump 'port ftp or ftp-data'
这里 ftp、ftp-data到底对应哪个端口? linux系统下 /etc/services这个文件里面,就存储着所有知名服务和传输层端口的对应关系。如果你直接把/etc/services里
的ftp对应的端口值从21改为了3333,那么tcpdump就会去抓端口含有3333的网络包了。
(4) 如果想要获取主机172.16.0.11除了和主机210.45.123.249之外所有主机通信的ip包,使用命令:
sudo tcpdump ip ‘host 172.16.0.11 and ! 210.45.123.249’
(5) 抓172.16.0.11的80端口和110和25以外的其他端口的包
sudo tcpdump -i eth0 ‘host 172.16.0.11 and! port 80 and ! port 25 and ! port 110’
下面介绍一些tcpdump中过滤语句比较高级的用法想获取172.16.10.11和google.com之间建立TCP三次握手中带有SYN标记位的网络包.
命令为:sudo tcpdump -i eth0 'host 172.16.0.11 andhost google.com and tcp[tcpflags]&tcp-syn!=0' -c 3 -nn
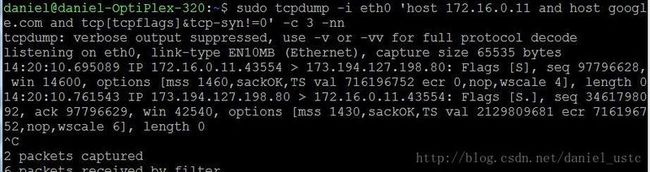
上面的命令是不是看着有点晕的感觉,下面详细介相关知识。
其实我们理解这种语法: proto [ expr : size] ,就不难理解上面的语句了。
下面详细介绍proto [ expr : size]
Proto即protocol的缩写,它表示这里要指定的是某种协议名称,如ip,tcp,udp等。总之可以指定的协议有十多种,如链路层协议 ether,fddi,tr,wlan,ppp,slip,link,
网络层协议ip,ip6,arp,rarp,icmp传输层协议tcp,udp等。
expr用来指定数据报字节单位的偏移量,该偏移量相对于指定的协议层,默认的起始位置是0;而size表示从偏移量的位置开始提取多少个字节,可以设置为
1、2、4,默认为1字节。如果只设置了expr,而没有设置size,则默认提取1个字节。比如ip[2:2],就表示提取出第3、4个字节;而ip[0]则表示提取ip协议头的
第一个字节。在我们提取了特定内容之后,我们就需要设置我们的过滤条件了,我们可用的“比较操作符”包括:>,<,>=,<=,=,!=,总共有6个。
举例:想截取每个TCP会话的起始和结束报文(SYN 和 FIN 报文), 而且会话方中有一个远程主机.
sudo tcpdump 'tcp[13] & 3 != 0 and not(src and dst net 172.16.0.0)' -nn
如果熟悉tcp首部报文格式可以比较容易理解这句话,因为tcp便宜13字节的位置为2位保留位和6位标志位(URG,ACK,PSH,RST,SYN,FIN), 所以与3相与就可以得出
SYN,FIN其中是否一个置位1.
从上面可以看到在写过滤表达式时,需要我们对协议格式比较理解才能把表达式写对。这个比较有难度的..。为了让tcpdump工具更人性化一些,有一些常用的偏移量,
可以通过一些名称来代替,比如icmptype表示ICMP协议的类型域、icmpcode表示ICMP的code域,tcpflags 则表示TCP协议的标志字段域。
更进一步的,对于ICMP的类型域,可以用这些名称具体指代:icmp-echoreply, icmp-unreach, icmp-sourcequench, icmp-redirect,icmp-echo, icmp-routeradvert, icmp-routersolicit, icmp-timxceed, icmp-paramprob,icmp-tstamp, icmp-tstampreply, icmp-ireq, icmp-ireqreply, icmp-maskreq,icmp-maskreply。
而对于TCP协议的标志字段域,则可以细分为tcp-fin, tcp-syn, tcp-rst, tcp-push, tcp-ack, tcp-urg。
对于tcpdump 只能通过经常操作来熟练这些语句了。也可以把网络包用tcpdump截获保存到指定文件,然后用wireshark等可视化软件分析网络包。
如何检查Linux的内存使用状况
问题:我想要监测Linux系统的内存使用状况。有哪些可用的图形界面或者命令行工具来检查当前内存使用情况?
当涉及到Linux系统性能优化的时候,物理内存是一个最重要的因素。自然的,Linux提供了丰富的选择来监测珍贵的内存资源的使用情况。不同的工具,在监测粒度(例如:全系统范围,每个进程,每个用户),接口方式(例如:图形用户界面,命令行,ncurses)或者运行模式(交互模式,批量处理模式)上都不尽相同。
下面是一个可供选择的,但并不全面的图形或命令行工具列表,这些工具用来检查Linux平台中已用和可用的内存。
1./proc/meminfo
一种最简单的方法是通过“/proc/meminfo”来检查内存使用状况。这个动态更新的虚拟文件事实上是诸如free,top和ps这些与内存相关的工具的信息来源。从可用/闲置物理内存数量到等待被写入缓存的数量或者已写回磁盘的数量,只要是你想要的关于内存使用的信息,“/proc/meminfo”应有尽有。特定进程的内存信息也可以通过“/proc/ /statm”和“/proc//status”来获取。
|
1
|
$ cat /proc/meminfo
|
2.atop
atop命令是用于终端环境的基于ncurses的交互式的系统和进程监测工具。它展示了动态更新的系统资源摘要(CPU, 内存, 网络, 输入/输出, 内核),并且用醒目的颜色把系统高负载的部分以警告信息标注出来。它同样提供了类似于top的线程(或用户)资源使用视图,因此系统管理员可以找到哪个进程或者用户导致的系统负载。内存统计报告包括了总计/闲置内存,缓存的/缓冲的内存和已提交的虚拟内存。
|
1
|
$ sudo atop
|
3.free
free命令是一个用来获得内存使用概况的快速简单的方法,这些信息从“/proc/meminfo”获取。它提供了一个快照,用于展示总计/闲置的物理内存和系统交换区,以及已使用/闲置的内核缓冲区。
|
1
|
free -h
|
4.GNOME System Monitor
GNOME System Monitor 是一个图形界面应用,它展示了包括CPU,内存,交换区和网络在内的系统资源使用率的较近历史信息。它同时也可以提供一个带有CPU和内存使用情况的进程视图。
|
1
|
$ gnome-system-monitor
|
5.htop
htop命令是一个基于ncurses的交互式的进程视图,它实时展示了每个进程的内存使用情况。它可以报告所有运行中进程的常驻内存大小(RSS)、内存中程序的总大小、库大小、共享页面大小和脏页面大小。你可以横向或者纵向滚动进程列表进行查看。
|
1
|
$ htop
|
6.KDE System Monitor
就像GNOME桌面拥有GNOME System Monitor一样,KDE桌面也有它自己的对口应用:KDE System Monitor。这个工具的功能与GNOME版本极其相似,也就是说,它同样展示了一个关于系统资源使用情况,以及带有每个进程的CPU/内存消耗情况的实时历史记录。
|
1
|
$ ksysguard
|
7.memstat
memstat工具对于识别正在消耗虚拟内存的可执行部分、进程和共享库非常有用。给出一个进程识别号,memstat即可识别出与之相关联的可执行部分、数据和共享库究竟使用了多少虚拟内存。
|
1
|
$ memstat -p <PID>
|
8.nmon
nmon工具是一个基于ncurses系统基准测试工具,它能够以交互方式监测CPU、内存、磁盘I/O、内核、文件系统以及网络资源。对于内存使用状况而言,它能够展示像总计/闲置内存、交换区、缓冲的/缓存的内存,虚拟内存页面换入换出的统计,所有这些都是实时的。
|
1
|
$ nmon
|
9.ps
ps命令能够实时展示每个进程的内存使用状况。内存使用报告里包括了 %MEM (物理内存使用百分比), VSZ (虚拟内存使用总量), 和 RSS (物理内存使用总量)。你可以使用“–sort”选项来对进程列表排序。例如,按照RSS降序排序:
|
1
|
$ ps aux --sort -rss
|
10.smem
smem命令允许你测定不同进程和用户的物理内存使用状况,这些信息来源于“/proc”目录。它利用“按比例分配大小(PSS)”指标来精确量化Linux进程的有效内存使用情况。内存使用分析结果能够输出为柱状图或者饼图类的图形化图表。
|
1
|
$ sudo smem --pie name -c "pss"
|
11.top
top命令提供了一个运行中进程的实时视图,以及特定进程的各种资源使用统计信息。与内存相关的信息包括 %MEM (内存使用率), VIRT (虚拟内存使用总量), SWAP (换出的虚拟内存使用量), CODE (分配给代码执行的物理内存数量), DATA (分配给非执行的数据的物理内存数量), RES (物理内存使用总量; CODE+DATA), 和 SHR (有可能与其他进程共享的内存数量)。你能够基于内存使用情况或者大小对进程列表进行排序。
12.vmstat
vmstat命令行工具显示涵盖了CPU、内存、中断和磁盘I/O在内的各种系统活动的瞬时和平均统计数据。对于内存信息而言,命令不仅仅展示了物理内存使用情况(例如总计/已使用内存和缓冲的/缓存的内存),还同样展示了虚拟内存统计数据(例如,内存页的换入/换出,虚拟内存页的换入/换出)
|
1
|
$ vmstat -s
|