nutch1.2 DeleteDuplicates IndexMerger 详解
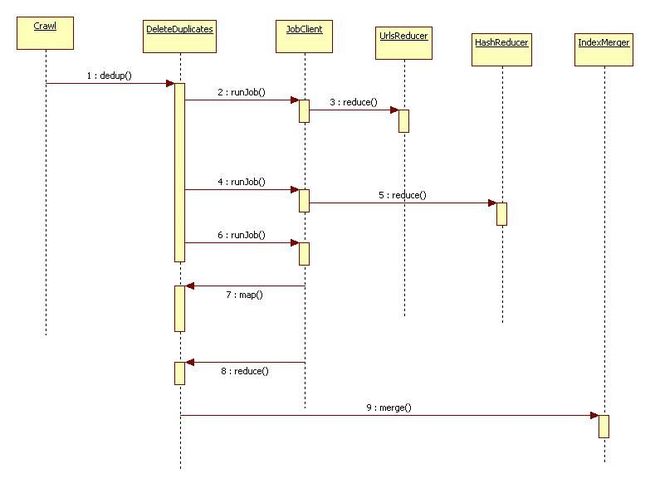
job 1
map: 默认Mapper ,
输出为key:Text url value :IndexDoc
job.setInputFormat(InputFormat.class); 关键在于这个Format会把lucene的doc转换成IndexDoc 代码如下:
public boolean next(Text key, IndexDoc indexDoc)
throws IOException {
// skip empty indexes
if (indexReader == null || maxDoc <= 0)
return false;
// skip deleted documents
while (doc < maxDoc && indexReader.isDeleted(doc)) doc++;
if (doc >= maxDoc)
return false;
Document document = indexReader.document(doc);
// fill in key
key.set(document.get("url"));
// fill in value
indexDoc.keep = true;
indexDoc.url.set(document.get("url"));
indexDoc.hash.setDigest(document.get("digest"));
indexDoc.score = Float.parseFloat(document.get("boost"));
try {
indexDoc.time = DateTools.stringToTime(document.get("tstamp"));
} catch (Exception e) {
// try to figure out the time from segment name
try {
String segname = document.get("segment");
indexDoc.time = new SimpleDateFormat("yyyyMMddHHmmss").parse(segname).getTime();
// make it unique
indexDoc.time += doc;
} catch (Exception e1) {
// use current time
indexDoc.time = System.currentTimeMillis();
}
}
indexDoc.index = index;
indexDoc.doc = doc;
doc++;
return true;
}
reduce :UrlsReducer 为index的数据去重复准备数据,一个url只能有一个值
1 对同一个key:如果有多个value,比较每个value的time,取最大的time,小于的数据设置 latest.keep = false; 写入,最后写入 latest.keep = true;的数据
2 key:Text 是签名,value:IndexDoc
job2 map: 默认Mapper
map out的数据 key:MD5Hash value:IndexDoc
reduce:HashReducer 写入的数据都是要删除的
1 对数据如果IndexDoc.keep=false 写入
2 如果IndexDoc.keep=ture的多个值,如果dedup.keep.highest.score为true说明按照score比较,否则安装url的长度比较。如果按照score比较,score分数小的写入,否则删除url的长度长的
job 3
map : DeleteDuplicates
1 对keep不为true的数据写入
key: 对应的目录 value:lucene docId
reduce : DeleteDuplicates
使用indexreader做删除操作
代码如下
Path index = new Path(key.toString());
IndexReader reader = IndexReader.open(new FsDirectory(fs, index, false, getConf()), false);
try {
while (values.hasNext()) {
IntWritable value = values.next();
LOG.debug("-delete " + index + " doc=" + value);
reader.deleteDocument(value.get());
}
} finally {
reader.close();
}
merger索引IndexMerger
用构建crawl/indexes 下面的所有Directory
Directory[] dirs = new Directory[indexes.length];
for (int i = 0; i < indexes.length; i++) {
if (LOG.isInfoEnabled()) { LOG.info("Adding " + indexes[i]); }
dirs[i] = new FsDirectory(fs, indexes[i], false, getConf());
}
merger 使用IndexWriter 的addIndexesNoOptimize 进行merger
//
// Merge indices
//
IndexWriter writer = new IndexWriter(
FSDirectory.open(new File(localOutput.toString())), null, true,
MaxFieldLength.UNLIMITED);
writer.setMergeFactor(getConf().getInt("indexer.mergeFactor", LogMergePolicy.DEFAULT_MERGE_FACTOR));
writer.setMaxBufferedDocs(getConf().getInt("indexer.minMergeDocs", IndexWriter.DEFAULT_MAX_BUFFERED_DOCS));
writer.setMaxMergeDocs(getConf().getInt("indexer.maxMergeDocs", LogMergePolicy.DEFAULT_MAX_MERGE_DOCS));
writer.setTermIndexInterval(getConf().getInt("indexer.termIndexInterval", IndexWriter.DEFAULT_TERM_INDEX_INTERVAL));
writer.setInfoStream(LogUtil.getDebugStream(LOG));
writer.setUseCompoundFile(false);
writer.setSimilarity(new NutchSimilarity());
writer.addIndexesNoOptimize(dirs);
writer.optimize();
writer.close();
最后使用
fs.completeLocalOutput(outputIndex, tmpLocalOutput);
生成crawl/index 至此nutch索引的部分全部完