Javacore 与 WebSphere Commerce 性能问题
近年来,依据 WebSphere Commerce(以下简称为 WC)搭建的电子商务网站系统日益增多。由于系统本身的复杂性,一旦系统出现问题,尤其是性能问题,问题诊断和定位就会非常困难。下图所示为由 WC 系统为核心搭建的电子商务网站的一般逻辑架构 , 如图 1 所示:
图 1. 电子商务网站的一般逻辑架构
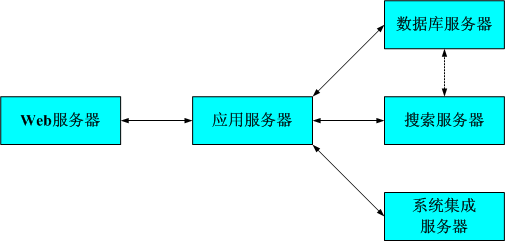
在整个系统架构中,核心应用逻辑运行在 WebSphere 应用服务器上。当系统出现性能问题时,虽然实际问题的根源可能分布在各个节点上,但是通过在应用服务器上的线程运行状态分析,都有助于对整个系统的当前状态以及可能的问题根源进行快速定位。WebSphere 应用服务器运行在 JVM(Java 虚拟机)之上。所以掌握通过 Javacore 进行 Java 线程分析,对于解决 WC 系统中的性能问题至关重要。
本文介绍如何通过 Javacore 文件分析线程运行状态,以及辅助分析工具的使用。并通过实例讲解如何利用 Java 线程分析解决 WC 系统中的性能问题。本文所介绍的分析方法对于其他基于 JavaEE 构建的企业应用也有借鉴意义。
如何通过 Javacore 了解线程运行状况
Javacore 是一个当前 JVM 运行状态的快照。通过对 Javacore 的分析,可以了解在 JVM 中运行的应用程序的当前状态,比如是否“卡”在某一点上,或在某些代码上运行时间太长。
Javacore 的基本内容
Javacore,也可以称为“threaddump”或是“javadump”,它是 Java 提供的一种诊断特性,能够提供一份可读的当前运行的 JVM 中线程使用情况的快照。即在某个特定时刻,JVM 中有哪些线程在运行,每个线程执行到哪一个类,哪一个方法。
应用程序如果出现不可恢复的错误或是内存泄露,就会自动触发 Javacore 的生成。而为了性能问题诊断的需要,我们也会主动触发生成 Javacore。在 AIX、Linux、Solaris 环境中,我们通常使用 kill -3 <PID> 产生该进程的 Javacore。IBM Java6 中产生 Javacore 的详细方法可以参考文章 [1]。
对于 IBM JVM,AIX 平台上的 Javacore 会被写到 javacore.<date>.<time>.<PID>.<sequence>.txt 中。对于 Oracle JVM,Javacore 被附加到 native_stdout.txt。Javacore 的内容有两列,第一列是“类型”,第二列表示“数据”,如清单 1 所示:
清单 1
1TISIGINFO Dump Event "user" (00004000) received 1TIDATETIME Date: 2013/12/22 at 23:05:18 1TIFILENAME Javacore filename: /usr/WebSphere/AppServer/profiles/demo_solr/javacore.20131222.230518.7995516.0004.txt
通常情况下,Javacore 中除了线程信息外,还能提供关于操作系统,应用程序环境,线程,程序调用栈,锁,监视器和内存使用等相关信息。
为了便于分析,Javacores 的每一段的开头,都会用“----------”和上一信息块区分开来。每一信息块的标题会以“=========”来标识,很容易找到,如清单 2 所示:
清单 2
NULL ------------------------------------------------------------------------ 0SECTION GPINFO subcomponent dump routine NULL ================================ 2XHOSLEVEL OS Level : AIX 7.1 2XHCPUS Processors - 3XHCPUARCH Architecture : ppc64 3XHNUMCPUS How Many : 8 3XHNUMASUP NUMA is either not supported or has been disabled by user NULL 1XHERROR2 Register dump section only produced for SIGSEGV, SIGILL or SIGFPE. NULL
Javacore 文件中,每行都包含一个标签,这个标签最多由 15 个字符组成。第一位数字表示信息的详细级别,级别越高代表信息越详细。接着的两个字符是段标题的缩写,例如:“CI”表示 Command line interpreter,“CL”表示 Class loader,“LK”表示 Locking,“ST”表示 Storage,“TI”表示 Title,“XE”表示 Execution engine 等。余下的字符表示信息的概述。如下清单 3 所示:
清单 3
3XMTHREADINFO "Thread-18" J9VMThread:0x00000000308DA900, j9thread_t:0x0000010016C4F2E0, java/lang/Thread:0x000000004136E3E8, state:P, prio=5
虽然不同版本的 JVM 所产生的 Javacore 的格式会稍有不同,但基本都包含下面几个内容:
TITLE 信息块:描述 Javacore 产生的原因,时间以及文件的路径。常见的 Javacore 产生的原因可以参考文章 [2]。最常见的有下面三种:
user:SIGQUIT 信号
gpf:程序一般保护性错误导致系统崩溃
systhrow:JVM 内部抛出的异常
GPINFO 信息块:GPF(一般保护性错误)信息
ENVINFO 信息块:系统运行时的环境和 JVM 参数
MEMINFO 信息块:内存使用情况和垃圾回收情况
LOCKS 信息块:用户监视器(monitor)和系统监视器(monitor)情况
THREADS 信息块:所有 java 线程的状态信息和执行堆栈
CLASSES 信息块:类加载信息
Javacore 中的线程可分为以下几种状态:
- 死锁(Deadlock)【重点关注】:一般指多个线程调用间,进入相互资源占用,导致一直等待无法释放的情况。
- 执行中(Runnable)【重点关注】:一般指该线程正在执行状态中,该线程占用了资源,正在处理某个请求,有可能在对某个文件操作,有可能进行数据类型等转换等。
- 等待资源(Waiting on condition)【重点关注】:等待资源,如果堆栈信息明确是应用代码,则证明该线程正在等待资源,一般是大量读取某资源、且该资源采用了资源锁的情况下,线程进入等待状态。又或者,正在等待其他线程的执行等。
- 等待监控器检查资源(Waiting on monitor)
- 暂停(Suspended)
- 对象等待中(Object.wait())
- 阻塞(Blocked)【重点关注】:指当前线程执行过程中,所需要的资源长时间等待却一直未能获取到,被容器的线程管理器标识为阻塞状态,可以理解为等待资源超时的线程。这种情况在应用的日志中,一般可以看到 CPU 饥渴,或者某线程已执行了较长时间的信息。
- 停止(Parked)
通过对 Javacore 数据的分析经验,结合对具体应用代码逻辑的理解,有经验的工程师可以直接通过文本编辑器查看原始 Javacore 文件来分析当前应用程序的运行状态。一般初学者则需要通过一些工具进行更直观的分析。
图形化分析工具 TMDA
有很多图形化工具可以用于 Javacore 的分析。笔者常用的工具为:IBM Thread and Monitor Dump Analyzer for Java 工具,简称 TMDA。TMDA 提供以下功能:
- 提供一个简洁的 Javacore 内容的总结,包括一些初步的预警信息,线程柱状图,内存使用情况信息等等。
- 方便地分析线程栈和监视器(monitor)的用户接口
- 方便地进行多个 Javacore 中的线程栈和监视器进行比较的用户接口
无论是初学者还是性能分析专家都可以使用 TMDA 进行 Javacore 的快速分析。关于 TMDA 的更多介绍可以参考它的社区:参考文献 [3]
WC 线程执行堆栈分析
不论是否利用 TMDA 工具进行分析,对 Javacore 的分析最终都会落实在具体线程的执行堆栈上。如果对具体应用的代码不熟悉,那么看着一个个长长的执行堆栈,可能会觉得无从下手。本部分介绍 WC 线程执行堆栈的常见代码和对应的功能模块。初学者可以根据这些示例推测某个线程的当前运行状态。需要注意的是,WC 的不同版本,同样的功能模块的具体代码可能会发生变化,经过用户定制的代码就更是千差万别。本部分提供的只是依据 WC FEP7 版本代码的一些示例,读者需要根据自己所处理的系统的实际代码情况灵活掌握,不可拘泥。
通常一个 Javacore 里面会有上百个线程,这些线程的地位并不一样。有些线程是系统运行的“入口线程”,而其他一些线程只是由这些线程派生出来的辅助线程。所以 Javacore 分析过程中一定要抓住这些主要线程。
WC 的核心是一个 Web 应用,所以大部分 WC 的 Javacore 以应用服务器的 Web 容器为入口。用来处理前台商店或后台管理端的 JVM 基本类似,但专门运行定时任务的 JVM 会有所区别。下图 2 所示为以 Web 容器为入口线程的一般调用结构:
图 2. 调用结构
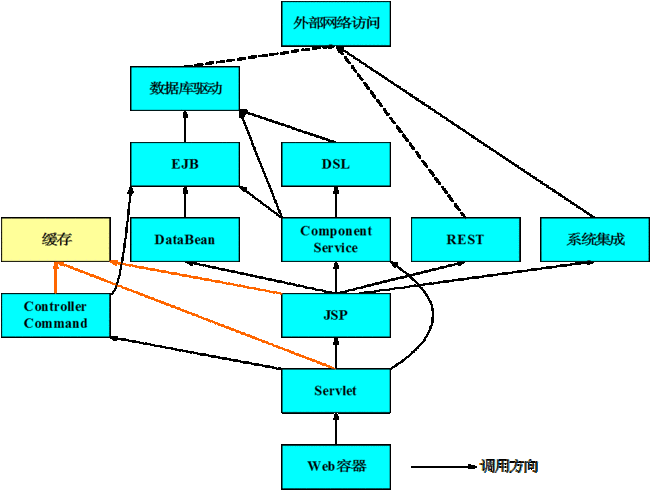
从 Web 容器入口开始,一般会进入 Servlet 执行。如果有缓存而且命中的话,则会进入 DynaCache 的相关代码。如果无缓存或缓存不命中,如果是 JSP 页面,则会执行 JSP 的相关代码,否则会执行相应的逻辑。代码逻辑处理过程中,经常会访问到数据库(通过 DSL 或 EJB)或 Solr 搜索(通过 BOD 或 REST),还有可能访问到外部系统集成接口(通过 HTTP 同步调用或消息队列)。如果数据库服务器 / 搜索服务器 / 系统集成服务器分布在其他节点上,那么这些调用最终都会转化为网络访问。
以下为一个正在处理 JSP 页面中的数据库请求的执行堆栈示例,如图 3、4、5:
图 3. 堆栈实例(1)
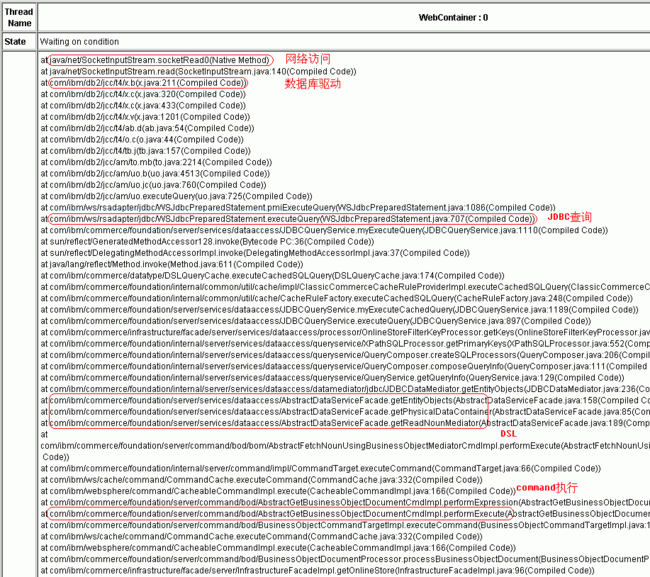
图 4. 堆栈实例(2)

图 5. 堆栈实例(3)
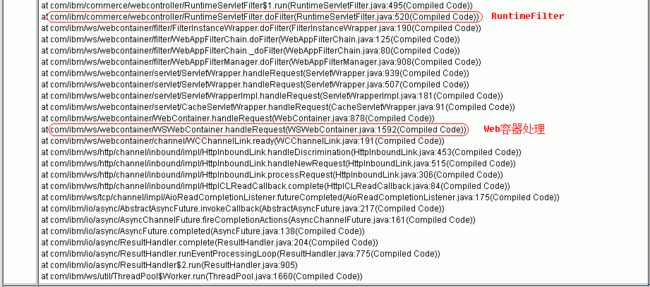
自下而上的关键代码:
- Web 容器处理请求
Package 名 / 类名 . 方法名:com.ibm.ws.webcontainer/WebContainer.handleRequest
- RuntimeFilter
Package 名 / 类名 . 方法名:com.ibm.commerce.webcontroller/RuntimeServletFilter.doFilterAction
- Servlet 处理
Package 名 / 类名 . 方法名:com.ibm.commerce.struts/ECActionServlet.doGet
或者
Package 名 / 类名 . 方法名:com.ibm.commerce.struts/ECActionServlet.doPost
- JSP 处理
Package 名 / 类名 . 方法名:com.ibm._jsp/_(JSP 文件名 )._jspService
- Command 执行(图例为 BOD command)
Package 名 / 类名 . 方法名:com.ibm.commerce.*/Abstract(*)CmdImpl.performExecute
- DSL
Package 名 / 类名 . 方法名:com.ibm.commerce.foundation.server.services.dataaccess/AbstractDataServiceFacade.*
- JDBC
查询
Package 名 / 类名 . 方法名:com.ibm.ws.rsadapter.jdbc/WSJdbcPreparedStatement.executeQuery
或 Package 名 / 类名 . 方法名:com.ibm.ws.rsadapter.cci/WSResourceAdapterBase.executeQuery
更新
Package 名 / 类名 . 方法名:com.ibm.ws.rsadapter.jdbc/WSJdbcPreparedStatement.executeUpdate
或 Package 名 / 类名 . 方法名:com.ibm.ws.rsadapter.cci/WSResourceAdapterBase.executeUpdate
- 数据库驱动代码
DB2
Package 名:com.ibm.db2.*
Oracle
Package 名 / 类名 . 方法名:oracle.jdbc.driver/OraclePreparedStatement.executeInternal
- 外部网络访问
(网络读)Package 名 / 类名 . 方法名:java.net/SocketInputStream.socketRead0
(网络写)Package 名 / 类名 . 方法名:java.net/SocketOutputStream.socketWrite0
其他常见的执行堆栈举例:
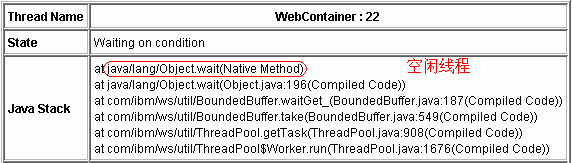
- 空闲(Idle)
这样的堆栈表示当前线程处于空闲状态(对于 Web 容器而言,即当前线程没有接收到 Web 请求)。其调用栈为:
Package 名 / 类名 . 方法名:java.lang/Object/wait
…
Package 名 / 类名 . 方法名:com.ibm.ws.util/ThreadPool$Worker. run
或者
Package 名 / 类名 . 方法名:com.ibm.io.async/AsyncLibrary. aio_getioev*
…
Package 名 / 类名 . 方法名:com.ibm.ws.util/ThreadPool$Worker. run
图 6 示例截图
- 事务(Transaction)处理
提交(Commit)
Package 名 / 类名 . 方法名:com.ibm.commerce.server/TransactionManager.commit
回滚(Rollback)
Package 名 / 类名 . 方法名:com.ibm.commerce.server/TransactionManager.rollback
- 缓存(DynaCache)读取
Package 名 / 类名 . 方法名:com.ibm.ws.cache/Cache.getEntry(或 getCacheEntry)
基于 WXS 的缓存则为
Package 名 / 类名 . 方法名:com.ibm.ws.objectgrid.dynacache/RemoteCoreCacheImpl.get
- MultiClick 处理
Package 名 / 类名 . 方法名:com.ibm.commerce.webcontroller.doubleclick/MultiClickRequestHandler. waitForResponse
- 消息处理(MQ)
Package 名 / 类名 . 方法名:com.ibm.mq.jmqi.remote.internal/RemoteRcvThread.run
- 搜索(Solr)处理
Package 名 / 类名 . 方法名:org.apache.solr.client.solrj/SolrServer.query
- REST 处理
Package 名 / 类名 . 方法名:com.ibm.commerce.foundation.internal.client.util/RESTHandler.execute
前面作者已经强调,不同版本的 WC 代码或者经过定制的代码会有不同。读者必须在实际系统开发运维过程中积累经验,形成自己的代码样例“库”。这样才能在长长的执行堆栈中迅速抓住关键信息。
案例分析
本部分通过两个具体实例讲解如何通过 Javacore 分析来分析解决 WC 系统中的性能问题。当系统出现性能问题的时候,通常系统的工作状态会发生某些异常。我们的任务就是通过 Javacore 分析来找出系统关键线程的运行状态变化。这里一般都需要获取多次 Javacore 并进行比较,发现哪些是“变”的部分,哪些是“不变”的部分。所以,谁和谁比,比什么,是分析问题的关键。
逻辑死锁问题
Javacore 分析经常用于解决逻辑死锁问题。使用 TMDA 工具,可以在图形界面中快速找出不同线程之间的等待关系,如图 7 所示:
图 7. TMDA 工具图形界面
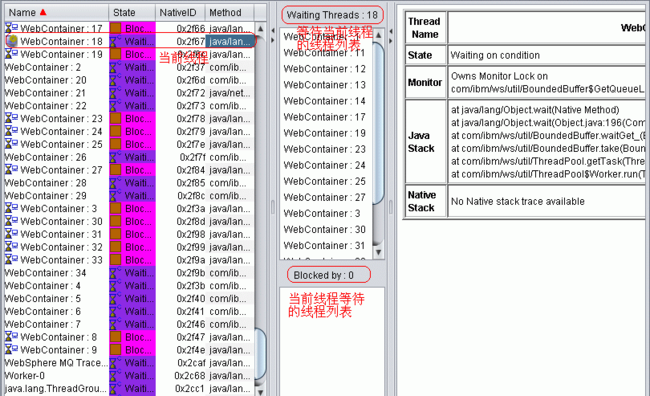
如果在同一个 JVM 内部出现了线程之间循环等待的状况,就会进入线程之间的死锁(Deadlock)状态。对于未定制的 WC 系统而言,直接出现这样的死锁问题的可能性比较小。较常见的是在整个系统的不同节点之间出现的逻辑死锁问题,这种问题一般不能直接在 Javacore 中识别出来。本节通过一个 WC 内部测试过程中遇到的案例介绍如何分析解决这种逻辑死锁问题。
这是一个随机浏览产品目录的测试场景。在这个场景中,WC 应用服务器接收请求,并调用搜索服务器上的索引进行处理。简化后的系统架构图(省略了 Web 服务器)如图 8 所示:
图 8. 简化的系统架构图
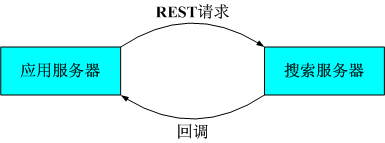
这里,搜索服务器在处理过程中会有一次回调到应用服务器,通过应用服务器获取某些搜索所需的数据。
我们对这个测试场景进行了用户数递增的压力测试,正常情况下,我们期望看到的结果是随着用户数的增加,系统的吞吐量逐渐上升,最后达到一个平稳状态(达到 CPU 瓶颈)。但是实际测试过程中看到的现象却是,当并发用户数增加到某个数值的时候,系统吞吐率突然下降,最终降低到 0,如图 9、10。
图 9. 并发用户数
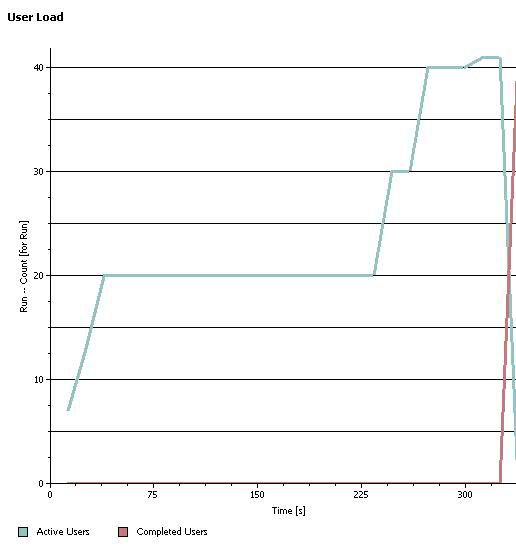
图 10. 吞吐率
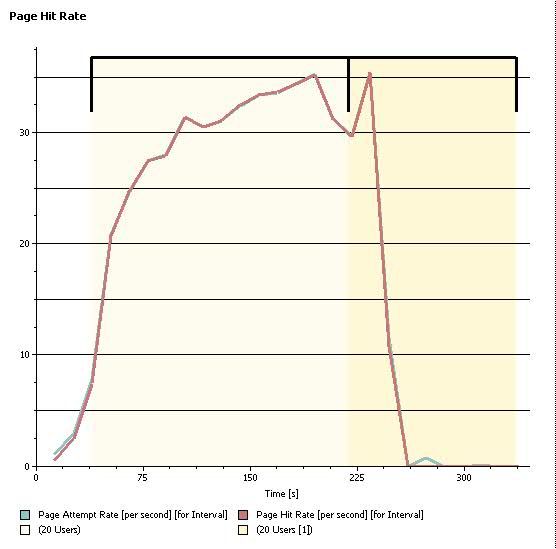
此时,我们监控两个节点上的 CPU 使用状况。发现吞吐量降低为 0 的同时,CPU 使用率也几乎降低为 0。因此,初步可以判断系统出现了逻辑死锁问题。反之,如果某个节点上的 CPU 使用率(或其他资源使用率)很高,则有可能是逻辑死循环或其他代码实现问题。
要想进一步分析就需要通过 Javacore 分析获取当前 JVM 的运行状态信息。这里我们需要分别在应用服务器和搜索服务器端获取 Javacore(采样的时间点要同步)。采样点可以做三次,在吞吐率下降前采样一次,下降后采样两次(中间间隔 30 秒以上)。然后对这三次 Javacore 进行对比分析。
在 TMDA 中打开采样到的 Javacore 文件。TMDA 提供的“Compare Threads”功能可以用来比较这些 Javacore 文件:
图 11. TMDA 比较菜单
先来看 WC 应用服务器端的 Javacore 文件。前文已经解释过 Web 容器通常是整个应用的入口,所以我们重点关注 Web 容器相关线程的状态。TMDA 比较的结果如图 12 所示:
图 12. TMDA 比较结果

用黄底色表示(TMDA 的不同版本显示效果可能略有区别)的线程表示在两次采样中的状态相同(执行堆栈相同)。这里可以很清楚地看到在第二次和第三次采样点上,所有 Web 容器的线程执行状态都相同,系统已经进入了假死(HANG)状态(注意这两次采样发生在系统吞吐率降为 0 之后)。
这里需要注意,在第一个采样点(系统吞吐率下降之前),还有很多线程处于“阻塞”(Blocked)状态。而在第二、第三个采样点上,除了个别线程处于阻塞状态外,多数线程都处于“执行中”(Runnable)状态。由此可见,不能完全依赖 Javacore 中标明的线程状态来判断当前系统的状态,关键还是要看执行堆栈中实际在执行的代码。处于“执行中”状态的线程可能实际在等待,而处于“等待资源”(Waiting on condition)状态的线程可能实际是“执行中”状态。
我们进一步分析第二、第三个采样点上,Web 容器各线程的执行堆栈。我们发现,虽然下层处理的页面(JSP)各有不同,但是顶层处于运行中的代码都一样:
图 13. 执行堆栈

基本上所有的 Web 容器线程都在等待 REST 请求的网络返回。根据前面描述的简化后的系统结构图,可以推断所有线程都在等候搜索服务器的处理结果。这是作者根据对系统结构的理解进行的判断,如果读者在实际问题分析过程中无法确定,可以使用 netstat 进行网络监控,根据 HTTP 链接的建立情况进一步确认。
下一步,我们再比较搜索服务器端的三个时间点上的 Javacores 文件。结果是类似的,同样第二个和第三个采样点上 Web 容器的所有线程都进入了假死(HANG)状态:
图 14. 三个采样点比较结果

我们再来看看搜索服务器端处于“执行中”的线程都在干什么。基本上所有执行堆栈的顶端都在执行如下代码:
图 15. 执行堆栈代码

经过代码分析,我们发现这是搜索服务器端在通过 REST 回调 WC 应用服务器,获取 BCS(BusinessConextService)相关的数据。
这样的调用关系为什么会导致逻辑上的死锁呢?关键在于对 Web 容器的线程池资源的竞争上。每个 WC 端接收到的请求在处理过程中需要占用 Web 容器的线程池的一个线程资源,而这个处理逻辑在处理过程中请求了搜索服务器端,又通过搜索服务器端回调到 WC 端,这就需要占用 Web 容器的线程池的另一个线程资源。
这个逻辑关系可以简化为图 16:
图 16. 简化逻辑关系图
在应用服务器的 Web 容器线程池资源上,通过搜索服务器的回调形成了一个闭环。这类似于标准的“哲学家就餐问题”,如果所有的请求都占用了第一个线程资源,而请求第二个线程资源,那么所有的线程都会阻塞在这个状态上,形成死锁。要解决这个线程死锁问题,必须消除这个资源占用上的闭环。可以采取的方案包括消除从 Search 端的 REST 回调,建立一个独立的线程池专门负责处理 Search 端的回调,等等。
寻找性能瓶颈
除了分析逻辑死锁问题外,Javacore 分析也可以用于寻找性能瓶颈。一般来说,寻找代码逻辑中的性能瓶颈,需要对代码的执行路径进行 Profiling(执行统计分析)。Profiling 工具一般有两种。能够提供完整执行堆栈的工具一般都是侵入式的,运行开销很高,并不适于在高负载的生产环境中使用。基于采样(sampling)的工具运行开销很小,但通常都不提供完整的执行堆栈。这里其实可以把 Javacore 分析当作辅助的 Profiling 工具来用。每个 Javacore 都提供了在某一时刻正在运行的代码的执行堆栈,这可以看作一个采样点。如果多做几次采样点,那么根据这些 Javacore 数据就可以进行一个执行路径的粗略 Profiling(不过总体采样点数量比真正的 Profiling 工具少很多)。
我们仍以一个 WC 产品测试过程中遇到的问题为例介绍这种分析方法。
我们在某个产品开发的版本测试过程中发现,搜索结果页面(SearchResultDisplay)的性能比前一个版本下降了很多。为了找出性能下降的原因,我们对该页面进行了单场景压力测试。当系统性能进入稳定状态后,我们在 WC 应用服务器端做了 Javacore 数据采样。
同样,我们的入口线程仍是 Web 容器的线程。这里要解决的是性能下降问题(系统 CPU 占用率很高),而不是逻辑死锁问题。所以我们关注的重点是同一次采样内部线程之间的横向比较,而不是多次采样之间的横向比较,所以只需要用到 TMDA 的线程分析功能,而不需要使用线程比较功能。
如果关注于执行堆栈的顶部代码,我们发现 Web 容器各线程的执行状况比较分散,似乎没有什么规律。但是如果从执行堆栈的底部往上看,就会发现某些规律。这里我们发现在 Web 容器的 25 个线程(等于线程池的大小)中,有一半以上的执行堆栈在执行如下图 17 代码:
图 17. 执行代码

由于这是单场景压力测试,基本上所有的 Web 容器线程都在执行相同的 JSP:SearchBasedCategoryPage。如果这个 JSP 里面没有明显的性能瓶颈,那么 Web 容器的 25 个线程应该随机运行在这个 JSP 的不同代码逻辑之中。我们实际观察到的现象则是有一半以上的线程都在执行如下代码:
com/ibm/commerce/infrastructure/facade/client/AbstractInfrastructureFacadeClient.getOnlineStore
为了排除代码执行随机性的影响,我们又在随后的系统执行过程中多做了几次采样,仍然得到了类似的结果。
这就表示该代码有可能是整个 JSP 逻辑中的性能瓶颈(当然还不能完全确定)。另一方面,通过与前一个版本的 Javacore 进行对比分析,发现前一版本的 Javacore 中并没有出现该代码。这说明该代码是当前版本新引入的代码。通过进一步的代码分析发现,这是在当前版本中新加入的一段处理客户定制逻辑的新代码。我们屏蔽了该端代码后,重新进行了性能测试,发现性能基本上可以恢复到前一版本的水平。因此最终可以确定是这段代码导致了当前版本的性能下降问题。
如何解决这类性能问题呢?首先应该是评估原始的实现逻辑,是否需要在每一个页面请求的处理过程中执行这段逻辑。如果不需要,则可以直接屏蔽该代码段。如果这一段逻辑必须在每一个页面请求中执行,则可以考虑引入适当的缓存机制,降低重复执行时的开销。
这种分析方法也可以用于在客户生产系统中快速定位整个系统的性能瓶颈。生产系统执行的页面请求是多种多样的,通常情况下,在生产系统上做 Javacore 应该找不到什么规律。反之,如果多次采样可以发现系统在高负载运行状态下,Web 容器线程的执行堆栈存在某些规律,比如:大部分线程都在执行目录页面(CategoryDisplay)显示。而页面访问统计的结果显示,目录页面的访问频率并不比其他页面高很多。这种情况下就很有可能在 CategoryDisplay 页面有性能瓶颈。下一步就可以进行单场景的压力测试来进一步寻找 CategoryDisplay 页面逻辑中的性能瓶颈。
如果能将 Javacore 分析的结果,与其他基于采样的 Profiling 工具的分析结果相结合,则更容易快速找到代码中的性能瓶颈。
此文转自http://www.ibm.com/developerworks/cn/websphere/library/techarticles/1406_tuzy_javacore/1406_tuzy_javacore.html