Disruptor 模式简单理解
Disruptor 主要用作进程间高效通信的一种模式, 它里面所有的实现都是围绕着怎样做可以high performance。 它的核心是 RingBuffer,其实就是一个事先分配好的数组。 这样做有几个好处:
1, GC友好, 事先分配好内存就避免了linkedqueue 那样不断的分配释放内存。 使用每一个单元的话步骤是先claim; 拿到claim 到得 单元, 使用copy的方式 将数据拷贝到那个单元; 然后发表那个单元。
2, 这个Buffer 里面的单元都有一个sequence, 我的理解就是版本号。 64位long 是从-1 初始值开始永远增长下去。 为了这个sequence, Disruptor 专门定义了一个 Sequence 类, 在它里面:
private volatile long p1 = 7L, p2 = 7L, p3 = 7L, p4 = 7L, p5 = 7L, p6 = 7L, p7 = 7L,
value = Sequencer.INITIAL_CURSOR_VALUE,
q1 = 7L, q2 = 7L, q3 = 7L, q4 = 7L, q5 = 7L, q6 = 7L, q7 = 7L;
其实真正有用的就是那个 value 域。 但是为什么value 的前后各自放了 7个 long 型的域呢。 在它的设计人员里面的博客里面有说明, 按照java 的内存模型一个对象的域会按它们的类型而不是定义顺序放在一起。 通常每64个byte 的内存内容叫做一个cache line, 机器得内存, L1, L2, L3 cache 之间内容交换都是按照cache line 级别来做的。 这样value 两边padding 了就避免了一个sequence 对象跟别的对象在cache 中False Sharing。 跑了些Disruptor 里面的unit test ,发现确实有很大差异。
3, 那边如何做到 producer/ consumer 协调工作呢 在 RingBuffer的超类中定义了 claimStrategy/waitStrategy. Producer 使用的是claimStrategy, 当然consumer 使用的就是 waitStrategy 了。 一个最基本的原则就是 producer 的sequence - bufferSize 不能小于所有的 consumer 的sequence。也就是说没有wrapping。 如果小于也就是producer 要等待, 否则就是有空间可以producer。 在具体怎么等待的Strategy 上, 它给出了3种方式: Busy Spin (也就是spin 循环) , Yield (Thread.yield) , Block.
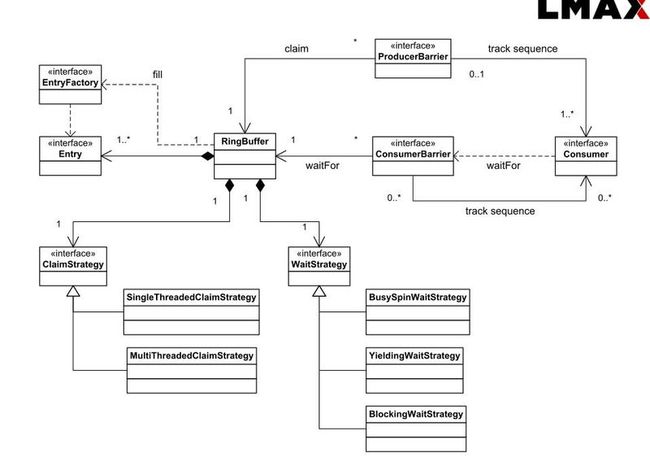
结合着Java 的内存, 线程模型 JSR 133 来看感觉不管是对 133 还是这个模式都有帮助。 现在盗用一张 Disruptor
1.0 的关于RingBuffer的类图如下: