Unlike a typical file system, which is designed for storage, ZooKeeper data is kept in-memory, which means ZooKeeper can achieve high throughput and low latency numbers.
与其他文件系统不同,zookeeper的数据存储于内存中,也就意味着zookper可以实现较高吞吐与低延时。
The ZooKeeper implementation puts a premium on high performance, highly available, strictly ordered access.
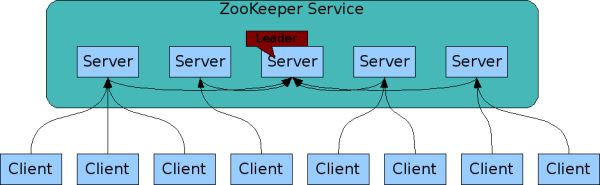
The servers that make up the ZooKeeper service must all know about each other. They maintain an in-memory image of state, along with a transaction logs and snapshots in a persistent store.
本文链接地址:http://quentinXXZ.iteye.com/blog/2117157
以下是对《Hadoop 权威指南》第二版 zookeeper一章的笔记:
Znode
Zookeeper 被设计用来实现协调服务(通常使用小数据文件),而不是用于大容量数据存储,一个znode能存储的数据被限制在1MB以内。
原子性:读取一个znode,要么读到全部数据,要么失败,不会只读到部份数据。
写操作不成功就失败,不会出现部份写的情况。
Znode路径必须是绝对路径。
Znode 分两种:短暂的和持久的,类型在创建后不可修改。创建短暂znode的客户端会话结束时,zookeeper会将短暂znode删除。持久znode不依赖于客户端,只有当客户端(不一定是创建者)明确删除时,才会删除。短暂znode不可以有子节点。
Sequal znode是指名称中包含zookeeper指定顺序号的znode。顺序号可以用于为所有的事件进行全局排序,这样客户端就可以通过顺序号来推断事件的顺序。
Zookeeper基本操作
Create、delete、exists、getACL、setACL、getChildren、getData、setData、sync更新操作是有条件的,delete/setACL时,必须提供,被更新znode的版本号(可通过exists获得)。
API
客户端语言:java和C。每种绑定,执行操作时,可选择同步或异步执行。
观察触发器
可以在读操作exists、getChilden、getData上设置观察(watcher)。
Exists被触发时机:znode创建、删除、数据更新
getChilden被触发时机:被观察znode子节点被创建或删除,该znode自己被删除。
getData被触发时机: 被观察znode被删除或数据更新。

ACL
三种身份验证机制:
1、 digest 用户名+密码 2、host 主机名 3、ip 客户端IP
exists 操作不受ACL 权限的限制。

OPEN_ACL_UNSAFE是一种预定义的ACL, 它将所有的权限(除ADMIN限制)授予每个人。
Zookeeper运行模式
1、 standalone mode,不能保证HA。
2、 replicated mode。组成集群,作为一个“集合体”(ensemble),通过复制实现高可用,只要集群中有半数以上的机器处于可用状诚,便可提供服务。 所以一个ensemble里面通常包奇数台机器。
Zookeeper所做的是,确保对znode树的每一个修改都会被复制到集合体中超过半数的机器上。如果少于半数,也至少有一台处于最新状态,其实副本最终也会被更新。
具体实现: Zab协议。
阶段1:leader选举
Ensemble中 选举出一个leader,其余为follower。一旦有半数以上(或指定数量)的follower与leader同步,则表明阶段已完成。
阶段2:原子广播(AB)
写请求都发给leader, 由leader将更新广播给follower。 半数以上的follwer将修改持久化后,leader才提交更新,客户端才会收到一个更新成功的响应。
一致性
每一个对znode树的更校报都被赋予了一个全局唯一的ID,称zxid(zookeeper transaction ID)。更新顺序严格按换zxid排列。
读操作不参与写操作的全局排序。客户端以Zookeeper服务器以处的机制进行通信,则可能靠成不一致。例如,客户端A将znode z的值修改,然后A告诉B去读取z值 ,B可能读到之前的值 ,这是 “跨客户端视图的同时一致性”。 为避免,B在取之前,要对z调用sync操作。
会话
空闲时间超过一定时间,客户端发ping,保持会话不过期,并检测服务器是否故障,使其能在会话超时的时间内重连到新的服务器。
客户端断开连接时,观察通知将无法发送,恢复连接后,这些延迟的通知会被发送。如果客户端重新连接至另一服务器过程中,应用程序试图执行一个操作,这个操作将会失败。
时间
Tick time 基本时间周期
Session timeout 范围 [2* tick Time , 20* tick Time]
服务器为每个会话分配一个唯一的ID和密码,如果在建立的过程中将它们传递给zookeeper,可以用于恢复一个会话(只要该会话没有过期)。
Zookeeper状态
1、Connecting 2、connected 3、closed
利用Zookeeper构建应用代码
1、 配置与获得最新配置
注意,在收到一次观察事件,发现znode有被修改,然后去进行一次读之间,znode可能在其间被更新过多,如果客户端在其间没有任何其他注册的话。
2、 可复原的zookeeper应用
InterruptedException异常,操作中断,不代表故障,而是操作被取消。
KeeperException:服务器发出错误信号或服务器存在通信。例如KeeperException.NoNodeException 不存在Node
一、状态异常: 例如版本号不匹配
二、可恢复异常: KeepException.ConnectionLossException。连接丢失,重连。需对幂等(idempotent)与非幂等(Nonidempotent)操作进行区分。幂等操作可重试。
三、不可恢复异常:会话已失效。 只能重连了。
3、锁服务
分布式锁在一组进程进程之间提供一种互斥机制。任何时间,只有一个进程可以持锁。分布式锁可以用于大型分布式系统中的实现领导的选举。
注意:不要将zookeeper自己的领导者选举和使用zookeeper基本操作的一般领导者选举服务混为一谈.
思路:一个znode作为锁 ,/leader; 为希望获得锁的客户端创建一些短暂顺序znode,作为znode的子节点。任何时间点内,顺序号最小的客户端将持有锁,例如,两个客户端,分别创建/leader/lock-1和/leader/lock-2,那创建/leader/lock-1的客户端便持有锁。删除/leader/lock-1即可释放锁;另外,如果客户端进程死亡,短暂znode自动被删除。通过创建一个znode删 除的watcher,可以在获得锁的时候得到通知。
问题1 : 羊群效应。大量的客户端,每个客户端都在锁znode上设置一个watcher,用于捕捉子节点的变化。每次锁被释放或另一个进程开始获取锁时,watcher都会被触发,并且每个客户端都会收到一个通知。羊群效应,指大量客户端收到同一事件的通知。这样会产生流量峰值,但是只有一个客户端需要处理该事件。
解决方法:只有在前一个顺序号子节点消失时,才需要通知下一个客户端。
问题2:不能处理因连接丢失而导致的create操作失败。创建一个顺序znode是非幂等操作,不能简间重试,重试会多出一个远法删掉的孤儿znode(除非客户端会话结束)。不幸的结果是将会出现死锁。
解决方法:znode名称中嵌入一个ID, 根据ID可以得知创建操作是否已成功。
不可恢复异常: 如果会话过期,短暂znode会自动删除,这个过程中,锁是不能预知应用程序需要如何清理自清的状态的。
Zookeeper带有一个java实现的生产级别的锁实现,WriteLock.
分布式数据结构和协议: 屏障(barrier)、队列、两阶段提交协议。