1.起因(Why HBase Coprocessor)
HBase作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执行求和、计数、排序等操作。比如,在旧版本的(<0.92)Hbase中,统计数据表的总行数,需要使用Counter方法,执行一次MapReduce Job才能得到。虽然HBase在数据存储层中集成了MapReduce,能够有效用于数据表的分布式计算。然而在很多情况下,做一些简单的相加或者聚合计算的时候,如果直接将计算过程放置在server端,能够减少通讯开销,从而获得很好的性能提升。于是,HBase在0.92之后引入了协处理器(coprocessors),实现一些激动人心的新特性:能够轻易建立二次索引、复杂过滤器(谓词下推)以及访问控制等。
2.灵感来源( Source of Inspration)
HBase协处理器的灵感来自于Jeff Dean 09年的演讲( P66-67)。它根据该演讲实现了类似于bigtable的协处理器,包括以下特性:
3.细节剖析(Implementation)
协处理器分两种类型,系统协处理器可以全局导入region server上的所有数据表,表协处理器即是用户可以指定一张表使用协处理器。协处理器框架为了更好支持其行为的灵活性,提供了两个不同方面的插件。一个是观察者(observer),类似于关系数据库的触发器。另一个是终端(endpoint),动态的终端有点像存储过程。
3.1观察者(Observer)
观察者的设计意图是允许用户通过插入代码来重载协处理器框架的upcall方法,而具体的事件触发的callback方法由HBase的核心代码来执行。协处理器框架处理所有的callback调用细节,协处理器自身只需要插入添加或者改变的功能。
以HBase0.92版本为例,它提供了三种观察者接口:
- RegionObserver:提供客户端的数据操纵事件钩子:Get、Put、Delete、Scan等。
- WALObserver:提供WAL相关操作钩子。
- MasterObserver:提供DDL-类型的操作钩子。如创建、删除、修改数据表等。
这些接口可以同时使用在同一个地方,按照不同优先级顺序执行.用户可以任意基于协处理器实现复杂的HBase功能层。HBase有很多种事件可以触发观察者方法,这些事件与方法从HBase0.92版本起,都会集成在HBase API中。不过这些API可能会由于各种原因有所改动,不同版本的接口改动比较大,具体参考Java Doc。
RegionObserver工作原理,如图1所示。更多关于Observer细节请参见HBaseBook的第9.6.3章节。
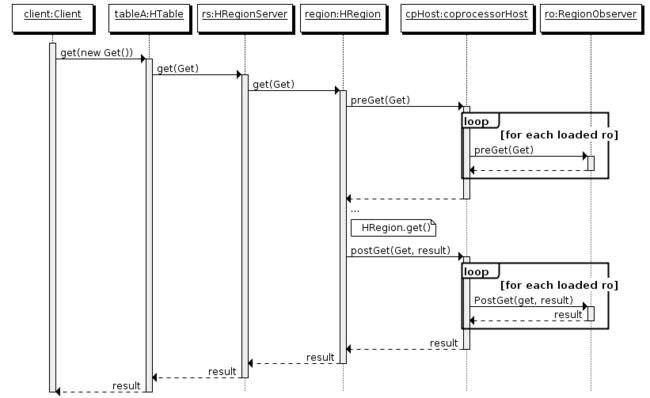
图1 RegionObserver工作原理
3.2终端(Endpoint)
终端是动态RPC插件的接口,它的实现代码被安装在服务器端,从而能够通过HBase RPC唤醒。客户端类库提供了非常方便的方法来调用这些动态接口,它们可以在任意时候调用一个终端,它们的实现代码会被目标region远程执行,结果会返回到终端。用户可以结合使用这些强大的插件接口,为HBase添加全新的特性。终端的使用,如下面流程所示:
- 定义一个新的protocol接口,必须继承CoprocessorProtocol.
- 实现终端接口,该实现会被导入region环境执行。
- 继承抽象类BaseEndpointCoprocessor.
- 在客户端,终端可以被两个新的HBase Client API调用 。单个region:HTableInterface.coprocessorProxy(Class<T> protocol, byte[] row) 。rigons区域:HTableInterface.coprocessorExec(Class<T> protocol, byte[] startKey, byte[] endKey, Batch.Call<T,R> callable)
整体的终端调用过程范例,如图2所示:
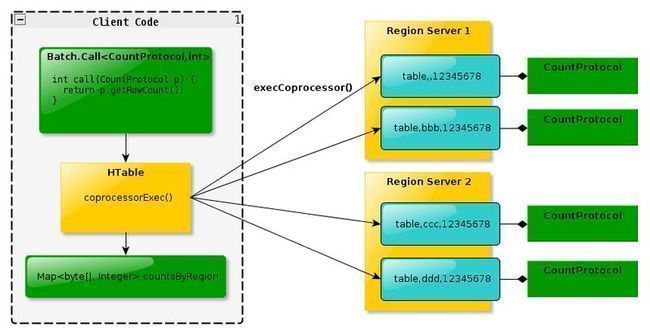
图2 终端调用过程范例
4.编程实践(Code Example)
在该实例中,我们通过计算HBase表中行数的一个实例,来真实感受协处理器 的方便和强大。在旧版的HBase我们需要编写MapReduce代码来汇总数据表中的行数,在0.92以上的版本HBase中,只需要编写客户端的代码即可实现,非常适合用在WebService的封装上。
4.1启用协处理器 Aggregation(Enable Coprocessor Aggregation)
我们有两个方法:1.启动全局aggregation,能过操纵所有的表上的数据。通过修改hbase-site.xml这个文件来实现,只需要添加如下代码:
<property> <name>hbase.coprocessor.user.region.classes</name> <value>org.apache.hadoop.hbase.coprocessor.AggregateImplementation</value> </property>
2.启用表aggregation,只对特定的表生效。通过HBase Shell 来实现。
(1)disable指定表。hbase> disable 'mytable'
(2)添加aggregation hbase> alter 'mytable', METHOD => 'table_att','coprocessor'=>'|org.apache.hadoop.hbase.coprocessor.AggregateImplementation||'
(3)重启指定表 hbase> enable 'mytable'
4.2统计行数代码(Code Snippet)
public class MyAggregationClient {
private static final byte[] TABLE_NAME = Bytes.toBytes("mytable");
private static final byte[] CF = Bytes.toBytes("vent");
public static void main(String[] args) throws Throwable {
Configuration customConf = new Configuration();
customConf.setStrings("hbase.zookeeper.quorum",
"node0,node1,node2");
//提高RPC通信时长
customConf.setLong("hbase.rpc.timeout", 600000);
//设置Scan缓存
customConf.setLong("hbase.client.scanner.caching", 1000);
Configuration configuration = HBaseConfiguration.create(customConf);
AggregationClient aggregationClient = new AggregationClient(
configuration);
Scan scan = new Scan();
//指定扫描列族,唯一值
scan.addFamily(CF);
long rowCount = aggregationClient.rowCount(TABLE_NAME, null, scan);
System.out.println("row count is " + rowCount);
}
}
4.3 典型例子
协处理器其中的一个作用是使用Observer创建二级索引。先举个实际例子:
我们要查询指定店铺指定客户购买的订单,首先有一张订单详情表,它以被处理后的订单id作为rowkey;其次有一张以客户nick为rowkey的索引表,结构如下:
rowkey family
dp_id+buy_nick1 tid1:null tid2:null ...
dp_id+buy_nick2 tid3:null
...
该表可以通过Coprocessor来构建,实例代码:
- public class TestCoprocessor extends BaseRegionObserver {
- @Override
- public void prePut(final ObserverContext<RegionCoprocessorEnvironment> e,
- final Put put, final WALEdit edit, final boolean writeToWAL)
- throws IOException {
- Configuration conf = new Configuration();
- HTable table = new HTable(conf, "index_table");
- List<KeyValue> kv = put.get("data".getBytes(), "name".getBytes());
- Iterator<KeyValue> kvItor = kv.iterator();
- while (kvItor.hasNext()) {
- KeyValue tmp = kvItor.next();
- Put indexPut = new Put(tmp.getValue());
- indexPut.add("index".getBytes(), tmp.getRow(), Bytes.toBytes(System.currentTimeMillis()));
- table.put(indexPut);
- }
- table.close();
- }
- }
即继承BaseRegionObserver类,实现prePut方法,在插入订单详情表之前,向索引表插入索引数据。
4.4索引表的使用
先在索引表get索引表,获取tids,然后根据tids查询订单详情表。
当有多个查询条件(多张索引表),根据逻辑运算符(and 、or)确定tids。
4.5使用时注意
1.索引表是一张普通的hbase表,为安全考虑需要开启Hlog记录日志。
2.索引表的rowkey最好是不可变量,避免索引表中产生大量的脏数据。
3.如上例子,column是横向扩展的(宽表),rowkey设计除了要考虑region均衡,也要考虑column数量,即表不要太宽。建议不超过3位数。
4.如上代码,一个put操作其实是先后向两张表put数据,为保证一致性,需要考虑异常处理,建议异常时重试z
4.6效率情况
put操作效率不高,如上代码,每插入一条数据需要创建一个新的索引表连接(可以使用htablepool优化),向索引表插入数据。即耗时是双倍的,对hbase的集群的压力也是双倍的。当索引表有多个时,压力会更大。
查询效率比filter高,毫秒级别,因为都是rowkey的查询。
如上是估计的效率情况,需要根据实际业务场景和集群情况而定,最好做预先测试。
4.7Coprocessor二级索引方案优劣
优点:在put压力不大、索引region均衡的情况下,查询很快。
缺点:业务性比较强,若有多个字段的查询,需要建立多张索引表,需要保证多张表的数据一致性,且在hbase的存储和内存上都会有更高的要求。
转:http://blog.csdn.net/lifuxiangcaohui/article/details/39991183