cloudify运行环境
Cloudify的基本部署单元是Processing Unit(处理单元),一旦处理单元部署到运行环境(Service Grid)。Processing Unit完成Processing Unit的配置,提供实例到运行环境的基础设施下,并保证它正确运行。
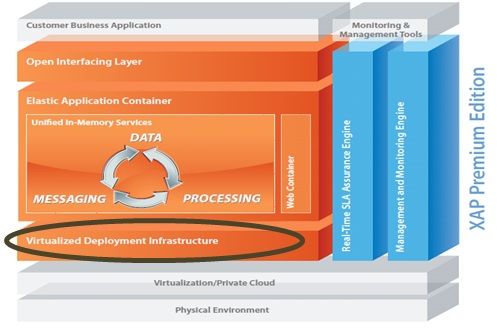
Service Grid由下列组件构成:
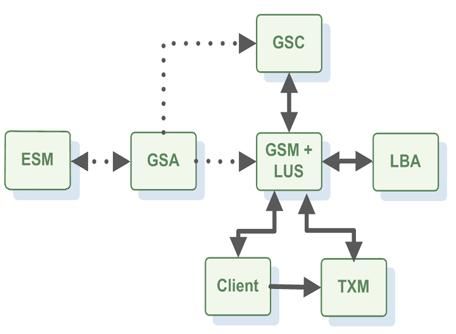
The Grid Service Agent (GSA)
GSA是一个守护进程,能够启动和停止其他运行的组件(在处理/JVM层面)。GSA随托管的主机启动而启动,使用GSA可以非常容易的启动整个集群,并且随意启动和停止GSC、GSM和LUS服务。
GSA可以看作一个管理进程,产生并管理Service Grid进程(操作系统级别进程),如GSM,GSC,LUS.通常每个机器运行一个GSA,GSA允许产生GSM,GSC,LUS和一些自定义进程。一旦产生,GSA分配一个唯一的ID给产生的实例并管理它的生命周期。实例出现异常(如内存溢出异常),GSA将重启这个进程。可以使用Administration and Monitoring API或GigaSpaces UI 来启动、重启和终止进程。
虽然GSM、GSC和LUS可以通过各自的脚本启动,但是最好是通过GSA来启动,那样可以简单的监控和管理它们。GSA管理操作系统进程,有两类管理进程:本地和全局的。
本地进程(例如GSC)简单启动进程类型而不考虑运行在其他GSAs的其他进程类型。
全局进程考虑运行在其他GSAs(在相同的lookup groups或lookup locators)上的进程类型的数量(例如GSM)。它将在所有不同的GSAs(最多一个GSA一个进程类型)上自动尝试运行至少X个进程。如果GSA运行一个失败的全局管理进程类型,另一个GSA将确认失败并启动这个进程维持至少X个全局的进程类型。
为了启动GSA可以使用脚本CloudifyROOT/bin/gs-agent.(sh/bat),GSA默认启动2个本地GSC,管理2个全局GSM和2个全局LUS。
所有组件共享的JVM参数(系统特性,堆设置等)使用EXT_JAVA_OPTIONS环境变量。
#Wrapper Script LINUX export GSA_JAVA_OPTIONS=-Xmx256m export GSC_JAVA_OPTIONS=-Xmx2048m export GSM_JAVA_OPTIONS=-Xmx1024m export LUS_JAVA_OPTIONS=-Xmx1024m #call gs-agent.sh . ./gs-agent.sh
@rem Wrapper Script WINDOWS @set GSA_JAVA_OPTIONS=-Xmx256m @set GSC_JAVA_OPTIONS=-Xmx2048m @set GSM_JAVA_OPTIONS=-Xmx1024m @set LUS_JAVA_OPTIONS=-Xmx1024m @rem call gs-agent.bat call gs-agent.bat
GSA参数包括控制多少个GSA产生和启动(每个进程类型)的本地进程,维持全局管理进程GSA的数量(和其他GSAs协作)
默认情况下,GSA启动2个本地GSCs,管理2个全局GSM和2个全局LUS,相当于下面的启动参数:
gs-agent.(sh/bat) gsa.gsc 2 gsa.global.gsm 2 gsa.global.lus 2例如,启动3个本地GSC,2个全局GSM和0个LUS,则启动命令为:
gs-agent.(sh/bat) gsa.gsc 3 gsa.global.gsm 2 gsa.global.lus 0
通常,gsa.[进程类型]后跟着通过GSA产生的控制本地进程的数量和特定进程类型,gsa.global.[进程类型]后跟着全局管理进程数量和特定类型。
GSA管理不同的进程类型,在<CloudifyHOME>\config\gsa下的xml文件(gsc.xml、gsm.xml、lus.xml、gsm_lus.xml、esm.xml)定义每个进程类型。以gsc.xml为例:
<process initial-instances="script" shutdown-class="com.gigaspaces.grid.gsa.GigaSpacesShutdownProcessHandler" restart-on-exit="always">
<script enable="true" work-dir="${com.gs.home}/bin"
windows="${com.gs.home}/bin/gsc.bat"
unix="${com.gs.home}/bin/gsc.sh">
<argument></argument>
</script>
<vm enable="true" work-dir="${com.gs.home}/bin"
main-class="com.gigaspaces.start.SystemBoot">
<input-argument></input-argument>
<argument>com.gigaspaces.start.services="GSC"</argument>
</vm>
<restart-regex>.*OutOfMemoryError.*</restart-regex>
</process> GSA可以产生一个基本进程或者但参数的纯JVM进程。以GSC为例,允许产生两种类型的进程。
- 初始化实例参数控制GSA产生进程类型,而不需要使用Admin API
- 关闭类后跟着restart-on-exit标志,控制进程终止时重启
- 有三种类型:
- restart-on-exit="always": 只要这个进程存在就重启这个进程
- restart-on-exit="never": 进程存在则从不重启这个进程
- restart-on-exit="!0": 重启这个进程,如果退出状态码不为0.
- 关闭类的实现了com.gigaspaces.grid.gsa.ShutdownProcessHandler接口并提供关闭进程前后默认的关闭钩子来保证正确关闭。
- 有三种类型:
- restart-regex (可以有多个元素)被应用在每个管理进程的控制台输出,如果有一个匹配,GSA将自动重启这个进程。默认出现OutOfMemoryError,GSC将重启。
gs-agent.(sh/bat) gsa.global.lus 0 gsa.lus 1
不运行LUS则使用:
gs-agent.(sh/bat) gsa.global.lus 0
The Grid Service Container (GSC)
当处理单元已经部署,它的实例将运行在Gigaspaces容器内,GSC提供一个隔离的运行环境来运行处理单元实例,并暴露它的状态给GSM。
GSC是一个寄宿处理单元实例的容器(已部署的处理单元示例),GSC被认为是在网格中由GSM控制的一个节点。GSM提供在GSC中部署和解除部署处理单元实例的命令。GSC报告实例的状态给GSM。另一方面,GSC可以寄宿处理单元,GSC类加载等级确保在同一个GSC下的处理单元实例相互隔离。通常在同一个物理机中启动几个GSC,个数取决于机器CPU和内存资源。
部署多个GSC在一个或多个机器上构成一个虚拟的服务网格。实际上,GSC提供机器物理顶层的抽象层,这个概念支撑企业数据中心和公有云多样化的部署拓扑结构集群的需求。
启动GSC最好的方式是使用GSA,GSC也可以使用自身脚本[CloudifyHOME]/bin/gsc.(bat/sh)
使用系统特性来配置GSC(其他系统级别的服务,如通信层)#Wrapper Script LINUX export GSC_JAVA_OPTIONS=-Xmx1024m #call gsc.sh . ./gsc.sh
@rem Wrapper Script windows @set GSC_JAVA_OPTIONS=-Xmx1024m @rem call gsc.bat call gsc.bat
The Grid Service Manager (GSM)
GSM是管理处理单元的部署和生命周期的组件。GSM分析部署描述器并决定创建处理单元实例的个数,哪些GSC来运行对应的处理单元实例。GSM将处理单元代码上传到运行的GSC,并根据上传代码实例化处理单元实例。部署过程中的这个阶段称为provisioning(服务准备)。一旦服务准备完成,GSM立刻监控处理单元示例运行情况。当某一特定实例失败,GSM标识并重新部署失败的实例到其他GSC,这样可以增强处理单元的SLA。在一个典型的部署中一般有2-3个GSM服务,当其中一个失败,则其他的GSM接管。在任何给定的时间点,每个已部署的处理单元都被某个GSM管理,其他GSM作为这个服务单元的热备份。如果因为某些原因GSM失败,则热备份中的一个GSM接管并启动管理和监控失败的GSM管理的处理单元。
The Lookup Service (LUS)
LUS是列出网络中所有可用运行组件(GSCs,GSMs)。当一个特定组件启动时,它首先会连接LUS并注册。通过LUS,GSM可以知道网络中所有运行的GSCs。 为了保持高可用,一般运行环境中存在2个LUS.注意,LUS可以运行在一个GSM下,或者在运行在自己的JVM独立模式下。默认情况下,其他组件使用jini多播协议查找LUS,如果多播在网络中不可用,则通过覆盖和LUS的显式地址来确定。这个上下文下另一个重要属性是lookup group。lookup group是一个同集群环境的所有组件的逻辑组。通过lookup group,可以运行相同物理基础设施下同一个运行单元的多个部署,而不互相干扰。
The Elastic Service Manager (ESM)
ESM和GSM一起管理 Elastic Processing Unit (弹性处理单元)。
ESM是一个Elastic Middleware Services High-Level Overview描述的特征的实现,它构建在Administration and Monitoring API暴露的GigaSpaces的组件,如果内置功能不适合你的需求,你可以重写自定义行为。
一种可能是使用暴露
Elastic Scale Handler钩子来扩展和收缩,一个自定义实现,例如可以发送警告触发手动进程来增加新机器。
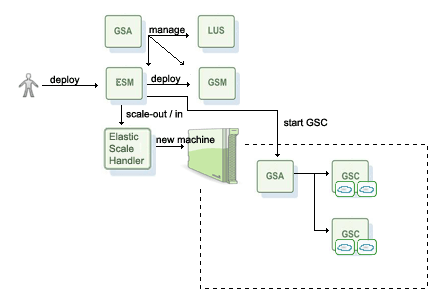
GSA管理LUS、GSM和ESM,ESM部署一个弹性data-grid部署,ESM和GSM同时工作 。部署过程转嫁到GSM来管理,ESM监控部署过程,执行弹性运行管理(自动伸缩,再均衡和增强SLAs)。ESM使用任何可用的机器,启动一个GSC来容纳部署请求。如果没有机器可用,它会请求扩张一个新机器。Elastic Scale Handler的实现来完成扩展一个新机器的过程。通过启动一个单独的GSA(no GSCs)来发现一个机器,在这个机器下,ESM将请求GSA来启动一个新的GSC,伸缩请求出现在部署折衷或违反SLA。
基本的设置最少由1一个GSA管理2个机器,其中一个GSA全局管理LUS、ESM和GSM。为了部署一个弹性data-grid服务,使用administrative API来定位和部署ESM。
默认Elastic Scale Handler钩子没有任何实现除了日志请求。当需要一个新机器时,简单运行一个GSA并且它会考虑空余资源。 我们展示一个例子来解释Elastic Scale Handler,通过网络发送SSH命令到空闲机器来启动代理。
ESM的日志级别由 org.openspaces.grid.esm的日志配置属性来控制<GigaSpaces>/config/gs_logging.properties
org.openspaces.grid.esm.level = INFO
可以通过管理界面Admin UI来访问不同组件的日志。
1. 基础设置
我们通过GSA来启动基本组件---ESM、LUS和GSM,所有这些组件被全局管理(这意味着,只要其中一个失败,GSA会自动启动一个新实例)
<GigaSpaces>/bin/gs-agent gsa.global.esm 1 gsa.gsc 0
gsa.global.esm 1 - 在同一lookup group/locators,通过服务网格代理全局管理一个ESM实例
gsa.gsc 0 - 将重写默认实现而不启动一个新的服务网格容器。原因很简单,ESM将随需求来启动对应数量的GSC,此外ESM启动分配特定区域的GSC。
注意:gsa.global.lus 2 gsa.global.gsm 2 gs-agent脚本默认忽略了,在同一lookup group/locators下通过GSA全局管理2个LUS和2个GSM。
2.部署一个弹性Data-grid
首先使用administrative API发现ESM
Admin admin = new AdminFactory().createAdmin();
ElasticServiceManager esm = admin.getElasticServiceManagers().waitForAtLeastOne();
一旦取得ESM实例,可以使用它来部署弹性data-grid
ProcessingUnit pu = esm.deploy( new ElasticDataGridDeployment("mygrid"));
等待部署
Space space = pu.getSpace(); space.waitFor(pu.getSpace().getTotalNumberOfInstances()); GigaSpace gigaSpace = space.getGigaSpace();
默认情况下,它会部署一个容量为1-10GB、名为mygrid的高可用data-grid,每个GSC使用512MB。这个请求会映射到10个分区集群(十个实例,每个备份一个),没有自动伸缩策略。这意味需要手动启动机器来实现增长。
3. 启动一个新机器
当需要一个新机器(要么是占据备份要么扩展),简单启动一个单独的代理。
<GigaSpaces>/bin/gs-agent gsa.gsc 0
注意我们使用gsa.gsc 0来重写默认实现,不启动新的GSC。
Data-Grid部署选项
Context Properties
可以在处理单元配置中重写所有${...}来修改上下文部署时属性,例如,部署一个镜像服务,需要指定一个集群属性。
new ElasticDataGridDeployment("mygrid") .addContextProperty("cluster-config.mirror-service.enabled", "true")
Capacity
内存容量通过两个参数来控制,一个最小容量,一个最大容量来限制伸缩范围,默认容量为1-10GB。
new ElasticDataGridDeployment("mygrid") .capacity("1g", "10g")
Heap Size
JVM初始和最大内存大小是GSC的JVM固定内存大小,默认情况下,每个初始和最大内存大小为512MB,分别使用-Xmn和-Xmx来指定。
new ElasticDataGridDeployment("mygrid") .initialJavaHeapSize("512m").maximumJavaHeapSize("512m")
VM input arguments
可以将额外的JVM参数传递给启动时的GSC
new ElasticDataGridDeployment("mygrid") .vmInputArgument("-XX:-PrintGC").vmInputArgument("-XX:SurvivorRatio=8")
Multi-Tenant
多用户控制共享和隔离部署,下面是支持的选项:
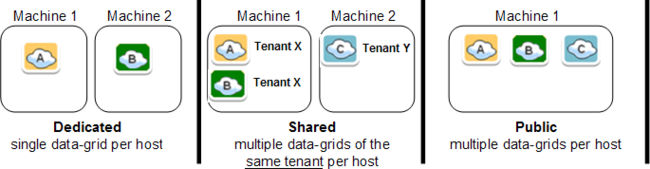
专用(Dedicated) - 限制部署data-grid不共享其他部署过程。 这个选项允许分配某个特定的部署data-grid最大资源数,不允许其他data-grid在同一个机器上部署,这是默认模式。
共享(Shared) - 同一个租户ID,允许data-grid部署和其他部署过程共享同一个机器的资源,这个选项允许同一个租户ID共享硬件资源
公共(Public) - 允许data-grid部署和其他部署过程共存,共享同一个机器的资源,这个选项允许利用硬件资源完成所有data-grid实例的部署,这个选项不会分配专用的资源完成特定的data-grid部署。
下面是怎样设置这些选项:
Dedicated
new ElasticDataGridDeployment("mygrid") .dedicatedDeploymentIsolation();
Shared (by tenant)
new ElasticDataGridDeployment("mygrid") .sharedDeploymentIsolation("tenant X");
Public
new ElasticDataGridDeployment("mygrid") .publicDeploymentIsolation();
Auto-Scale
内置扩展SLAs可以添加到部署中,例如,内存SLA,违反指定阈值会触发扩展。
Memory SLA
如果内存使用量超过阈值,实例要么迁移到另一个GSC(一个已存在的机器的新GSC),要么请求一个新的机器启动GSC。如果内存第一阈值,实例将迁移到另一个GSC,请求移除没有GSC的多余机器。
new ElasticDataGridDeployment("mygrid") .addSla(new MemorySla("75%"))
通过计算预定义子集平均大小得到内存使用量。默认情况,这个值为6,6个采样点,每隔5秒采样一次,总共展示30秒的窗口。这个子集的大小可以重写MemorySla结构体来配置。
new ElasticDataGridDeployment("mygrid") .addSla(new MemorySla("75%", 6))
![]() 为了更精确的统计内存,可以考虑安装Sigar,详细请看 "Using the SIGAR Library to Monitor Machine-Level Statistics"
为了更精确的统计内存,可以考虑安装Sigar,详细请看 "Using the SIGAR Library to Monitor Machine-Level Statistics"
High Availability
默认情况下集群是高可用的,每个分区一个备份是总容量的一部分。一个备份需要一个独立的机器来容灾。那么,需要至少2个可用机器来启动。
new ElasticDataGridDeployment("mygrid") .highlyAvailable(true)
Scale Handler
扩展处理器定义伸缩的方法。默认扩展处理器不采用任何措施,只是简单调用API输出日志。每个组件的部署都需要配置扩展处理器。
首先编写自定义方法来实现ElasticScaleHandler接口,属性可以在这个实现类部署期间传递。例如,可以指定哪些机器在这个处理池中。下面是MyElasticScaleHandler类获取机器列表。
new ElasticDataGridDeployment("mygrid") .elasticScaleHandler( new ElasticScaleHandlerConfig(MyElasticScaleHandler.class.getName()) .addProperty("machines", "lab-12,lab-13,lab-36,lab-37"))
ElasticScaleHandler(弹性扩展处理接口)由下面简单的API组成。
public void init(ElasticScaleConfig config);
public boolean accept(Machine machine);
public void scaleOut(ElasticScaleHandlerContext context);
public void scaleIn(Machine machine);
实现类和可能的使用到的jar都放在以下库文件夹:
<GigaSpace>/lib/platform/esm
参考Custom Elastic Scale Handler Example的具体实现,发送SSH命令启动在实验机器的代理。
Capacity planning
参考Capacity Planning了解有关容量规划和最好的实现的详细信息
Cluster Size
容量和堆内存等部署参数决定分区集群的大小。内存最大容量除以JVM最大容量得到分区数,如果实现高可用,分区数再除以2得到备份数,则总内存是请求的最大内存容量的一半。
例如,capacity("1g", "10g").maximumJavaHeapSize("512m").highlyAvailable(true) 产生10个分区的集群。
计算过程: (10 gigabytes)除以(512 megabytes) = 20 ==> 再除以2得到备份数= 10分区数(每个分区一个备份)
JVM Size
对32位系统,建议使用2GB堆内存;对于64位系统,推荐使用4-10GB堆内存。
对于性能优化,可以初始化堆内存为最大堆内存大小
Initial GSCs
为了满足初始化容量,启动最小数量的GSCs。最小内存容量大小除以最大JVM大小得到初始化GSCs内存大小。例如,1 gigabytes 除以512 megabytes的JVM内存大小,产生2个GSCs。
Maximum GSCs
最大内存容量除以最大JVM内存大小得到GSCs最大数。例如,最大容量10GB除以512MB的JVM大小,产生20个GSCs。
Scaling Factor
为了达到容量限制,每个GSC扩展一个实例。对于一个有10个分区的集群,即20个GSCs,每个GSC运行一个实例。GSCs的最大数除以GSCs的初始数得到扩展因子。扩展因子限制每个GSC中实例数。例如,一个10分区的集群,在同一个GSC里面不会启动超过10个实例。
Setting Partition Size
高级用户可以设置分区大小来覆盖默认的分区数计算值,在高可用的部署中表示主实例的个数。例如,设置分区数为5:
//Request to deploy mygrid 5,1 capacity: 1g - 2g - DEDICATED ProcessingUnit pu = esm.deploy(new ElasticDataGridDeployment("mygrid") .capacity("1g", "2g") .maximumJavaHeapSize("250m") .highlyAvailable(true) .setPartitions(5));
The Apache Loader-Balancer Agent (LBA)
LBA是部署web应用的一个可选组件
The Transaction Manager (TXM)
可选组件,当跨越多个分区空间执行事务,应该使用Jini事务管理器或分布式事务管理器