竞价广告系统-广告检索
广告检索
在前面谈到合约式广告时没有讨论广告检索的问题,虽然合约式广告也有检索的问题,但合约式广告一般数量非常小,只有千的级别,不需要特别的检索技术。但在广告网络中,比如google的广告数在百万级别。广告的检索问题有其独特的地方,下面我们讨论两点。
1. 布尔表达式检索,2. 长Query,它在上下文广告时会用到。
广告投放条件过滤可以视为布尔表达式检索问题。它不同于web搜索中关键词的搜索。比如广告主投放条件可能是年龄属于第三年龄段,地区是纽约,或是地区是加州,性别是男性的用户。可以用(age∈{3}^state∈{NY})∨(state∈{CA}^gender∈{M})表示。广告定向条件的DNF是一组或的条件,即某种定向条件或是某种定向条件下,广告可以展示。DNF可以分解成Conjunction, Conjunction是按或的方式分开,并且同一定向条件在某Conjunction里只出现一次,比如上面的例子就可以分解age∈{3}^state∈{NY}和state∈{CA}^gender∈{M},这里state在两个Conjunction中就各出现了一次。Assignment是一组属性名称和值的集合{A1=v1, A2=v2, …},比如一个在加州的女性用户可能就有{gender=F, state=CA}的assignment,sizeof[Conjuction]是conjunction中∈的个数。这个是比较重要的一个定义,实际意义是一个广告的其中的定向条件个数。在上例的age∈{3}^state∈{NY}中,那么如果你的查询只有一个条件时,那么这个条件不可能满足这个定向条件,那么在检索的过程中可以借助这种方式进行一定的加速。Yahoo!的GD广告就是用的这种检索方式。
Index Boolean Expression论文中的基本思想是某查询满足conjunction,也就满足包含此conjunction的doc。索引维护两层倒排关系,Conjunction->DocId和Assignment->ConjunctionId,Conjunction->DocId是普通的倒排索引,Assigment->ConjunctionId可会考虑sizeof(Conjunction),如果sizeof(Conjunction)大于sizeof(query),则无需考虑。
Index算法
建立第一层 Index
遍历文档DNF的Conjunction,如果为新的,则分配一个新ID(从0递增),否则用之前分配的ConjunctionID;文档分配DocID(从0递增);写入conjunction到doc的倒排关系,形成第一层Index。
对于上步出现的新Conjunction,建立第二层 Index
l 将Conjunction切成Assignment流,Term为(属性, 值),例: age ∈ {3;4}切成两个Term: (age, 3), (age, 4);state ? {CA;NY}也切成两个Term: (state, CA), (state, NY),?和∈体现在倒排链表上
l 计算Conjunction的size,将size体现在Term中,最终的Term的组成是(sizeof[Conjunction], 属性, 值)
l 对于size为0的Conjunction,添加一个特殊的Term:Z,∈
l 写入倒排关系, Term -> (ConjunctionID, ∈| ?)+
布尔表达式检索-index示例
下面是描述成DNF形式的广告集合。
doc1 = (age∈{3}^state∈{NY})∨(state∈{CA}^gender∈{M})=c1∨c4
doc2 = (age∈{3}^state∈{F})∨(state?{CA;NY})=c2∨c6
doc3 = (age∈{3}^gender∈{M}^state?{CA})∨(state∈{CA}^gender∈{F})=c3∨c7
doc4 = (age∈{3;4})∨(state∈{CA}^gender∈{M})=c5∨c4
doc5 = (state?{CA;NY})∨(age∈{3;4})=c6∨c5
doc7 = (age∈{3}^state∈{NY})∨(state∈{CA}^gender∈{F})=c1∨c7
doc6 = (state?{CA;NY})∨(age∈{3}^state∈{NY})∨(state∈{CA}^gender∈{M})= c6∨c1∨c4
第一层倒排(conjunction->DocId)
c1 -> doc-1, doc-6, doc-7
c2 -> doc-2
c3 -> doc-3
c4 -> doc-1, doc-4, doc-7
c5 -> doc-4, doc-5
c6 -> doc-2, doc-5, doc-7
c7 -> doc-3, doc-6
比如c1这个conjuction在doc-1,doc-6,doc-7中都有,所以c1的posting list就是这样的,这个倒排是为了得到广告的目的,比较简单。
第二层倒排(assignment->conjunction),它首先按size进行划分,0表示size=0的conjunction组成的倒排表,它里面只有不属于的情况,1表示conjunction只有一个属于的情况。以此类推。
在检索的时候,先查看sizeof(query),即查询中有几个定向条件,仅当查询的定向条件少于广告的定向条件时,才会查找广告,否则不用查找,这样可以减少查找的工作量。
长Query
做上下文广告时会用到,从要投放的页面中提取标签,到广告集合中匹配相应的广告,标签可能有几十到上百个,但这么多的标签对搜索引擎检索是很大的挑战。但所有的关键词都是Should的关系。它们即不是AND的关系,如果是AND的关系,可能根本就检索不到广告,也不是OR的关系,OR的关系会检索出大量的文档,对后面做相关性造成很大的压力。
传统搜索引擎中需需要将所有出现过以上Term的文档都取出来,然后计算相关性并找到Top-N,在长Query和大文档集时查询速度被巨大的计算量所限制,并且最终的效果也不会很好,Top-N中N的取值如果太大会给后续计算产生很大的压力,如果N太小可能会将一些优质的广告丢弃了。
一种可选的思路是:在查找候选DOC的过程中做一个近似的评估,切掉那些理论上不需要再考虑的文档,只对进候选的文档进行相关性计算,比Top-N最小堆最小值大的插入。理论上不需要再考虑的文档是由一个相关性函数来决定,相关性函数会判断一个query和一个文档的相关程度,当相当性函数为线性时,存在有效的剪枝算法。对于相关性函数是线性这个问题,大家不要太苛求,很显然在后续计算相关性时,不一定用线性函数,比如最常用的cosine distance也不是线性函数,但如果你使用相对合理的线性评价函数,使得retrieval的过程变得很有效,那么对ranking阶段的速度是很有帮助的。所以这种思路的核心是在线性函数的限制下找到一个相对合理的相关性函数。
Weight-And(WAND)检索算法
在个人使用WAND算法中感觉WAND算法很有效,并且很有启发意义。前面提到过要定义文档和Query的相似度函数,用这个函数来进行剪枝,剪枝的目的是使得在Query很长的情况下,能够用少的TopN将优质的广告覆盖。我们用一个比较简单的函数:
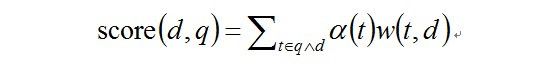
公式中score就是相似度函数,d是文档,q是查询,t是查询和文档中都有的term,alpha是t的一个权重,比如IDF,w(t,d)是t和d的一个权重。
WAND算法的关键是定义了Term贡献度的上界ub(upper bound):
![]()
ub是指一个term t在所有的文档d中,贡献的最大值ub(t)。
文档相关性上界UB公式是:
![]()
利用ub和UB,可以进行大量的剪枝。