集算器能够协助java处理结构化文本的各种计算工作,但碰到非单行记录的情况就不能直接计算了,这时需要先进行一些必要的变换处理。
比如,文本文件Social.txt中存储着网站的访问记录,每三行对应一条记录,现在需要整理出这些记录,再进行下一步的计算。记录需要按(UserID, Time, IP, URL, Location)的格式取出使用或存放在文件中。注意:列分隔符是tab,行分割符是回车换行,前几行数据如下:

该文件每三行对应一条记录,其中第一行的IP、URL、Time是有用数据,第二行数据无用,第三行的UserID和Location是有用数据。比如,第一条记录应当是(UserID, Time, IP, URL, Location)=(47356, 2013-04-01 21:14:44, 10.10.10.143, /p/pt301/index.jsp, Chicago)。记录整理的过程如下:
集算器代码:
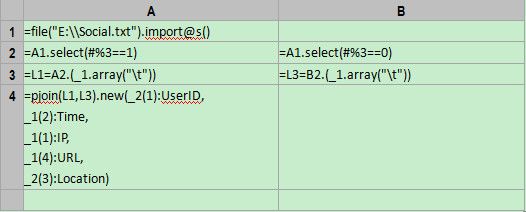
代码解读:
A1:file("E:\\Social.txt").import@t()
这句代码用来将文本文件一次性读入序表对象中,如下:
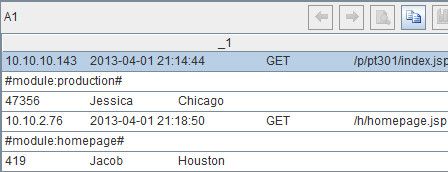
可以看到,A1只有一列,列名是默认的“_1”,文本文件中的每一行对应“_1”中的一条数据。
A2:A1.select(#%3==1)
这句代码用来按行号取每三行中的第一行,比如第1、4、7、10行,其中#是行号,%是取余数,select函数可对序表按字段名或行号进行查询。执行后结果如下。

B2:A1.select(#%3==0)
类似地,这句代码用来取每行中的第三行,比如第3、6、9、12行,结果如下:
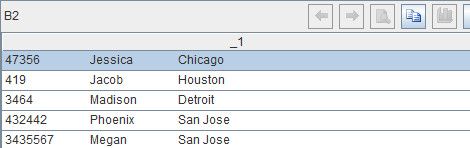
经过上面几步,每条记录的第一行和第三行就分别存在了序列A2和B2中。它们行数相等,行号互相对应,只是尚未拆分。
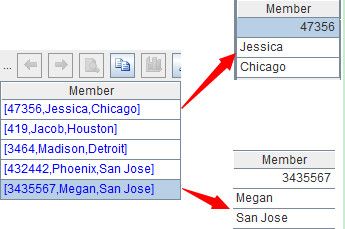
L1=A2.(_1.array("\t"))
这表示将每条记录的第一行拆分为字符串序列,并将该序列起名为L1,“\t”表示以tab为分隔符。结果如下:

如上图,L1中的每个成员对应一个字符串序列,点击蓝色超链接可以看到序列子成员。每条记录的第三行也用类似的方式处理,代码是:=L3=B2.(_1.array("\t")),取名为L3,结果如下图:
下面,我们把L1和L3中需要的字段拼在一起,形成一个新的序表:
pjoin(L1,L3).new(_2(1):UserID, _1(2):Time, _1(1):IP, _1(4):URL, _2(3):Location)
计算结果如下:
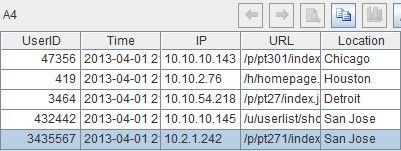
函数pjoin用来将L1和L3按照序号进行横向拼接,拼接后L1的默认名是_1,L3的默认名是_2。函数new用来生成新的序表,其中_2(1):UserID表示将L3中每个成员的的第1个子成员取出来,拼接后改名为字段“UserID”,以此类推。
A4就是整理出来的可用记录,如果需要将记录存入文件,只需用一句:=file("E: \\result.txt").export@t(A4)。这里的函数选项@t表示将字段名存入文件的第一行。
也可以对A4按照以前的方式进行结构化数据计算,比如:按地区分组汇总,求得每个地区的访问量,并过滤出访问量大于某个值(比如百万)的地区,最后将计算结果输出到JDBC。代码如下:

=A4.groups(Location;count(~):pv)
这句代码用来按地区分组汇总,求得每个地区的访问量。
=A5.select(pv>=@arg) //@arg是输入参数,比如1000000。
这句代码按访问量过滤,计算出访问量大于某个值的地区。
提示:函数groups可以对多个字段分组,汇总字段也可以是多个,select函数也可以进行多条件过滤。
result A5,
这句代码将A5输出到JDBC,以便被JAVA程序调用。
下面在JAVA代码中通过JDBC调用集算器脚本。
//建立esProc jdbc连接
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
//调用esProc,其中test是脚本文件名
st =(com.esproc.jdbc.InternalCStatement)con.prepareCall("call test(?)");
//设置参数,假设访问量大于1000000,实际应该是JAVA中的变量。
st.setObject(1,"1000000 ")//
st.execute();//执行esProc存储过程
ResultSet set = st.getResultSet(); //获取结果集
有时候非单行记录文件的字节数较多,无法在内存中一次完成计算,用JAVA处理这类大文件时需要边读边算边写临时文件,代码非常复杂。集算器有游标数据对象,非常适合分段读写大文件。
集算器处理大文件:
先编写主程序main.dfx:
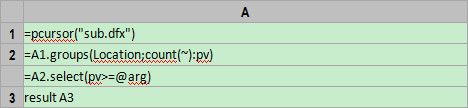
上述代码中,pcursor调用了一个子程序,用来返回实际记录形成的游标。而A2和A3格只需进行分组汇总和过滤即可。需要注意的是,A1的计算结果是游标,而不是内存中的数据,执行函数groups时,游标才会被分批读入内存并进行计算,而这个分批的动作是自动完成的。
子程序sub.dfx负责循环处理文件,每批次读取3*N行,形成N条记录返回,pcursor会依次接收每批次的计算结果,并转化为游标。注意:N不能太大,否则会内存溢出,也不能太小,否则性能较低。具体代码如下:
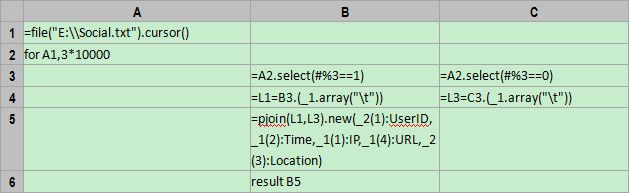
A1: =file("E:\\Social.txt").cursor()
上述代码中的函数cursor用来打开文件游标,其用法和函数import类似,但函数cursor并不真正把数据读入内存,因此可以支持大文件。
A2-C6:循环处理文件,其中for A1,3*10000表示每次将30000行数据读入内存。读入的数据和从小文件中读取到的一样,因此代码也和之前一样。