基于 Hive 的文件格式:RCFile 简介及其应用
Hadoop 作为MR 的开源实现,一直以动态运行解析文件格式并获得比MPP数据库快上几倍的装载速度为优势。不过,MPP数据库社区也一直批评Hadoop由于文件格式并非为特定目的而建,因此序列化和反序列化的成本过高。
1、hadoop 文件格式简介
目前 hadoop 中流行的文件格式有如下几种:
(1)SequenceFile
SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。它与Hadoop API中的MapFile 是互相兼容的。Hive 中的SequenceFile 继承自Hadoop API 的SequenceFile,不过它的key为空,使用value 存放实际的值, 这样是为了避免MR 在运行map 阶段的排序过程。如果你用Java API 编写SequenceFile,并让Hive 读取的话,请确保使用value字段存放数据,否则你需要自定义读取这种SequenceFile 的InputFormat class 和OutputFormat class。
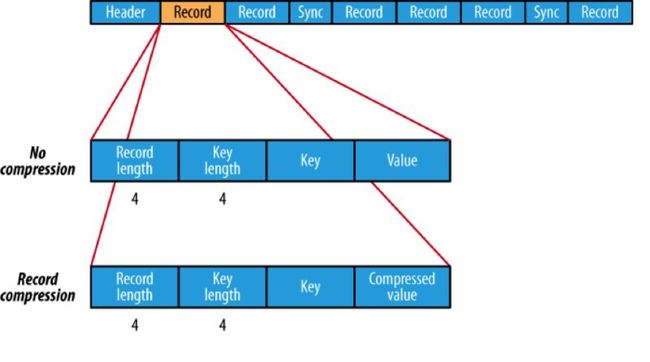
(2)RCFile
RCFile是Hive推出的一种专门面向列的数据格式。 它遵循“先按列划分,再垂直划分”的设计理念。当查询过程中,针对它并不关心的列时,它会在IO上跳过这些列。需要说明的是,RCFile在map阶段从远端拷贝仍然是拷贝整个数据块,并且拷贝到本地目录后RCFile并不是真正直接跳过不需要的列,并跳到需要读取的列, 而是通过扫描每一个row group的头部定义来实现的,但是在整个HDFS Block 级别的头部并没有定义每个列从哪个row group起始到哪个row group结束。所以在读取所有列的情况下,RCFile的性能反而没有SequenceFile高。
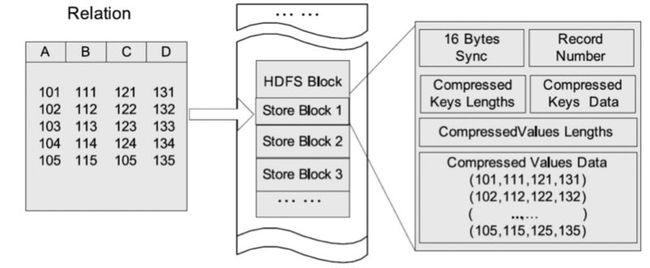
HDFS块内行存储的例子
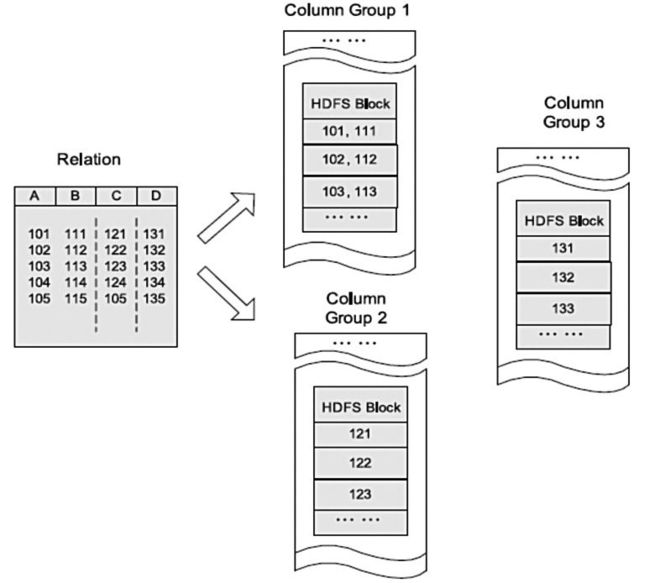
HDFS块内列存储的例子
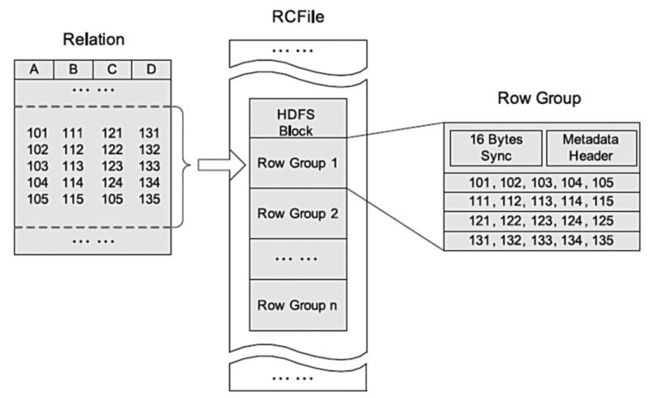
HDFS块内RCFile方式存储的例子
(3)Avro
Avro是一种用于支持数据密集型的二进制文件格式。它的文件格式更为紧凑,若要读取大量数据时,Avro能够提供更好的序列化和反序列化性能。并且Avro数据文件天生是带Schema定义的,所以它不需要开发者在API 级别实现自己的Writable对象。最近多个Hadoop 子项目都支持Avro 数据格式,如Pig 、Hive、Flume、Sqoop和Hcatalog。

(4)文本格式
除上面提到的3种二进制格式之外,文本格式的数据也是Hadoop中经常碰到的。如TextFile 、XML和JSON。 文本格式除了会占用更多磁盘资源外,对它的解析开销一般会比二进制格式高几十倍以上,尤其是XML 和JSON,它们的解析开销比Textfile 还要大,因此强烈不建议在生产系统中使用这些格式进行储存。 如果需要输出这些格式,请在客户端做相应的转换操作。 文本格式经常会用于日志收集,数据库导入,Hive默认配置也是使用文本格式,而且常常容易忘了压缩,所以请确保使用了正确的格式。另外文本格式的一个缺点是它不具备类型和模式,比如销售金额、利润这类数值数据或者日期时间类型的数据,如果使用文本格式保存,由于它们本身的字符串类型的长短不一,或者含有负数,导致MR没有办法排序,所以往往需要将它们预处理成含有模式的二进制格式,这又导致了不必要的预处理步骤的开销和储存资源的浪费。
(5)外部格式
Hadoop实际上支持任意文件格式,只要能够实现对应的RecordWriter和RecordReader即可。其中数据库格式也是会经常储存在Hadoop中,比如Hbase,Mysql,Cassandra,MongoDB。 这些格式一般是为了避免大量的数据移动和快速装载的需求而用的。他们的序列化和反序列化都是由这些数据库格式的客户端完成,并且文件的储存位置和数据布局(Data Layout)不由Hadoop控制,他们的文件切分也不是按HDFS的块大小(blocksize)进行切割。
2、为什么需要 RCFile
Facebook曾在2010 ICDE(IEEE International Conference on Data Engineering)会议上介绍了数据仓库Hive。Hive存储海量数据在Hadoop系统中,提供了一套类数据库的数据存储和处理机制。它采用类SQL语言对数据进行自动化管理和处理,经过语句解析和转换,最终生成基于Hadoop的MapReduce任务,通过执行这些任务完成数据处理。下图显示了Hive数据仓库的系统结构。
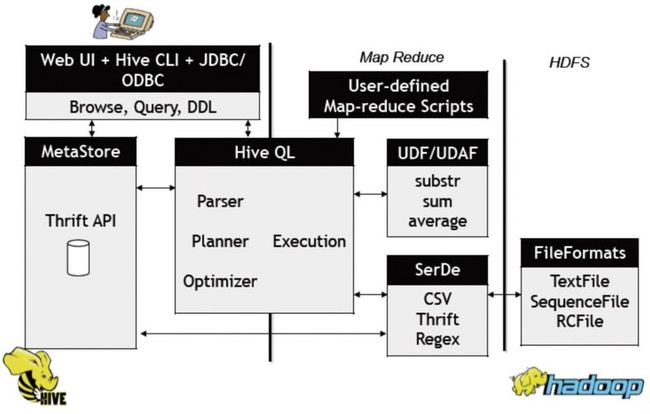
Facebook在数据仓库上遇到的存储可扩展性的挑战是独一无二的。他们在基于Hive的数据仓库中存储了超过300PB的数据,并且以每日新增600TB的速度增长。去年这个数据仓库所存储的数据量增长了3倍。考虑到这个增长趋势,存储效率问题是facebook数据仓库基础设施方面目前乃至将来一段时间内最需要关注的。facebook工程师发表的RCFile: A Fast and Spaceefficient Data Placement Structure in MapReducebased Warehouse Systems一文,介绍了一种高效的数据存储结构——RCFile(Record Columnar File),并将其应用于Facebook的数据仓库Hive中。与传统数据库的数据存储结构相比,RCFile更有效地满足了基于MapReduce的数据仓库的四个关键需求,即Fast data loading、Fast query processing、Highly efficient storage space utilization和Strong adaptivity to highly dynamic workload patterns。RCFile 广泛应用于Facebook公司的数据分析系统Hive中。首先,RCFile具备相当于行存储的数据加载速度和负载适应能力;其次,RCFile的读优化可以在扫描表格时避免不必要的列读取,测试显示在多数情况下,它比其他结构拥有更好的性能;再次,RCFile使用列维度的压缩,因此能够有效提升存储空间利用率。
为了提高存储空间利用率,Facebook各产品线应用产生的数据从2010年起均采用RCFile结构存储,按行存储(SequenceFile/TextFile)结构保存的数据集也转存为RCFile格式。此外,Yahoo公司也在Pig数据分析系统中集成了RCFile,RCFile正在用于另一个基于Hadoop的数据管理系统Howl(http://wiki.apache.org/pig/Howl)。而且,根据Hive开发社区的交流,RCFile也成功整合加入其他基于MapReduce的数据分析平台。有理由相信,作为数据存储标准的RCFile,将继续在MapReduce环境下的大规模数据分析中扮演重要角色。
3、RCFile 简介
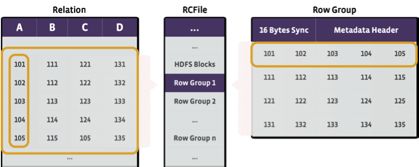
facebook 的数据仓库中数据被加载到表里面时首先使用的存储格式是Facebook自己开发的Record-Columnar File Format(RCFile)。RCFile是一种“允许按行查询,提供了列存储的压缩效率”的混合列存储格式。它的核心思想是首先把Hive表水平切分成多个行组(row groups),然后组内按照列垂直切分,这样列与列的数据在磁盘上就是连续的存储块了。
当一个行组内的所有列写到磁盘时,RCFile就会以列为单位对数据使用类似zlib/lzo的算法进行压缩。当读取列数据的时候使用惰性解压策略( lazy decompression),也就是说用户的某个查询如果只是涉及到一个表中的部分列的时候,RCFile会跳过不需要的列的解压缩和反序列化的过程。通过在facebook的数据仓库中选取有代表性的例子实验,RCFile能够提供5倍的压缩比。
4、超越RCFile,下一步采用什么方法
随着数据仓库中存储的数据量持续增长,FB组内的工程师开始研究提高压缩效率的技术和方法。研究的焦点集中在列级别的编码方法,例如行程长度编码(run-length encoding)、词典编码(dictionary encoding)、参考帧编码(frame of reference encoding)、能够在通用压缩过程之前更好的在列级别降低逻辑冗余的数值编码方法。FB也尝试过新的列类型(例如JSON是在Facebook内部广泛使用的格式,把JSON格式的数据按照结构化的方式存储既可以满足高效查询的需求,同时也降低了JSON元数据存储的冗余)。FB的实验表明列级别的编码如果使用得当的话能够显著提高RCFile的压缩比。
与此同时,Hortonworks也在尝试类似的思路去改进Hive的存储格式。Hortonworks的工程团队设计和实现了ORCFile(包括存储格式和读写接口),这帮助Facebook的数据仓库设计和实现新的存储格式提供了一个很好的开始。
关于 ORCFile 的介绍请见这里:http://yanbohappy.sinaapp.com/?p=478
关于性能评测,笔者这里暂时没有条件,贴一张某次 hive 技术峰会演讲嘉宾的截图:

5、如何生成 RCFile 文件
上面说了这么多,想必你已经知道 RCFile 主要用于提升 hive 的查询效率,那如何生成这种格式的文件呢?
(1)hive 中直接通过textfile表进行insert转换
例如:
insert overwrite table http_RCTable partition(dt='2013-09-30') select p_id,tm,idate,phone from tmp_testp where dt='2013-09-30';
(2)通过 mapreduce 生成
目前为止,mapreduce 并没有提供内置 API 对 RCFile 进行支持,倒是 pig、hive、hcatalog 等 hadoop生态圈里的其他项目进行了支持,究其原因是因为 RCFile 相比 textfile 等其它文件格式,对于 mapreduce 的应用场景来说没有显著的优势。
为了避免重复造轮子,下面的生成 RCFile 的 mapreduce 代码调用了 hive 和 hcatalog 的相关类,注意你在测试下面的代码时,你的 hadoop、hive、hcatalog 版本要一致,否则。。。你懂的。。。

比如我用的 hive-0.10.0+198-1.cdh4.4.0,那么就应该下载对应的版本:http://archive.cloudera.com/cdh4/cdh/4/
PS:下面的代码已经测试通过,木有问题。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hive.serde2.columnar.BytesRefArrayWritable;
import org.apache.hadoop.hive.serde2.columnar.BytesRefWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hcatalog.rcfile.RCFileMapReduceInputFormat;
import org.apache.hcatalog.rcfile.RCFileMapReduceOutputFormat;
public class TextToRCFile extends Configured implements Tool{
public static class Map
extends Mapper<Object, Text, NullWritable, BytesRefArrayWritable>{
private byte[] fieldData;
private int numCols;
private BytesRefArrayWritable bytes;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
numCols = context.getConfiguration().getInt("hive.io.rcfile.column.number.conf", 0);
bytes = new BytesRefArrayWritable(numCols);
}
public void map(Object key, Text line, Context context
) throws IOException, InterruptedException {
bytes.clear();
String[] cols = line.toString().split("\\|");
System.out.println("SIZE : "+cols.length);
for (int i=0; i<numCols; i++){
fieldData = cols[i].getBytes("UTF-8");
BytesRefWritable cu = null;
cu = new BytesRefWritable(fieldData, 0, fieldData.length);
bytes.set(i, cu);
}
context.write(NullWritable.get(), bytes);
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if(otherArgs.length < 2){
System.out.println("Usage: " +
"hadoop jar RCFileLoader.jar <main class> " +
"-tableName <tableName> -numCols <numberOfColumns> -input <input path> " +
"-output <output path> -rowGroupSize <rowGroupSize> -ioBufferSize <ioBufferSize>");
System.out.println("For test");
System.out.println("$HADOOP jar RCFileLoader.jar edu.osu.cse.rsam.rcfile.mapreduce.LoadTable " +
"-tableName test1 -numCols 10 -input RCFileLoaderTest/test1 " +
"-output RCFileLoaderTest/RCFile_test1");
System.out.println("$HADOOP jar RCFileLoader.jar edu.osu.cse.rsam.rcfile.mapreduce.LoadTable " +
"-tableName test2 -numCols 5 -input RCFileLoaderTest/test2 " +
"-output RCFileLoaderTest/RCFile_test2");
return 2;
}
/* For test
*/
String tableName = "";
int numCols = 0;
String inputPath = "";
String outputPath = "";
int rowGroupSize = 16 *1024*1024;
int ioBufferSize = 128*1024;
for (int i=0; i<otherArgs.length - 1; i++){
if("-tableName".equals(otherArgs[i])){
tableName = otherArgs[i+1];
}else if ("-numCols".equals(otherArgs[i])){
numCols = Integer.parseInt(otherArgs[i+1]);
}else if ("-input".equals(otherArgs[i])){
inputPath = otherArgs[i+1];
}else if("-output".equals(otherArgs[i])){
outputPath = otherArgs[i+1];
}else if("-rowGroupSize".equals(otherArgs[i])){
rowGroupSize = Integer.parseInt(otherArgs[i+1]);
}else if("-ioBufferSize".equals(otherArgs[i])){
ioBufferSize = Integer.parseInt(otherArgs[i+1]);
}
}
conf.setInt("hive.io.rcfile.record.buffer.size", rowGroupSize);
conf.setInt("io.file.buffer.size", ioBufferSize);
Job job = new Job(conf, "RCFile loader: loading table " + tableName + " with " + numCols + " columns");
job.setJarByClass(TextToRCFile.class);
job.setMapperClass(Map.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(BytesRefArrayWritable.class);
// job.setNumReduceTasks(0);
FileInputFormat.addInputPath(job, new Path(inputPath));
job.setOutputFormatClass(RCFileMapReduceOutputFormat.class);
RCFileMapReduceOutputFormat.setColumnNumber(job.getConfiguration(), numCols);
RCFileMapReduceOutputFormat.setOutputPath(job, new Path(outputPath));
RCFileMapReduceOutputFormat.setCompressOutput(job, false);
System.out.println("Loading table " + tableName + " from " + inputPath + " to RCFile located at " + outputPath);
System.out.println("number of columns:" + job.getConfiguration().get("hive.io.rcfile.column.number.conf"));
System.out.println("RCFile row group size:" + job.getConfiguration().get("hive.io.rcfile.record.buffer.size"));
System.out.println("io bufer size:" + job.getConfiguration().get("io.file.buffer.size"));
return (job.waitForCompletion(true) ? 0 : 1);
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new TextToRCFile(), args);
System.exit(res);
}
}
6、Refer:
(1)浅析Hadoop文件格式 http://www.infoq.com/cn/articles/hadoop-file-format
(2)Facebook数据仓库揭秘:RCFile高效存储结构 http://www.csdn.net/article/2011-04-29/296900
(3)Facebook的数据仓库是如何扩展到300PB的 http://yanbohappy.sinaapp.com/?p=478
(4)Hive架构 http://www.jdon.com/bigdata/hive.html
(5)Hive:ORC File Format存储格式详解 http://www.iteblog.com/archives/1014
(6)普通文本压缩成RcFile的通用类 https://github.com/ysmart-xx/ysmart/blob/master/javatest/TextToRCFile.java
http://hugh-wangp.iteye.com/blog/1405804 基于HIVE文件格式的map reduce代码编写
http://smallboby.iteye.com/blog/1596776 普通文本压缩成RcFile的通用类
http://smallboby.iteye.com/blog/1592531 RcFile存储和读取操作
https://github.com/kevinweil/elephant-bird/blob/master/rcfile/src/main/java/com/twitter/elephantbird/mapreduce/output/RCFileOutputFormat.java
http://blog.csdn.net/liuzhoulong/article/details/7909863