JIT动态编译器的原理与实现之Interpreter(解释器)的实现(三)
接下来,就是要实现一个虚拟机了。记得编码高质量的代码中有一条:不要过早地优化你的代码。所以,也本着循序渐进的原则,我将从实现一个解释器开始,逐步过渡到JIT动态编译器,这样的演化可以使原理看起来更清晰。
解释器的原理很简单,就是一条指令一条指令的解释并执行。具体流程分为:取出指令-解码指令-执行-返回主流程。这样形成一个无限循环,如下图所示:
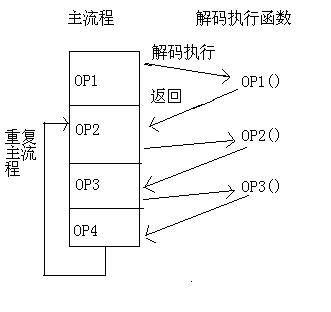
这里的主流程就是上篇定义的程序rom.bin。但rom.bin不能直接运行,需要一个解释器来包裹它,来解释执行。解释器放在一个无限循环中,使得主流程无限运行不停止:
void loop()
{
for(;;)
{
Interpreter(&CPUREG);
}
}
这样,整个虚拟机的运行可以定义为:
memInit(); //初始化内存
ResetCPU(&CPUREG); //初始化CPU
loadROM(); //加载rom.bin
loop(); //执行主流程
memFree(); //释放内存
接下来需要做的就是取出指令送入解释器了。为此需要定义读写内存的函数memGet和memSet:
void memSet(unsigned int, unsigned char);
unsigned char memGet(unsigned int);
void memSet(unsigned int addr, unsigned char data)
{
char Str_Err[256];
if(addr>64)
{
sprintf(Str_Err, "MEM: invalid mem write: 0x%8x", addr);
MessageBox(NULL, Str_Err, "Warning", MB_OK);
}
else
{
RAM[addr & 0xff]=data;
}
}
unsigned char memGet(unsigned int addr)
{
char Str_Err[256];
unsigned char val = 0;
if(addr>64)
{
sprintf(Str_Err, "MEM: invalid mem read: 0x%8x", addr);
MessageBox(NULL, Str_Err, "Warning", MB_OK);
}
else
{
val=RAM[addr & 0xff];
}
return val;
}
读写均为一个字节。由于上篇定义的CPU寻址范围只有64字节大小,所以超过64字节就要给出错误提示。
然后需要为每一个CPU指令机器码实现一个解码执行函数:
void nop(REG*);
void mov(REG*);
void add(REG*);
void cmp(REG*);
void jmp(REG*);
void jcp(REG*);
void nop(REG* cpuREG)
{
cpuREG->R_PC++;
sprintf("NOP\n");
}
void mov(REG* cpuREG)
{
memSet(cpuREG->R_PC+1, memGet(cpuREG->R_PC+2));
sprintf("MOV [0x%4x], [0x%4x]\n", cpuREG->R_PC+1, cpuREG->R_PC+2);
cpuREG->R_PC+=3;
}
void add(REG* cpuREG)
{
memSet(cpuREG->R_PC+1, memGet(cpuREG->R_PC+1)+memGet(cpuREG->R_PC+2));
sprintf("ADD [0x%4x], [0x%4x]\n", cpuREG->R_PC+1, cpuREG->R_PC+2);
cpuREG->R_PC+=3;
}
void cmp(REG* cpuREG)
{
if((memGet(cpuREG->R_PC+1)-memGet(cpuREG->R_PC+2)) < 0)
{
cpuREG->R_CMP=0;
}
else
{
cpuREG->R_CMP=1;
}
sprintf("CMP [0x%4x], [0x%4x]\n", cpuREG->R_PC+1, cpuREG->R_PC+2);
cpuREG->R_PC+=3;
}
void jmp(REG* cpuREG)
{
sprintf("JMP [0x%4x] \n", cpuREG->R_PC+1);
cpuREG->R_PC=memGet(cpuREG->R_PC+1);
}
void jcp(REG* cpuREG)
{
sprintf("JCP [0x%4x], [0x%4x]\n", cpuREG->R_PC+1, cpuREG->R_PC+2);
if(cpuREG->R_CMP==0)
{
cpuREG->R_PC=memGet(cpuREG->R_PC+1);
}
else
{
cpuREG->R_PC=memGet(cpuREG->R_PC+2);
}
}
这里最重要的是要小心处理PC寄存器。一开始CPU初始化的时候,PC寄存器是设为0的,而自定义的rom.bin也是从0地址开始执行的。如果你虚拟的CPU不是从0地址开始执行,那么在CPU初始化的时候就要把PC寄存器设为相应的开始地址。另外每一条指令可能涉及的地址数不相同,那么PC寄存器的变动也要不同。最后,跳转指令也可能要根据比较寄存器的内容来改变PC寄存器。
做了如上的准备之后就可以实现解释器了。这里用switch-case结构来决定哪条指令被执行。为了简单起见,用了一个函数指针来执行解码函数:
void (*func)(REG*);
//Interpreter
void Interpreter(REG* cpuREG)
{
char Str_Err[256];
switch(memGet(cpuREG->R_PC))
{
case 0:
func=nop;
break;
case 1:
func=mov;
break;
case 2:
func=add;
break;
case 3:
func=cmp;
break;
case 4:
func=jmp;
break;
case 5:
func=jcp;
break;
default:
sprintf(Str_Err, "Unhandled Opcode (0x%4x) at [0x%4x]", memGet(cpuREG->R_PC), cpuREG->R_PC);
MessageBox(NULL, Str_Err, "Warning", MB_OK);
return;
}
func(cpuREG);
}
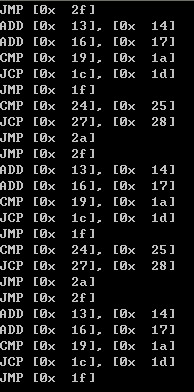
首先从内存中取出数据,根据机器码来决定执行解码函数,最后执行。执行结果如下: