1.Spark生态圈
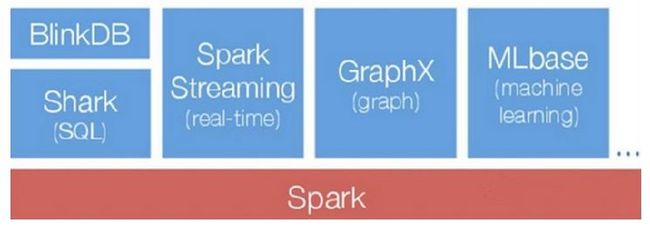
如下图所示为Spark的整个生态圈,最底层为资源管理器,采用Mesos、Yarn等资源管理集群或者Spark 自带的Standalone模式,底层存储为文件系统或者其他格式的存储系统如HBase。Spark作为计算框架,为上层多种应用提供服务。 Graphx和MLBase提供数据挖掘服务,如图计算和挖掘迭代计算等。Shark提供SQL查询服务,兼容Hive语法,性能比Hive快3-50 倍,BlinkDB是一个通过权衡数据精确度来提升查询晌应时间的交互SQL查询引擎,二者都可作为交互式查询使用。Spark Streaming将流式计算分解成一系列短小的批处理计算,并且提供高可靠和吞吐量服务。
2.Spark基本原理
Spark运行框架如下图所示,首先有集群资源管理服务(Cluster Manager)和运行作业任务的结点(Worker Node),然后就是每个应用的任务控制结点Driver和每个机器节点上有具体任务的执行进程(Executor)。
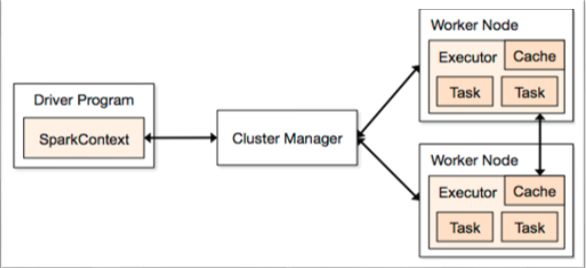
与MR计算框架相比,Executor有二个优点:一个是多线程来执行具体的任务,而不是像MR那样采用进程模型, 减少了任务的启动开稍。二个是Executor上会有一个BlockManager存储模块,类似于KV系统(内存和磁盘共同作为存储设备),当需要迭代 多轮时,可以将中间过程的数据先放到这个存储系统上,下次需要时直接读该存储上数据,而不需要读写到hdfs等相关的文件系统里,或者在交互式查询场景 下,事先将表Cache到该存储系统上,提高读写IO性能。另外Spark在做Shuffle时,在Groupby,Join等场景下去掉了不必要的 Sort操作,相比于MapReduce只有Map和Reduce二种模式,Spark还提供了更加丰富全面的运算操作如 filter,groupby,join等。
Notes: 在集群(cluster)方式下, Cluster Manager运行在一个jvm进程之中,而worker运行在另一个jvm进程中。在local cluster中,这些jvm进程都在同一台机器中,如果是真正的standalone或Mesos及Yarn集群,worker与master或分布于不同的主机之上。
JOB的生成和运行
job生成的简单流程如下
1.首先应用程序创建SparkContext的实例,如实例为sc
2.利用SparkContext的实例来创建生成RDD
3.经过一连串的transformation操作,原始的RDD转换成为其它类型的RDD
4.当action作用于转换之后RDD时,会调用SparkContext的runJob方法
5.sc.runJob的调用是后面一连串反应的起点,关键性的跃变就发生在此处
调用路径大致如下
1.sc.runJob->dagScheduler.runJob->submitJob
2.DAGScheduler::submitJob会创建JobSummitted的event发送给内嵌类eventProcessActor
3.eventProcessActor在接收到JobSubmmitted之后调用processEvent处理函数
4.job到stage的转换,生成finalStage并提交运行,关键是调用submitStage
5.在submitStage中会计算stage之间的依赖关系,依赖关系分为宽依赖和窄依赖两种
6.如果计算中发现当前的stage没有任何依赖或者所有的依赖都已经准备完毕,则提交task
7.提交task是调用函数submitMissingTasks来完成
8.task真正运行在哪个worker上面是由TaskScheduler来管理,也就是上面的submitMissingTasks会调用TaskScheduler::submitTasks
9.TaskSchedulerImpl中会根据Spark的当前运行模式来创建相应的backend,如果是在单机运行则创建LocalBackend
10.LocalBackend收到TaskSchedulerImpl传递进来的ReceiveOffers事件
11.receiveOffers->executor.launchTask->TaskRunner.run
Spark采用了Scala来编写,在函数表达上Scala有天然的优势,因此在表达复杂的机器学习算法能力比其他 语言更强且简单易懂。提供各种操作函数来建立起RDD的DAG计算模型。把每一个操作都看成构建一个RDD来对待,而RDD则表示的是分布在多台机器上的 数据集合,并且可以带上各种操作函数。如下图所示:
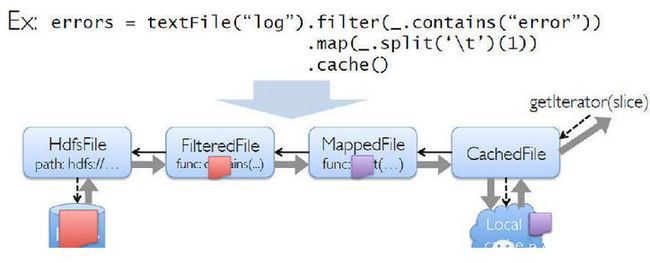
首先从hdfs文件里读取文本内容构建成一个RDD,然后使用filter()操作来对上次的RDD进行过滤,再使 用map()操作取得记录的第一个字段,最后将其cache在内存上,后面就可以对之前cache过的数据做其他的操作。整个过程都将形成一个DAG计算 图,每个操作步骤都有容错机制,同时还可以将需要多次使用的数据cache起来,供后续迭代使用.
3.Shark的工作原理
Shark是基于Spark计算框架之上且兼容Hive语法的SQL执行引擎,由于底层的计算采用了Spark,性 能比MapReduce的Hive普遍快2倍以上,如果是纯内存计算的SQL,要快5倍以上,当数据全部load在内存的话,将快10倍以上,因此 Shark可以作为交互式查询应用服务来使用。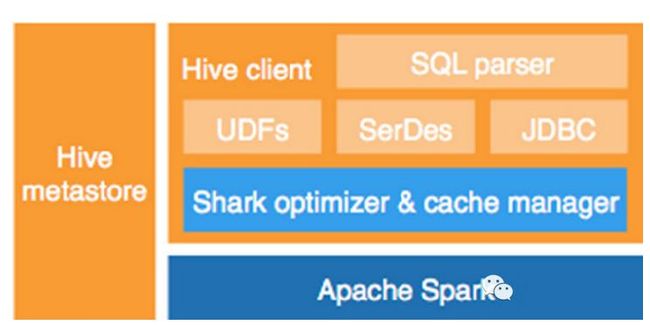
上图就是整个Shark的框架图,与其他的SQL引擎相比,除了基于Spark的特性外,Shark是完全兼容Hive的语法,表结构以及UDF函数等,已有的HiveSql可以直接进行迁移至Shark上。
与Hive相比,Shark的特性如下:
1.以在线服务的方式执行任务,避免任务进程的启动和销毁开稍,通常MapReduce里的每个任务都是启动和关闭进程的方式来运行的,而在Shark中,Server运行后,所有的工作节点也随之启动,随后以常驻服务的形式不断的接受Server发来的任务。
2.Groupby和Join操作不需要Sort工作,当数据量内存能装下时,一边接收数据一边执行计算操作。在Hive中,不管任何操作在Map到Reduce的过程都需要对Key进行Sort操作。
3.对于性能要求更高的表,提供分布式Cache系统将表数据事先Cache至内存中,后续的查询将直接访问内存数据,不再需要磁盘开稍。
4.还有很多Spark的特性,如可以采用Torrent来广播变量和小数据,将执行计划直接传送给Task,DAG过程中的中间数据不需要落地到Hdfs文件系统。