谈opents db中时序数据的存储
OpenTSDB是一种基于hbase的实时监控信息收集存储和展示平台.它的schema被精心设计用来存储监控数据这样的典型的时序数据.下面来分析下它的schema及其带来的好处.
监控数据这样的时序序列数据都是带有时间的数据,比如
cpu 20140305143405 15
cpu 20140305143410 17
......
cpu 20140305143455 33
表示了一系列时间点的cpu负载数据
按照一般的hbase用法,可以如下表示

cpu负载用0AB表示,负载值存放在hbase的column中
OpenTSDB的数据表采用了典型的宽列模式,大体如下表示

相当于对0AB20140305143400中进行了提取公因式,将共同的部分提取到了rowkey中,将不同的部分放到了column qualifier中
根据hbase的物理模型,两种不同的表示方法的都是以keyvalue的形式存储的.
第一种是
0AB20140305143400:f:v:15
0AB20140305143405:f:v:17
……
0AB20140305143455:f:v:33
第二种是
0AB201403051434:f:00:15
0AB201403051434:f:05:17
……
0AB201403051434:f:55:33
这样做的好处有哪些呢?
1 可以减少磁盘占用空间.对比发现,第二种存储可以每一个keyvalue减少一个column qualifier的存储,积少成多,集腋成裘,千里之堤毁于蚁穴,也能节省很多空间.勿以善小而不为,勿以恶小而为之
2 减少bloom filter的数量.hbase中可以使用bloom filter来提高查询速度.而bloom filter也需要占用一定的存储空间.StoreFile中append keyvalue时,需要根据rowkey是否不同而决定是否生成bloom filter
在appendGeneralBloomfilter方法中,有如下代码
在采用第二种方式存储时,不同的rowkey数量大大减少,也就减少了需要的bloom filter
3 在有filter的查询时,能更快速的查询.
下面这个图是filter的调用顺序
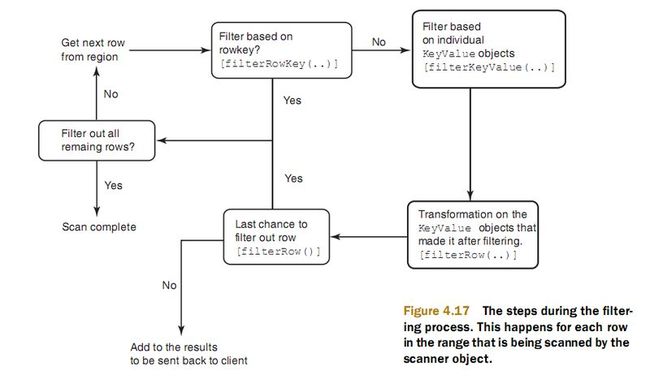
在采用第二种方式存储时,如果使用filter里的filterRowKey进行过滤,filterRowKey能够跳过很多kv,从而提高速度.
监控数据这样的时序序列数据都是带有时间的数据,比如
cpu 20140305143405 15
cpu 20140305143410 17
......
cpu 20140305143455 33
表示了一系列时间点的cpu负载数据
按照一般的hbase用法,可以如下表示
cpu负载用0AB表示,负载值存放在hbase的column中
OpenTSDB的数据表采用了典型的宽列模式,大体如下表示
相当于对0AB20140305143400中进行了提取公因式,将共同的部分提取到了rowkey中,将不同的部分放到了column qualifier中
根据hbase的物理模型,两种不同的表示方法的都是以keyvalue的形式存储的.
第一种是
0AB20140305143400:f:v:15
0AB20140305143405:f:v:17
……
0AB20140305143455:f:v:33
第二种是
0AB201403051434:f:00:15
0AB201403051434:f:05:17
……
0AB201403051434:f:55:33
这样做的好处有哪些呢?
1 可以减少磁盘占用空间.对比发现,第二种存储可以每一个keyvalue减少一个column qualifier的存储,积少成多,集腋成裘,千里之堤毁于蚁穴,也能节省很多空间.勿以善小而不为,勿以恶小而为之
2 减少bloom filter的数量.hbase中可以使用bloom filter来提高查询速度.而bloom filter也需要占用一定的存储空间.StoreFile中append keyvalue时,需要根据rowkey是否不同而决定是否生成bloom filter
public void append(final KeyValue kv) throws IOException {
appendGeneralBloomfilter(kv);
appendDeleteFamilyBloomFilter(kv);
writer.append(kv);
trackTimestamps(kv);
}
在appendGeneralBloomfilter方法中,有如下代码
boolean newKey = true;
if (this.lastKv != null) {
switch(bloomType) {
case ROW:
newKey = ! kvComparator.matchingRows(kv, lastKv);
break;
case ROWCOL:
newKey = ! kvComparator.matchingRowColumn(kv, lastKv);
break;
case NONE:
newKey = false;
break;
default:
throw new IOException("Invalid Bloom filter type: " + bloomType +
" (ROW or ROWCOL expected)");
}
}
if (newKey) {
//插入bloom filter
}
在采用第二种方式存储时,不同的rowkey数量大大减少,也就减少了需要的bloom filter
3 在有filter的查询时,能更快速的查询.
下面这个图是filter的调用顺序
在采用第二种方式存储时,如果使用filter里的filterRowKey进行过滤,filterRowKey能够跳过很多kv,从而提高速度.