汇编语言基础之寄存器
内存单元
无论计算机CPU的位数怎么变,从x86到现在的酷睿,CPU内部数据总线位宽在变大、寄存器的数量在增大、寄存器位数也在变大。但是对于内存的管理始终没有变化。计算机中用于存储的最小部件是一个二进制位(bit),一个bit能够存放两个数据,要么0要么1。在管理计算机存储空间的时候,将8个bit位分为一组,这就是计算机中的最小存储单元。称之1个字节(byte),一个字节的存储容量是2^8-1=255。1024(即2^10)个字节称之为1KB,接下来的M、G、T单位也就同理了。
8086CPU的寄存器都是16位的,后来的32位和64位CPU寄存器的位数与之前的CPU位数不一样,但是,就像8086CPU与上一代CPU寄存器兼容一样,32位和64位计算机的CPU为了向前兼容,按理来说,其内部一个32位的寄存器和64位寄存器应该可以分开当成2个16位的寄存器和4个16位的寄存器来使用。
不同的CPU,寄存器的个数、结构是不相同的,8086CPU中有14个寄存器。这14个寄存器的用途不尽相同,但是结构都一致:

这16位的二进制数据用相等的16进制来显示就成了四位数据了,所以,在查看计算机寄存器的时候,可以看到所有的寄存器值都是4位的:

其中AX、BX、CX、DX用于存放一般性数据,叫做通用寄存器。
物理地址的计算
cpu需要从内存中读取数据,就需要知道在内存中的实际物理地址。而8086cpu的地址总线有20条,而内部的寄存器只有16位,怎么用16位的寄存器来达到20条地址总线的寻址能力呢(20条数据总线的寻址能力是2^20=1M,但是16位寄存器实际能够表达的数据仅有2^16)?。8086cpu设计了两个寄存器来计算物理地址,即段寄存器和偏移地址寄存器(两种寄存器都分别有多个,如CS代码段和DS数据段),具体的计算方法是
物理地址=段地址X16+偏移地址
为什么要乘以16呢?乘以16何以能解决达到20位寻址能力的要求?解释是,往16位的段地址上乘以16,实际意义是往段地址后面增加了一个0,然后让IP加到低位。这里增加了一个0表示多了一位,多一位的16进制数据,即多了4位二进制位,从而达到了从16位表示能力增加到20位表示能力的目的。
代码段和代码段寄存器(CS)
其实在计算机中存放的都是二进制数据而已,这些数据的实际意义是根据实际情况附加上去的,你认为它是代码那他就是代码,你认为它是数据那它就是数据,代码和数据的本质是相同的。代码段寄存器(CS)中存放的地址说明,从这个地址开始(x16加上偏移地址后)的内容都是cpu将要执行的指令。
汇编语言中修改CS和IP的方法:jmp 段地址:偏移地址
从debug中可以通过-r CS和-r IP 来修改CS和IP
数据段和数据段寄存器(DS)
数据段的作用就不用多说了,但是DS的用法却需要注意一下,在读取数据段的内容的时候,需要先将DS的值设置好,然后通过如下的方式来访问数据段的内容:
mov ax,[0]
[...]表示一个内存单元,其中的0表示内存单元的偏移地址。这个偏移地址是在DS的基础上而言的。值得注意的是,这个地方往ax中传递的值是一个字类型(2字节,16位数据)而不是字节类型(8位数据)。
mov指令规则
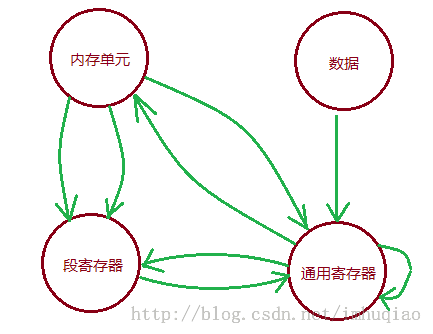
内存单元、通用寄存器和段寄存器之间可以相互赋值,而数据只允许直接存放到通用寄存器中。
栈
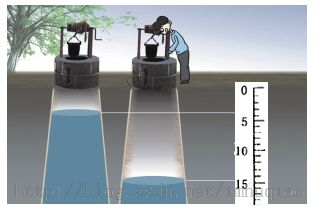
cpu提供了栈的机制共我们使用,栈顶的位置由SS:SP确定,8086cpu不保证栈地址越界,所以我们自己要时刻注意越界的问题。栈的使用时,可以将栈想象成一口井,井口的地址小,井底地地址大。在往井里倒水(入栈)的时候,井水水面上升(栈顶地址变小SP-=2);在从井里打水(出栈)时,井水水面下降(栈顶地址变大SP-=2)。其实,对于栈,cpu真的没有多实现什么,就像CS:IP一样,cpu可以根据这个地址来读取操作指令,cpu无非是在这个基础上增加了对SP的自动移动而已,理解了这个移动,就理解了栈的本质。
debug工具的使用
在32位机器上可以直接在命令行输入debug来启动debug工具,64位机器需要额外安装工具才能模拟debug工具。
-r查看和修改寄存器内容
直接输入一个-r可以查看寄存器情况,也可以输入-r 寄存器名称例如-r ax 来修改寄存器的值
-d 查看内存内容
该命令后面可以跟两个参数,一个参数是起始地址,该参数有两部分组成,用冒号分隔,例如1000:0;第二参数可以限定显示内存的单位数量,例如-d 1000:0 f,表示显示一行内存情况。
-u 查看内存数据对应的指令
-a 录入汇编指令到内存,这些内存可以通过-u命令查看
-e 直接修改内存内容
输入-e 和起始地址,输入要修改的值,按空格键跳到下一个内存单元,回车表示输入完毕