java并发学习笔记-java.util.concurrent包
在并发量很小的情况下,也许大家平时用到的HashMap比较多。我们知道HashMap是线程不安全的,在多线程使用HashMap进行put操作会引起死循环,导致cpu利用率接近100%(已测试模拟100000个线程执行以uuid为key,put值操作,cpu达到百分之90多)。HashTable是使用synchronized保证线程安全的,但是线程竞争激烈的情况下效率低,如线程 1 使用 put 进行添加元素,线程 2 不但不能使用 put 方法添加元素,并且也不能使用 get 方法来获取元素。
ConcurrentHashMap解决高并发情况下线程安全和效率问题,是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构,一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。所图所示:[img]
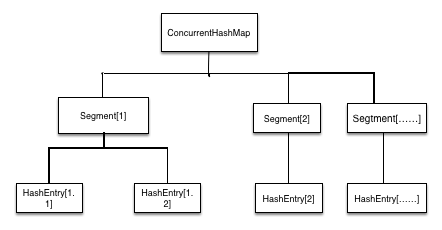
[/img]
ConcurrentHashMap的get操作实现非常简单和高效。先经过一次再哈希,然后使用这个哈希值通过哈希运算定位到segment,再通过哈希算法定位到元素。get 操作的高效之处在于整个 get 过程不需要加锁,除非读到的值是空的才会加锁重读。put操作需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时必须得加锁。Put 方法首先定位到 Segment,然后在 Segment 里进行插入操作。插入操作需要经历两个步骤:第一步判断是否需要对 Segment 里的 HashEntry 数组进行扩容,第二步定位添加元素的位置然 后放在 HashEntry 数组里。size操作统计元素的大小,也就是统计所有Segment里元素的求和。统计的时候不是把所有Segment的put,remove,clean方法锁住,而是先尝试 2 次通过不锁住 Segment 的方式来统计各个Segment 大小,如 果统计的过程中,容器的 count 发生了变化,则再采用加锁的方式来统计所有 Segment 的大小。那么判断count是否发生变化判断的条件是:使用 modCount 变 量,在 put , remove 和 clean 方法里操作元素前都会将变量 modCount 进行加 1,那么在统计 size 前 后比较 modCount 是否发生变化,从而得知容器的大小是否发生变化。
ConcurrentLinkedQueue 是一个基于链接节点的无界线程安全队列,它采用先进先出的规则对 节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部,当我们获取一个元素时,它 会返回队列头部的元素。类图结构如下:
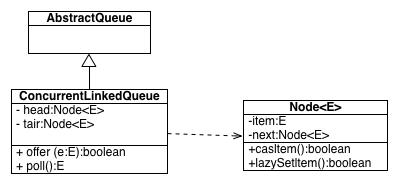
由图可知:它由 head 节点和 tair 节点组成,每个节点(Node)由节点元素(item)
和指向下一个节点的引用(next)组成,节点与节点之间就是通过这个 next 关联起来,从而组成一张 链表结构的队列。默认情况下 head 节点存储的元素为空,tair 节点等于 head 节点。
这两个类是java.util.concurrent包下的类,以后工作中遇到要求多线程安全情况下可以尝试用这两个类。
参考资料:方腾飞java并发
ConcurrentHashMap解决高并发情况下线程安全和效率问题,是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构,一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。所图所示:[img]
[/img]
ConcurrentHashMap的get操作实现非常简单和高效。先经过一次再哈希,然后使用这个哈希值通过哈希运算定位到segment,再通过哈希算法定位到元素。get 操作的高效之处在于整个 get 过程不需要加锁,除非读到的值是空的才会加锁重读。put操作需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时必须得加锁。Put 方法首先定位到 Segment,然后在 Segment 里进行插入操作。插入操作需要经历两个步骤:第一步判断是否需要对 Segment 里的 HashEntry 数组进行扩容,第二步定位添加元素的位置然 后放在 HashEntry 数组里。size操作统计元素的大小,也就是统计所有Segment里元素的求和。统计的时候不是把所有Segment的put,remove,clean方法锁住,而是先尝试 2 次通过不锁住 Segment 的方式来统计各个Segment 大小,如 果统计的过程中,容器的 count 发生了变化,则再采用加锁的方式来统计所有 Segment 的大小。那么判断count是否发生变化判断的条件是:使用 modCount 变 量,在 put , remove 和 clean 方法里操作元素前都会将变量 modCount 进行加 1,那么在统计 size 前 后比较 modCount 是否发生变化,从而得知容器的大小是否发生变化。
ConcurrentLinkedQueue 是一个基于链接节点的无界线程安全队列,它采用先进先出的规则对 节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部,当我们获取一个元素时,它 会返回队列头部的元素。类图结构如下:
由图可知:它由 head 节点和 tair 节点组成,每个节点(Node)由节点元素(item)
和指向下一个节点的引用(next)组成,节点与节点之间就是通过这个 next 关联起来,从而组成一张 链表结构的队列。默认情况下 head 节点存储的元素为空,tair 节点等于 head 节点。
这两个类是java.util.concurrent包下的类,以后工作中遇到要求多线程安全情况下可以尝试用这两个类。
参考资料:方腾飞java并发