从一个 JDK6 BUG 看 JAVA 数组创建
前几天在调试一段程序, 奇怪的发现: 程序性能和缓存大小是负相关的——缓存开越大,程序越慢,最快和最慢之间差 2 个数量级。开 jprofiler 查了下,发现了 JDK6 里有这样一段代码 (版本 build 1.6.0_14-b08):

红线里的部分只能用笔误来形容 ——Arrays.copyOf() 复制了我传递的整个缓存——在我的测试里,当缓存大小是 8KB 时,复制大约需要 3000ns,而缓存大小是 64KB 时,复制需要 21000ns.
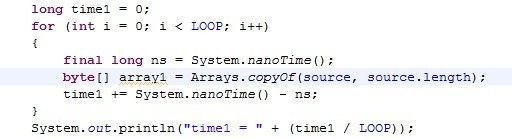
显然,使得 Arrays.copyOf 很慢的原因是每次创建新数组,造成 CPU cache 利用率不高,下面来证明一下。
Arrays.copyOf 的执行流程需要以下三步:
1. JVM 在堆中分配 8KB 内存;
Java 堆分配是 O(1), 顺序标记下一块 8KB 已经被分配了。
这基本可以看作不需要时间,实测约 150ns.
2. JVM 初始化 8KB 内存为 { 0 }
Java 会自动给新分配的数组元素置 0,即用 0 覆写新分配的内存。
CPU 怎么执行覆写?简单来说,有两种策略: Write-Through 和 Write-Back(注1).
策略 Write-Through 是无视 cache 直接覆写主内存 RAM,而 Write-Back 首会先从 RAM 读数据到 cache, 然后再覆写 cache, 标记 cacheline 为 dirty.
不管走什么策略,因为新分配的内存基本还在主存 RAM 里,覆写过程都需要访问 RAM,传输 8KB 的数据。
假设 JVM 优化得不错,能足够利用总线带宽。则可以这么估计:我机器的内存是 DDR3 1066@533MHz, 每次可以传输 8 x 64 / 8 = 64B, 延时 13.125ns (DDR3 1066), 一共需要 1680ns.
如果是 Write-Through,则总延时 = 写 RAM 延时 = 1680ns.
如果是 Write-Back,除了从 RAM 读出的时间外,还需要估算中考虑 L1 的写入时间,假设 JVM 代码足够优化,使用 64B cacheline 粒度写入:
估计值 = 1680ns + 8KB / 64B * 2 cycle / 2.4GHz (注2)= 1787ns
实际验证,在我的机器上需要 1900-2000ns.

注 1:从网上查到了 Intel i5 CPU 的数据, 子型号不太匹配, 凑合一下:
L1 Read/Write: 2 cycles per read (throughput)
L2->L1 B/W (Read, 64B) = 4 cycles per cache line
L2 Write (Write, 64B) = 7 cycles per write (cache line)
L3->L1 B/W (Read, 64B) = 6 cycles per cache line
L3 Write (Write, 64B) = 11 cycles per write (cache line)
下文也是用这个参数估算。
注 2:更复杂的情况是,因为数组刚创建,访问首先会出现 cache miss,这时 CPU 会用 Write-Back(miss allocate) — 简称 Wite-Allocate 或者 Write-Back(through on miss) 策略,决定是先从下一级 cache 读出 cacheline 还是直接覆写下一级 cache.
另外的复杂性是 CPU L1/L2/L3 cache 可能走不同的策略。
如果 CPU 是 Write-Allocate 策略,初始化 { 0 } 完毕后,数组会全部加载到 cache. 这是 JAVA 创建数组的优势。
3. 拷贝 8KB 到新分配的内存
System.arraycopy 是 native 调用,实现未知 (手头只能看到 OpenJDK 的代码), 优化不错的话, 应该是调用 rep movsd 或类似的指令。
这里的复杂性在于,从源数组读可能会出现 cache-miss, 写入新数组也可能出现 cache-miss. 通常 CPU L1/L2 cache 的命中率保守是 80%,我们可以估算一下:
如果 CPU 用 Write-Throught 策略, 这样读走 cache, 写直接写穿到 RAM, 很容易看出这样性能较低。
读 L1 = 8KB / 64B * 2-cycles / 2.4GHz = 107ns
读 L2 = 8KB / 64B * 4-cycles / 2.4GHz = 213ns
读 L3 = 8KB / 64B * 6-cycles / 2.4GHz = 320ns
写 RAM = 8KB / 64B * 13.125ns = 1680ns
估计值 = L1 107ns + L2 213ns * 0.2 + L3 320ns * 0.04 + RAM 1680ns = 1842ns
如果 CPU 用 Write-Allocate 或者 Write-Back (through on miss) 策略, 这样读写都走 cache, 并且 miss allocate 会引发 dirty cacheline 的回写:
读 L1 = 8KB / 64B * 2-cycles / 2.4GHz = 107ns
读 L2 = 8KB / 64B * 4-cycles / 2.4GHz = 213ns
读 L3 = 8KB / 64B * 6-cycles / 2.4GHz = 320ns
写 L1 = 8KB / 64B * 2-cycles / 2.4GHz = 107ns
写 L2 = 8KB / 64B * 7-cycles / 2.4GHz = 373ns
写 L3 = 8KB / 64B * 11-cycles / 2.4GHz = 587ns
W-A 估计值 = L1 107ns + L2 213ns * 0.2 + L3 320ns * 0.04 +
L1 107ns + L2 213ns * 0.2 + L3 320ns * 0.04 +
L2 373ns * 0.4 + L3 587ns * 0.08 = 521ns
W-B 估计值 = L1 107ns + L2 213ns * 0.2 + L3 320ns * 0.04 +
L1 107ns * 0.8 + L2 373ns * 0.16 + L3 587ns * 0.04 +
L2 373ns * 0.2 + L3 587ns * 0.04 = 449ns
实际验证一下,下面测出是 450-500ns:
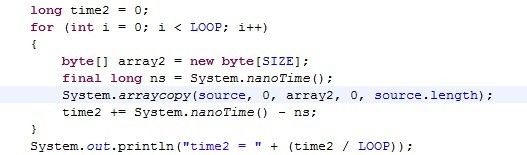
实测的结果证明 Intel i5 CPU 是用 Write-Back 策略管理缓存,实际上也是这样的。网上资料可以证明 Intel 自 486 CPU 后 cache 都采用 Write-Allocate 模式。
结果说明了什么?
1) 因为需要在创建数组后置 0, 产生 cache miss, 导致 JAVA 创建数组所需时间和数组大小成正比。
2) 作为上一条的副作用,JAVA 创建的数组已经进入 L2 cache (甚至 L1), 后续的访问效率很高。
我们应该怎样做?
1) 在要求性能的代码中,尽量少创建数组,尽量复用上次创建的数组。
2) 使用 HashMap 或者 ArrayList 之类内部依赖数组的数据结构时,初始大小不要太大,需要时再扩充比较好 (如果分配 256,实际需要 512,损失 50% 效率。如果分配 1024,实际需要 512,损失 100% 效率)。
3) 创建数组和访问数组的代码尽量在一起。
其他: 有没考虑的因素吗?
问题 1:覆写新数组没有考虑 L3 回写到 RAM 的影响?
假设 L3 cache 策略是 Write-Allocate,如果产生 L3 cache miss, 除了要从 RAM 加载 cacheline, 还会造成被淘汰的 cacheline 回写。极限情况下, 每次 L3 cache miss 可能全部需要回写, 需要传输双倍的数据。
如果有 30% 的 L3 cacheline 需要回写:
总计 = 1680ns + 1680ns * 0.3 = 2184ns
问题 2:是否有 TLB miss 的影响?
Intel CPU 的内存页面大小是 4KB, 测试的工作集仅 16KB, 需要占用 4 个 TLB item.
如果全部 TLB miss, 仅仅会增加 4 * 7 cycles / 2.4GHz = 12ns.
问题 3:GC 对性能的影响? 为了计算 GC 对计算的影响, 我打开了 -verbose:gc 选项:
[GC 16582K->395K(260160K), 0.0002036 secs]
[GC 16580K->395K(260160K), 0.0002074 secs]
[GC 16585K->395K(260160K), 0.0002019 secs]
...
在 -Xms256m -Xmx256m 参数下,代码每运行 20000 次产生 10 次 minor-gc, 每次大约 0.2ms, 这样影响是:
实测 = 10 * 0.2ms / 20000 = 100ns
有些影响, 但不至于影响结论。
问题 4:换台机器,计算方法还有效吗?
在服务器 (Xeon L5630 2.13GHz, 虚拟机) 上检验一下 (OpenJDK 64-Bit Server VM):
(CPU 参数来自评测,Xeon 是服务器系列,主频稍低、延迟稍高)
L1 = 8KB / 64B * 4-cycles / 2.13GHz = 240ns
L2 = 8KB / 64B * 11-cycles / 2.13GHz = 661ns
L3 = 8KB / 64B * 13-cycles / 2.13GHz = 781ns
估计值 = L1 240ns + L2 661ns * 0.2 + L3 781ns * 0.04 + // 读
L1 240ns + L2 661ns * 0.2 + // 写
L2 661ns * 0.4 + L3 781ns * 0.04 = 1071ns
实测值 = 1298ns
虚拟机 dmidecode 命令不可用, 不知道内存类型, 但是服务器内存带 ECC 效验, 每 64bit 增加 8bit 效验位,多消耗 1 个 CPU cycle:
估计值 = (8KB / 64 * 72) / 64B * (13.125ns + 1/2.13GHz) = 1958ns
实测值 = 2458ns