Hadoop源代码分析(三八)
我们可以开始从系统的外部来了解HDFS了,DFSClient提供了连接到HDFS系统并执行文件操作的基本功能。DFSClient也是个大家伙,我们先分析它的一些内部类。我们先看LeaseChecker。租约是客户端对文件写操作时需要获取的一个凭证,前面分析NameNode时,已经了解了租约,INodeFileUnderConstruction的关系,INodeFileUnderConstruction只有在文件写的时候存在。客户端的租约管理很简单,包括了增加的put和删除的remove方法,run方法会定期执行,并通过ClientProtocl的renewLease,自动延长租约。
接下来我们来分析内部为文件读引入的类。

InputStream是系统的虚类,提供了3个read方法,一个skip(跳过数据)方法,一个available方法(目前流中可读的字节数),一个close方法和几个在输入流中做标记的方法(mark:标记,reset:回到标记点和markSupported:能力查询)。
FSInputStream也是一个虚类,它将接口Seekable和PositionedReadable混插到类中。Seekable提供了可以在流中定位的能力(seek,getPos和seekToNewSource),而PositionedReadable提高了从某个位置开始读的方法(一个read方法和两个readFully方法)。
FSInputChecker在FSInputStream的基础上,加入了HDFS中需要的校验功能。校验在readChecksumChunk中实现,并在内部的read1方法中调用。所有的read调用,最终都是使用read1读数据并做校验。如果校验出错,抛出异常ChecksumException。
有了支持校验功能的输入流,就可以开始构建基于Block的输入流了。我们先回顾前面提到的读数据块的请求协议:

然后我们来分析一下创建BlockReader需要的参数,newBlockReader最复杂的请求如下:
public static BlockReader newBlockReader( Socket sock, String file,
long blockId,
long genStamp,
long startOffset, long len,
int bufferSize, boolean verifyChecksum,
String clientName)
throws IOException
其中,sock为到DataNode的socket连接,file是文件名(只是用于日志输出),其它的参数含义都很清楚,和协议基本是一一对应的。该方法会和DataNode进行对话,发送上面的读数据块的请求,处理应答并构造BlockReader对象(BlockReader的构造函数基本上只有赋值操作)。
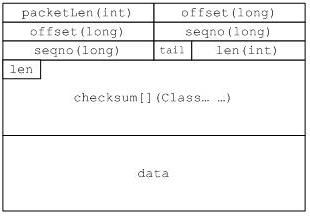
BlockReader的readChunk用于处理DataNode送过来的数据,格式前面我们已经讨论过了,如下图。
读数据用的read,会调用父类FSInputChecker的read,最后调用readChunk,如下:

read如果发现读到正确的校验码,则用过checksumOk方法,向DataNode发送成功应达。
BlockReader的主要流程就介绍完了,接下来分析DFSInputStream,它封装了DFSClient读文件内容的功能。在它的内部,不但要处理和NameNode的通信,同时通过BlockReader,处理和DataNode的交互。
DFSInputStream记录Block的成员变量是:
private LocatedBlocks locatedBlocks = null;
它不但保持了文件对应的Block序列,还保持了管理Block的DataNode的信息,是DFSInputStream中最重要的成员变量。DFSInputStream的构造函数,通过类内部的openInfo方法,获取这个变量的值。openInfo间接调用了NameNode的getBlockLocations,获取LocatedBlocks。
DFSInputStream中处理数据块位置的还有下面一些函数:
synchronized List<LocatedBlock> getAllBlocks() throws IOException
private LocatedBlock getBlockAt(long offset) throws IOException
private synchronized List<LocatedBlock> getBlockRange(long offset,
long length)
private synchronized DatanodeInfo blockSeekTo(long target) throws IOException
它们的功能都很清楚,需要注意的是他们处理过程中可能会调用再次调用NameNode的getBlockLocations,使得流程比较复杂。blockSeekTo还会创建对应的BlockReader对象,它被几个重要的方法调用(如下图)。在打开到DataNode之前,blockSeekTo会调用chooseDataNode,选择一个现在活着的DataNode。

通过上面的分析,我们已经知道了在什么时候会连接NameNode,什么时候会打开到DataNode的连接。下面我们来看读数据。read方法定义如下:
public int read(long position, byte[] buffer, int offset, int length)
该方法会从流的position位置开始,读取最多length个byte到buffer中offset开始的空间中。参数检测完以后,通过getBlockRange获取要读取的数据块对应的block范围,然后,利用fetchBlockByteRange方法,读取需要的数据。
fetchBlockByteRange从某一个数据块中读取一段数据,定义如下:
private void fetchBlockByteRange(LocatedBlock block, long start,
long end, byte[] buf, int offset)
由于读取的内容都在一个数据块内部,这个方法会创建BlockReader,然后利用BlockReader的readAll方法,读取数据。读的过程中如果发生校验错,那么,还会通过reportBadBlocks,向NameNode报告校验错。
另一个读方法是:
public synchronized int read(byte buf[], int off, int len) throws IOException
它在流的当前位置(可以通过seek方法调整)读取数据。首先它会判断当前流的位置,如果已经越过了对象现在的blockReader能读取的范围(当上次read读到数据块的尾部时,会发生这中情况),那么通过blockSeekTo打开到下一个数据块的blockReader。然后,read在当前的这个数据块中通过readBuffer读数据。主要,这个read方法只在一块数据块中读取数据,就是说,如果还有空间可以存放数据但已经到了数据块的尾部,它不会打开到下一个数据块的BlockReader继续读,而是返回,返回值包含了以读取数据的长度。
DFSDataInputStream是一个Wrapper(DFSInputStream),我们就不讨论了。