Linux Performance Analysis and Tools(Linux性能分析和工具)
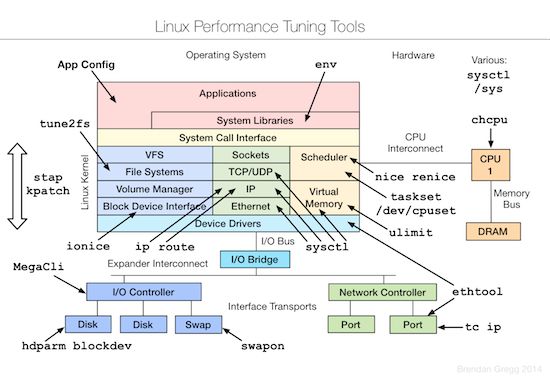
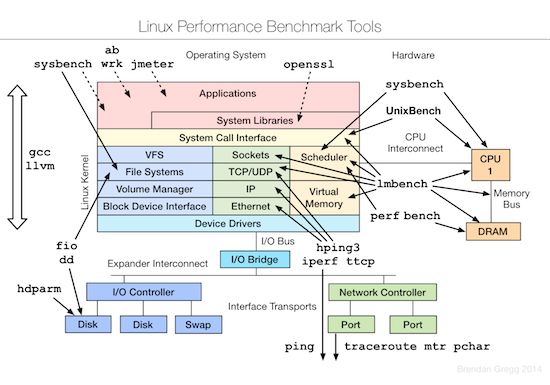
首先来看一张图: 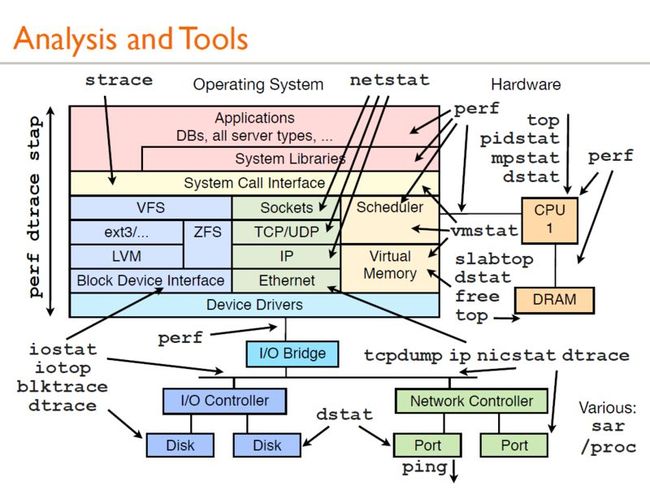
上面这张神一样的图出自国外一个Lead Performance Engineer(Brendan Gregg)的一次分享,几乎涵盖了一个系统的方方面面,任何人,如果没有完善的计算系统知识,网络知识和操作系统的知识,这张图中列出的工具,是不可能全部掌握的。
出于本人对linux系统的极大兴趣,以及对底层知识的强烈渴望,并作为检验自己基础知识的一个指标,我决定将这里的所有工具学习一遍(时间不限),这篇文章将作为我学习这些工具的学习笔记。尽量组织得方便自己日后查阅,并希望对别人也有一定帮助。
这里所有的工具,都可以通过man 获得它的帮助文档,这里只介绍一些常规用法。
注意:文中所有的interval都是指收集数据的间隔时间,times是指采样次数。例如
vmstat interval times
将命令中的interval和times替换成数字:
vmstat 3 5
上面语句的意思就是每3秒中输出一次内存统计数据,共输出5次。
Tools: Basic & Intermediate
- uptime
- top
- htop
- mpstat
- iostat
- vmstat
- dstat
- netstat
- strace
- iotop
- pidstat
- ps
- lsof
vmstat
我们先看一个vmstat 的例子。用下面的命令让它每5秒中打印一个报告。

可以用ctrl+c停止vmstat。vmstat的常规用法是vmstat interval times,即每隔interval秒采 样一次,共采样times次,如果省略times,则一直采集数据到用户手动停止。
第一行的值是显示了自系统启动以来的平均值,第二行开始展示现在正在发生的情况,接下来的行会显示每5秒的间隔内发生了什么。每一列的含义在头部,如下所示:
- procs
r这一列显示了多少进程正在等待cpu,b列显示多少进程正在不可中断的休眠(通常意味着它们在等待IO ,例如磁盘,网络,用户输入,等等)。
- memory
swapd列显示了多少块被换出到了磁盘(页面交换)。剩下的三个列显示了多少块是空闲的(未被使用),多少块正在被用作缓冲区,以及多少正在被用作操作系统的缓存。
- swap
这些列显示页面交换活动:每秒有多少块正在被换入(从磁盘)和换出(到磁盘)。它们比监控swpd列重要多了。大部分时间我们希望看到si 和so 列是0,并且我们很明确不希望看到每秒超过10个块。
- io
这些列显示了多少块从块设备读取(bi)和写出(bo)。这通常反映了硬盘I/O。
- system
这些列显示了每秒中断(in)和上下文切换(cs)的数量。除非上下文切换超过100 000次或更多,一般不用担心上下文切换。
- cpu
这些列显示所有的CPU时间花费在各类操作的百分比,包括执行用户代码(非内核),执行系统代码(内核),空闲以及等待IO。如果正在使用虚拟化,第5列可能是st,显示了从虚拟机中"偷走"的百分比。
内存不足的表现:free memory 急剧减少,回收buffer和cache也无济于事,大量使用交换分区(swpd),页面交换(swap)频繁,读写磁盘数量(io)增多,缺页中断(in)增多,上下文切换(cs)次数增多,等待IO的进程数(b)增多,大量CPU时间用于等待IO(wa)。
iostat
现在让我们转移到iostat 。默认情况下,它显示了与vmstat 相同的CPU 使用信息。我们通常只对I/O统计感兴趣,所以使用下面的命令只展示扩展的设备统计。

与vmstat一样,第一行报告显示的是自系统启动以来的平均值,(通常删掉它节省空间),然后接下来的报告显示了增量的平均值,每个设备一行。
有多种选项显示和隐藏列。官方文档有点难以理解,因此我们必须从源码中挖掘真正显示的内容是什么。说明的列信息如下:
为了看懂Linux的磁盘IO指标,先了解一些常见的缩写习惯:rq是request,r是read,w是write,qu是queue,sz是size的,a是average,tm是time,svc是service。
-
rrqm/s 和 wrqm/s
每秒合并的读和写请求。"合并的"意味着操作系统从队列中拿出多个逻辑请求合并为一个请求到实际磁盘。
-
r/s 和 w/s
每秒发送到设备的读和写请求数。
-
rsec/s 和 wsec/s
每秒读和写的扇区数。有些系统也输出为rKB/s和wKB/s ,意味每秒读写的千字节数。(iostat -dkx interval times)
-
avgrq-sz
请求的扇区数。(读扇区数 + 写扇区数) / (读请求次数 + 写请求次数)
-
avgqu-sz
在设备队列中等待的请求数。即队列的平均长度。
-
await
每个IO请求花费的时间,包括在队列中的等待时间和实际请求(服务)时间。
-
svctm
实际请求(服务)时间,以毫秒为单位,不包括排队时间。
-
%util
至少有一个活跃请求所占时间的百分比。更好的说法应该是,服务时间所占的百分比。以上面的输出为例。 一秒中内,读了2.5次,写了1.8次,每次请求的实际请求时间(不包括排队时间)为6.0ms,那么总的时间花费为(2.5+1.8)*6.0ms,即25.8ms,0.0258秒,转换成百分比再四舍五入就得到了util的值2.6%。
%util: When this figure is consistently approaching above 80% you will need to take any of the following actions -
- increasing RAM so dependence on disk reduces
- increasing RAID controller cache so disk dependence decreases
- increasing number of disks so disk throughput increases (more spindles working parallely)
- horizontal partitioning
下面这个公式可以计算一个请求在整个请求期间,有多少时间用以等待。当这个值大于50%,说明整个请求期间,花费了更多时间在队列中等待;如果这个数很大,则应该采取相应措施。
- (await-svctim)/await*100: The percentage of time that IO operations spent waiting in queue in comparison to actually being serviced. If this figure goes above 50% then each IO request is spending more time waiting in queue than being processed. If this ratio skews heavily upwards (in the >75% range) you know that your disk subsystem is not being able to keep up with the IO requests and most IO requests are spending a lot of time waiting in queue. In this scenario you will again need to take any of the actions above
IO瓶颈的症状: 1. %util 很高 2. await 远大于svctm 3. avgqu-sz 比较大
下面解释了iowait的作用,需要注意的是,高速CPU也可能导致iowait取值较大。
- %iowait: This number shows the % of time the CPU is wasting in waiting for IO. A part of this number can result from network IO, which can be avoided by using an Async IO library. The rest of it is simply an indication of how IO-bound your application is. You can reduce this number by ensuring that disk IO operations take less time, more data is available in RAM, increasing disk throughput by increasing number of disks in a RAID array, using SSD (Check my post on Solid State drives vs Hard Drives) for portions of the data or all of the data etc
上面的解释主要参考《高性能mysql》和这篇博客。
cpu 密集型机器
cpu 密集型服务器的vmstat 输出通常在us 列会有一个很高的值,报告了花费在非内核代码上的cpu 时钟;也可能在sy 列有很高的值,表示系统cpu 利用率,超过20% 就足以令人不安了。在大部分情况下,也会有进程队列排队时间(在r列报告的)。下面是一个列子:

如果我们在同一台及其上观察iostat 的输出(再次剔除显示启动以来平均值的第一行),可以发现磁盘利用率低于50%:

这台机器不是IO密集型的,但是依然有相当数量的IO发生,在数据库服务器中这种情况很少见。另一方面,传统的Web 服务器会消耗掉大量的CPU 资源,但是很少发生IO,所以Web 服务器的输出不会像这个例子。
IO 密集型机器
在IO密集型工作负载下,CPU花费大量时间在等待IO请求完成。这意味着vmstat 会显示很多处理器在非中断休眠(b列)状态,并且在wa 这一列的值很高,下面是个例子:

这台机器的iostat 输出显示硬盘一直很忙:

%util的值可能因为四舍五入的错误超过100%。什么迹象意味着机器是IO密集的呢?只要有足够的缓冲来服务写请求,即使机器正在做大量的写操作,也可能可以满足,但是却通常意味着硬盘可能会无法满足读请求。这听起来好像违反直觉,但是如果思考读和写的本质,就不会这么认为了:
- 写请求能够缓冲或同步操作。
- 读请求就其本质而言都是同步的。当然,程序可以猜测到可能需要某些数据,并异步地提前读取(预读)。无论如何,通常程序在继续工作前必须得到它们需要的数据。这就强制读请求为同步操作:程序必须阻塞直到请求完成。
想想这种方式:你可以发出一个写请求到缓冲区的某个地方,然后过一会完成。甚至可以每秒发出很多这样的请求。如果缓冲区正确工作,并且有足够的空间,每个请求都可以很快完成,并且实际上写到物理硬盘是被重新排序后更有效地批量操作的。然而,没有办法对读操作这么做————不管多小或多少的请求,都不可能让硬盘响应说:"这是你的数据,我等一会读它"。这就是为什么读需要IO等待是可以理解的原因。
发生内存交换的机器
一台正在发生内存交换的机器可能在swpd 列有一个很高的值,也可能不高。但是可以看到si 和 so 列有很高的值,这是我们不希望看到的。下面是一台内存交换严重的机器的vmstat 输出:

空闲的机器
下面是一台空闲机器上的vmstat输出。可以看到idle列显示CPU是100%的空闲。

dstat
dstat 显示了cpu使用情况,磁盘io 情况,网络发包情况和换页情况。
个人觉得,iostat和vmstat 的输出虽然详细,但是不够直观,不如dstat 好用。而且,dstat输出是彩色的,可读性更强。现在dstat作为我首选的,查看系统状态的工具。
dstat使用时,直接输入命令即可,不用任何参数。也可以通过指定参数来显示更加详细的信息。
dstat -cdlmnpsy
iotop
通过iostat和dstat我们可以知道系统的当前IO负载,但是IO负载具体是由哪个进程产生的呢?这时候我们需要的是iotop.
iotop是一个用来监视磁盘I/O使用状况的top类工具,具有与top相似的UI,其中包括PID、用户、I/O、进程等相关信息。 iotop使用Python语言编写而成,要求Python 2.5(及以上版本)和Linux kernel 2.6.20(及以上版本)。使用非常简单,在此不做过多介绍,详细信息参见官网:http://guichaz.free.fr/iotop/
这个命令也可以以非交互的方式使用:
iotop -bod interval
查看每个进程的IO,也可以通过pidstat命令,不像iotop,且pidstat还不需要root权限。
pidstat -d interval
pidstat
了解系统IO的情况大多数是通过iostat来获取的,这个粒度只能精确到每个设备。通常我们会想了 解每个进程,线程层面发起了多少IO,在Linux 2.6.20之前除了用systemtap这样的工具来实现 是没有其他方法的,因为系统没有暴露这方面的统计。现在可以通过一个名为pidstat的工具, 它的使用方法如下:
pidstat -d interval
此外,pidstat 还可以用以统计CPU使用信息。
pidstat -u interval
统计内存信息:
pidstat -r interval
top
top 命令的汇总区域显示了五个方面的系统性能信息: 1. 负载:时间,登录用户数,系统平均负载 2. 进程:运行,睡眠,停止,僵尸 3. CPU :用户态,核心态,NICE,空闲,等待IO,中断等 4. 内存:总量,已用,空闲(系统角度),缓冲,缓存 5. 交换分区:总量,已用,空闲
任务区域默认显示:进程ID,有效用户,进程优先级,NICE值,进程使用的虚拟内存,物理内存和共享内存,进程状态,CPU 占用率,内存占用率,累计CPU时间,进程命令行信息。
htop
另一个更好用的top的替代工具是htop,htop是Linux系统中的一个互动的进程查看器,一个文本模式的应用程序(在控制台或者X终端中),需要ncurses。
与Linux传统的top相比,htop更加人性化。它可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
与top相比,htop有以下优点:
- 可以横向或纵向滚动浏览进程列表,以便看到所有的进程和完整的命令行。
- 在启动上,比top 更快。
- 杀进程时不需要输入进程号。
- htop 支持鼠标操作。
参考资料:Linux下取代top的进程管理工具 htop
mpstat
mpstat 用来统计多核处理器中,每一个处理器的使用情况。mpstat使用方法很简单,常见用法如下:
mpstat -P ALL interval times
不出意外,读者执行上面的命令,看不出个所以然来,试试在运行下面这条命令的同时,查看mpstat的输出。
sysbench --test=cpu --cpu-max-prime=20000 run
注意:sysbench是一个基准测试工具,可以用来测试cpu,io,mutex,oltp等。在Debain系统下, 通过下面的命令安装:
sudo apt-get install sysbench
netstat
netstat用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况。
就我自己而言,经常使用的用法如下:
netstat -npl
上面这条命令可以查看你要打开的端口是否已经打开,以此来作为程序是否已经启动的依据。
netstat 还有很多其他的用法,在《TCP/IP详解》一书中,作者喜欢用netstat命令来打印路由表,使用方法如下:
netstat -rn
其中,flag域的解释如下:
- U 该路由可用
- G 该路由是到一个到网关(路由器)。如果没有设置该标志,说明目的地址是直接相连的
- H 该路由是到一个主机
- D 该路由是由重定向报文创建
- M 该路由已被重定向报文修改
netstat 也可以提供系统上的接口信息:
netstat -in
这个命令打印每个接口的MTU,输入分组数,输入错误,输出分组数,输出错误,冲突以及当前的输出队列的长度。
ps
最最常用的用法
ps aux #BSD ps -ef #linux
ps 参数太多,具体使用方法,请man ps,下面是两种相对常用的使用方式。
-
杀掉某一程序的方法。
ps aux | grep mysqld | grep -v grep | awk '{ print $2 }' | xargs kill -9 -
杀掉僵尸进程:
ps -eal | awk '{ if ($2 == "Z" ){ print $4}}' | xargs kill -9
strace
用我自己的理解来介绍strace:
我们写程序,会调用很多库函数,而这些库函数,只是对系统调用的封装,它们最后都会去调用操作系统提供的系统调用,通过系统调用去访问硬件设备。strace的作用就是显示出这些调用关系,让程序员知道调用一个函数,它到底做了些什么事情。当然,strace 远比上面的介绍灵活多变。
下面来看一个例子:
查看mysqld 在linux上加载哪种配置文件,可以通过运行下面的命令行:
strace -e stat64 mysqld --print-defaults > /dev/null
strace太强大,内容也太多了,我找到一篇比较好的,介绍strace的文章,请点击这里。
uptime
uptime是最最最最简单的工具了,但是也有值得讨论的地方,那就是它最后输出的三个数字是怎么得来的,有什么含义?
这三个数字的含义分别是1分钟、5分钟、15分钟内系统的平均负荷,关于这些数字的含义和由来,推荐看阮一峰的文章《理解linux系统负荷这里》。
我想说的是,这三个数字我天天看,时时看,但是我从来不相信它。
此话怎讲呢?我之所以天天看,时时看,是因为我将这三个数字显示到了tmux 的状态栏上,所以,我任何时候都可以看到,而不用专门输入uptime这个命令。
为什么我不相信它呢,因为这几个数字只能说明有多少线程在等待cpu,如果我们的一个任务有很多线程,系统负载不是特别高,但是这几个数字会出奇的高,也就是不能完全相信uptime的原因。如果不信,可以执行下面这条语句,然后再看看uptime的输出结果。
sysbench --test=mutex --num-threads=1600 --mutex-num=2048 --mutex-locks=1000000 --mutex-loops=5000 run
运行了5分钟以后,我的电脑上输出如下所示。需要强调的是,这个时候电脑一点不卡,看uptime来判断系统负载,跟听cpu风扇声音判断系统负载一样。只能作为线索,不能作为系统负载很高的依据。
20:32:39 up 10:21, 4 users, load average: 386.53, 965.37, 418.57
《Linux Performance Analysis and Tools》里面也说了,This is only useful as a clue. Use other tools to investigate!
lsof
lsof(list open files)是一个列出当前系统打开文件的工具。在linux环境下,任何事物都以 文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。所以如传输 控制协议(TCP)和用户数据报协议(UDP)套接字等,系统在后台都为该应用程序分配了一个文件描 述符,无论这个文件的本质如何,该文件描述符为应用程序与基础操作系统之间的交互提供了 通用接口。因为应用程序打开文件的描述符列表提供了大量关于这个应用程序本身的信息,因此 通过lsof工具能够查看这个列表对系统监测以及排错将是很有帮助的。
lsof 的使用方法可以参考这里。这里仅列出几种常见的用法。
-
查看文件系统阻塞 lsof /boot
-
查看端口号被哪个进程占用 lsof -i :3306
-
查看用户打开哪些文件 lsof -u username
-
查看进程打开哪些文件 lsof -p 4838
-
查看远程已打开的网络链接 lsof -i @192.168.34.128
参考资料:
- 《Linux常用监控命令介绍》
- 《使用lsof查找打开的文件》
测试
调优