Ubuntu10.04下Mahout 安装步骤详解
经过一两天的熟悉,基本对Mahout的安装掌握了,下面给出详细安装步骤,带图
1 软件要求:
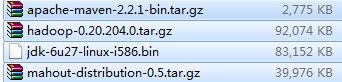
1. jdk-6u27-linux-i586.bin
2. apache-maven-2.2.1-bin.tar.gz
3. hadoop-0.20.204.0.tar.gz(不要用最新版,会报错)
4. mahout-distribution-0.5.tar.gz
2 关键步骤:
1. 复制软件到某文件夹下。
2. 解压软件。
3. 配置环境变量。/etc/profile
3 具体安装步骤:
1. 下载以上软件,JDK在Oracle官网下,maven,hadoop,mahout均在Apache官网下载。
2. 并将软件拷到/tmp下面,从U盘或者直接从网上Download.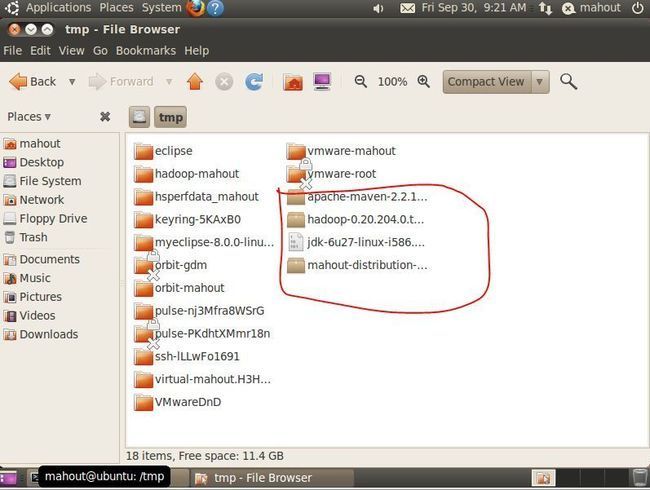
红笔圈的四个文件,直接从U盘中拉到/tmp的目录下即可。
注:进入/tmp目录,按红笔所示步骤操作:
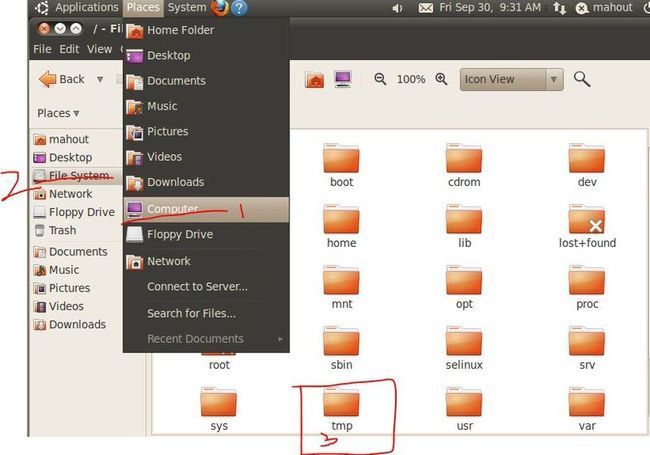
3. 将以上四个文件依次复制到/usr/mahout目录下【因tmp下的文件在下次重启后会消失,所以必须拷贝到其他目录下,而存在权限问题,需要用命令行方式拷贝,进入终端:如下图步骤所示】
4.
【mahout为新建目录,步骤为:cd /usr{切换目录到usr下}; mkdir mahout{新建mahout目录} 】
复制四个文件到/usr/mahout下:
à cp jdk-6u27-linux-i586.bin /usr/mahout
à cp apache-maven-2.2.1-bin.tar.gz /usr/mahout
à cp hadoop-0.20.204.0.tar.gz /usr/mahout
à cp mahout-distribution-0.5.tar.gz /usr/mahout
5. 如果不能正确复制,是由于权限问题,有两种方法解决问题:
第一种是为每个文件增加权限,然后在复制。
第二种为切换到超级用户(root/su)权限下:
用命令先激活su: sudo passwd root
先用第一次登陆的用户密码确认,在输入su超级用户的密码,输入一次,确认一次。
激活用户后在终端切换到su用户下,然后在操作以上复制步骤。
6. 解压以上文件:
对于*.bin的文件用./*.bin解压,对于,*.tar.gz或者*.tgz的文件用tar czvf *.tar.gz/ *.tgz方式来解压文件。
对以上文件一次如下:
à ./jdk-6u27-linux-i586.bin
à tar zxvf apache-maven-2.2.1-bin.tar.gz
à tar zxvf hadoop-0.20.204.0.tar.gz
à tar zxvf mahout-distribution-0.5.tar.gz
依次将文件解压到/usr/mahout目录下。
7. 配置环境变量:在/etc/profile文件最后面添加以下几行,
在终端中用gedit打开/etc/profile文件夹:sudo gedit /etc/profile,会出现如下窗口,添加以下内容,红笔圈的:
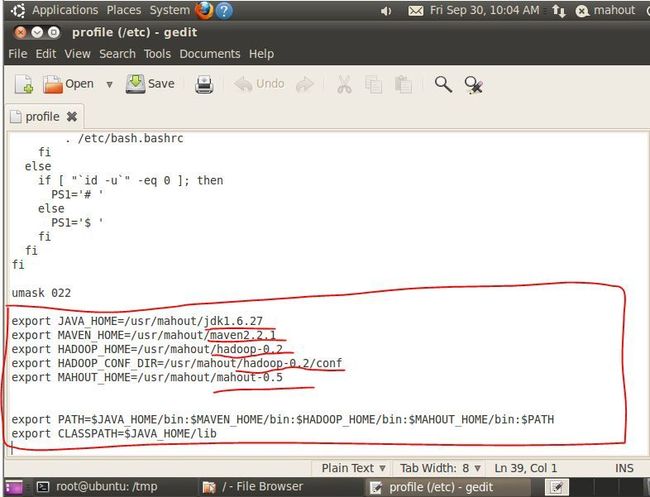
注意:是在umask 022后面添加以上内容,中间的东西不要修改错了,不然会出现启动不了系统的情况。红笔画横线的地方为你解压的文件目录名,根据自己解压的情况修改,我的是对目录全部重命了名的,如何重命名,Google找下(mv)。
之后保存文件并关闭gedit。其中冒号(:)表示连接,美元符($)表示输出变量。
在终端输入如下命令à source /etc/profile,重新导入/etc/profile文件。
8. 基本问题解决了,验证一下各环境变量【均在终端中输入】:
1) 验证JDK是否安装成功:javac,java
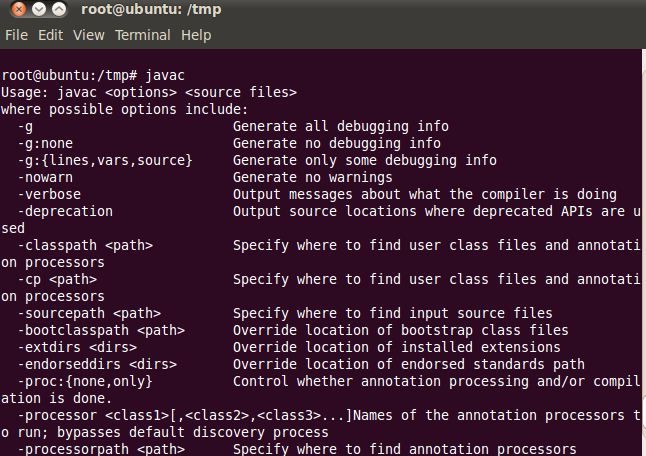
出现如上的图说明JDK中的PATH和CLASSPATH配置成功。
2) 验证maven是否安装成功:mvn
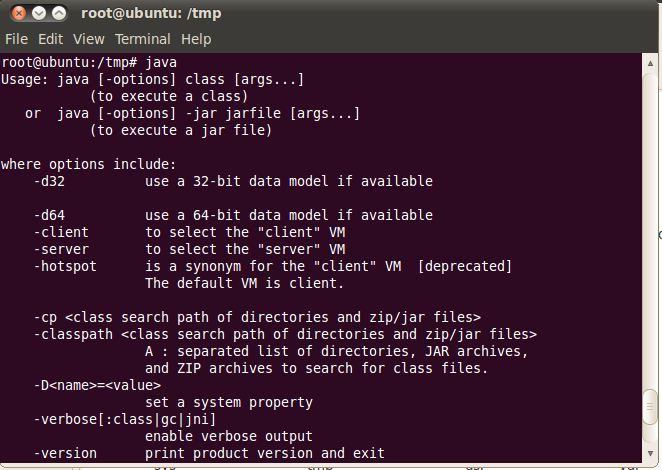
出现如上画面,maven安装成功。
3) 验证hadoop是否安装成功:hadoop
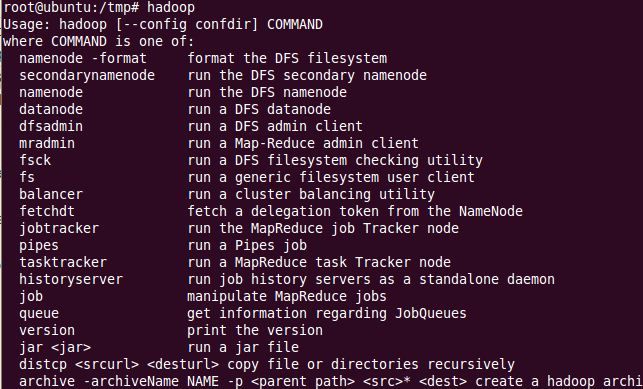
出现如上画面,hadoop安装成功。
4) 验证mahout是否安装成功:mahout
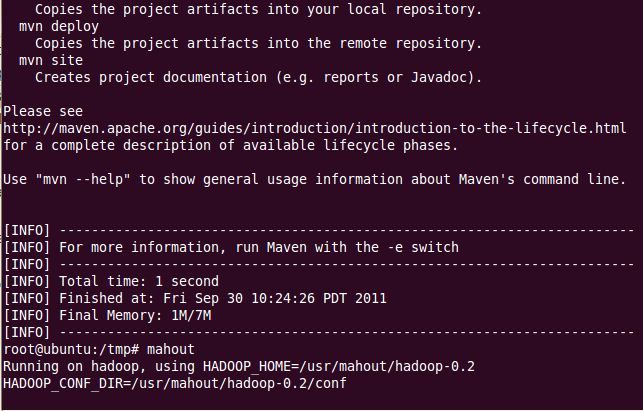
出现如上画面,mahout安装成功,。
4 单机测试:
数据准备
cd /tmp
wget http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data
hadoop fs -mkdir testdata
hadoop fs -put synthetic_control.data testdata
hadoop fs -lsr testdata
hadoop集群来执行聚类算法
cd /usr/local/mahout
mahout org.apache.mahout.clustering.syntheticcontrol.canopy.Job
mahout org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
mahout org.apache.mahout.clustering.syntheticcontrol.fuzzykmeans.Job
mahout org.apache.mahout.clustering.syntheticcontrol.dirichlet.Job
mahout org.apache.mahout.clustering.syntheticcontrol.meanshift.Job
如果执行成功,在hdfs的/user/dev/output里面应该可以看到输出结果
GroupLens Data Sets
http://www.grouplens.org/node/12,包括MovieLens Data Sets、Wikilens Data Set、Book-Crossing Data Set、Jester Joke Data Set、EachMovie Data Set
下载1m的rating数据
mkdir 1m_rating
wget http://www.grouplens.org/system/files/million-ml-data.tar__0.gz
tar vxzf million-ml-data.tar__0.gz
rm million-ml-data.tar__0.gz
拷贝数据到grouplens代码的目录,我们先本地测试下mahout的威力
cp *.dat /usr/local/mahout/examples/src/main/java/org/apache/mahout/cf/taste/example/grouplens
cd /usr/local/mahout/examples/
执行
mvn -q exec:java -Dexec.mainClass="org.apache.mahout.cf.taste.example.grouplens.GroupLensRecommenderEvaluatorRunner"
如果不想做上面拷贝文件的操作,则指定输入文件位置就行,如下:
上传到hdfs
hadoop fs -copyFromLocal 1m_rating/ mahout_input/1mrating
mvn -q exec:java -Dexec.mainClass="org.apache.mahout.cf.taste.example.grouplens.GroupLensRecommenderEvaluatorRunner" -Dexec.args="-i mahout_input/1mrating"
5 说明及注意点:
1. haoop版本一定不能用最新版的,不然在输入hadoop是会抛出异常。
2. 在设置环境变量时有几种方法可以设置:/etc/environment, ~/.bashrc等方法,它们在Linux有不同的优先级,具体Google查询。
3. 在下面学习安装是一定要对Linux下的命令很熟悉,刚开始我在设置环境变量/etc/profile文件的时候,用vi /etc/profile命令,即:用vi编辑器的方式来修改文件,由于对vi不熟悉连删除一个字符都不知道,弄的相当的恼火。
6 环境扩充【安装Eclipse或者MyEclipse】:
安装Eclipse或者MyEclipse开发环境:
下载Linux下的文件:*.gtz或*.tar.gz,解压文件,找到*-install相关的一个文件双击,会自动 安装的(对于MyEclipse GA版),Eclipse解压后如果环境变量配置成功,可以直接双击Eclipse图标使用。若Eclipse找不到jre的错,将Eclipse下的Jre 中建一个软连接映射到JDK中的Jre,即可。
基本过程如上,还是简单吧....
后面开始数据挖掘之旅啦...![]()
暂无评论
