结合JDK学习数据结构——线性表顺序存储
前言:工作将近4年,自认为基础还算可以,实际工作中用到的技术比较广泛,常用框架也有所了解,数据库原理、优化也花时间啃过,分布式hadoop、zookeeper有些了解,mongodb也玩过,但是总感觉无论做什么都没有办法做深做透。而工作了4年,5年的时候应该对自己的将来有个定位,是走业务专家路线还是走架构师路线,经过长期的思考抉择,最终定位在技术上。再分析自己做技术也没有什么优势,年龄倒是一年一年增长,在技术上没有什么特长,这一点是很要命的,没有一技之长很快就会被淘汰。于是,夯实基础成为了上半年计划的重中之重,紧接着数据结构、算法就提上了日程。
现在手头上有本大学教材《数据结构——c语言描述》,而我又打算把c/c++再看一遍,即使有6,7年没有接触过c语言了,我想它也不会成为拦路之虎。而实际用的还是java语言,所以看看jdk是如何实现数据结构的成了顺理成章的事。
进入正题,先从最简单易懂的线性表顺序存储开始。首先来看一下顺序表的存储结构,有图有真相。
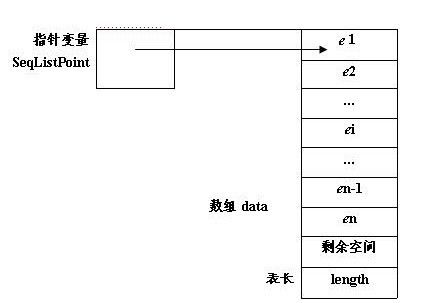
c语言描述如下:
#define MAXSIZE=50
typedef struct
{
ElemType elem[MAXSIZE];
int last;
} SeqList;
结构比较简单。下面,再来看看jdk是如何实现的。
属性的定义:
private transient Object[] elementData; private int size;
和c语言是如此相似,呵呵,不过细心的童鞋可能看到了,为何elementData要用transient来修饰了呢,它表示不需要序列化啊?法无定法,随心即法,对此不了解又想了解的可以看看我的另一篇文章——ArrayList源码分析——如何实现Serializable,地址:http://java-road-126-com.iteye.com/admin/blogs/1463313。
回归正题,接着聊方法。
1.初始化,
public ArrayList(int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
}
//默认是elementData的长度是10,注意此时size是0
public ArrayList() {
this(10);
}
2.查找,分为按序号查找和按内容查找。
//按序号查找
public E get(int index) {
RangeCheck(index);
return (E) elementData[index];
}
//越界会抛出runtime exception
private void RangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: "+size);
}
//按内容查找
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
// o为null也会判断是否elementData有为null的值,
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
3.插入,分为在末尾插入和在中间插入
//末尾插入 ,也可以用调用add重载方法实现,你想到了吧!当然,这个性能是要快的,什么?你想知道为什么,自己想去。
public boolean add(E e) {
ensureCapacity(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
/**
*数组在越界时,增加长度,每次增加原来的1/2 + 1, 为什么加1的原因,我想是因为oldCapacity=1时,(oldCapacity * 3)/2 =1 的原因
**/
public void ensureCapacity(int minCapacity) {
modCount++;
int oldCapacity = elementData.length;
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
int newCapacity = (oldCapacity * 3)/2 + 1;
//该方法是public,所以有这样的判断,可能用户希望更大的数组,不是吗?
if (newCapacity < minCapacity)
newCapacity = minCapacity;
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
//中间插入
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: "+size);
ensureCapacity(size+1); // Increments modCount!!
//System.arraycopy 是native方法,传说比for循环数组要快,我想不仅仅是传说吧,可以验证的!:-D
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
4.删除,分为按序号删除和按内容删除,按范围删除
//按序号删除
public E remove(int index) {
RangeCheck(index);
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // Let gc do its work
return oldValue;
}
//按内容删除
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
//fastRemove比remove少了个RangeCheck校验,是要稍快写的
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // Let gc do its work
}
由于替换等操作比较简单,就不做介绍了,从各个方法的实现方式可以看到,ArrayList擅长于随机访问,对于在中间插入元素,则代价是比较高的,等分析完LinkedList后,会做一个性能比较。
各位看官,注意到了没有,对elementData改变的方法都用到了modCount++,你觉得是用来搞么事的呢?
不急,等我写结合JDK学习设计模式时再分析,什么?你说很急,现在就想知道,ok,提醒你一句,在iterator里会用到的,据说next()的时候,并发又有对ArrayList的更改操作,于是乎就读脏数据了,所以抛出了运行时异常。
你也不知道并发是搞么事,哎,事情有多了。好,等我写结合JDK学习并发时再分析。这回你不自己学TIJ真得等了,我连提醒都不提醒你了,因为,大周末的,我要搞别的事了。