这一阶段的主要工作是建立了一个小的集群,并导入了少量用户进行测试。为了满足用户的需求,我们还调研了任务调度系统和数据交换系统。
我们使用的版本是当时最新的稳定版,Hadoop 0.20.203和Hive 0.7.1。此后经历过多次升级与Bugfix。现在使用的是Hadoop 1.0.3+自有Patch与Hive 0.9+自有Patch。考虑到人手不足及自己的Patch不多等问题,我们采取的策略是,以Apache的稳定版本为基础,尽量将自己的修改提交到社区,并且应用这些还没有被接受的 Patch。因为现在Hadoop生态圈中还没有出现一个类似Red Hat地位的公司,我们也不希望被锁定在某个特定的发行版上,更重要的是Apache Jira与Maillist依然是获取Hadoop相关知识、解决Hadoop相关问题最好的地方(Cloudera为CDH建立了私有的Jira,但人气不足),所以没有采用Cloudera或者Hortonworks的发行版。目前我们正对Hadoop 2.1.0进行测试。
在前期,我们团队的主要工作是ops+solution,现在DBA已接手了很大一部分ops的工作,我们正在转向solution+dev的工作。
我们使用Puppet管理整个集群,用Ganglia和Zabbix做监控与报警。
集群搭建好,用户便开始使用,面临的第一个问题是需要任务级别的调度、报警和工作流服务。当用户的任务出现异常或其他情况时,需要以邮件或者短信的方式通知用户。而且用户的任务间可能有复杂的依赖关系,需要工作流系统来描述任务间的依赖关系。我们首先将目光投向开源项目Apache Oozie。Oozie是Apache开发的工作流引擎,以XML的方式描述任务及任务间的依赖,功能强大。但在测试后,发现Oozie并不是一个很好的选择。
Oozie采用XML作为任务的配置,特别是对于MapReduce Job,需要在XML里配置Map、Reduce类、输入输出路径、Distributed Cache和各种参数。在运行时,先由Oozie提交一个Map only的Job,在这个Job的Map里,再拼装用户的Job,通过JobClient提交给JobTracker。相对于Java编写的Job Runner,这种XML的方式缺乏灵活性,而且难以调试和维 护。先提交一个Job,再由这个Job提交真正Job的设计,我个人认为相当不优雅。
另一个问题在于,公司内的很多用户,希望调度系统不仅可以调度Hadoop任务,也可以调度单机任务,甚至Spring容器里的任务,而Oozie并不支持Hadoop集群之外的任务。
所以我们转而自行开发调度系统Taurus(https://github.com/dianping/taurus)。Taurus是一个调度系统, 通过时间依赖与任务依赖,触发任务的执行,并通过任务间的依赖管理将任务组织成工作流;支持Hadoop/Hive Job、Spring容器里的任务及一般性任务的调度/监控。

图1 Taurus的结构图
图1是Taurus的结构图,Taurus的主节点称为Master,Web 界面与Master在一起。用户在Web界面上创建任务后,写入MySQL做持久化存储,当Master判断任务触发的条件满足时,则从MySQL中读出 任务信息,写入ZooKeeper;Agent部署在用户的机器上,观察ZooKeeper上的变化,获得任务信息,启动任务。Taurus在2012年 中上线。
另一个迫切需求是数据交换系统。用户需要将MySQL、MongoDB甚至文件中的数据导入到HDFS上进行分析。另外一些用户要将HDFS中生成的数据再导入MySQL作为报表展现或者供在线系统使用。
我们首先调研了Apache Sqoop,它主要用于HDFS与关系型数据库间的数据传输。经过测试,发现Sqoop的主要问题在于数据的一致性。Sqoop采用 MapReduce Job进行数据库的插入,而Hadoop自带Task的重试机制,当一个Task失败,会自动重启这个Task。这是一个很好的特性,大大提高了Hadoop的容错能力,但对于数据库插入操作,却带来了麻烦。
考虑有10个Map,每个Map插入十分之一的数据,如果有一个Map插入到一半时failed,再通过Task rerun执行成功,那么fail那次插入的一半数据就重复了,这在很多应用场景下是不可接受的。 而且Sqoop不支持MongoDB和MySQL之间的数据交换,但公司内却有这需求。最终我们参考淘宝的DataX,于2011年底开始设计并开发了Wormhole。之所以采用自行开发而没有直接使用DataX主要出于维护上的考虑,而且DataX并未形成良好的社区。
2012年大规模应用
2012年,出于成本、稳定性与源码级别维护性的考虑,公司的Data Warehouse系统由商业的OLAP数据库转向Hadoop/Hive。2012年初,Wormhole开发完成;之后Taurus也上线部署;大量应用接入到Hadoop平台上。为了保证数据的安全性,我们开启了Hadoop的Security特性。为了提高数据的压缩率,我们将默认存储格式替换为RCFile,并开发了Hive Web供公司内部使用。2012年底,我们开始调研HBase。
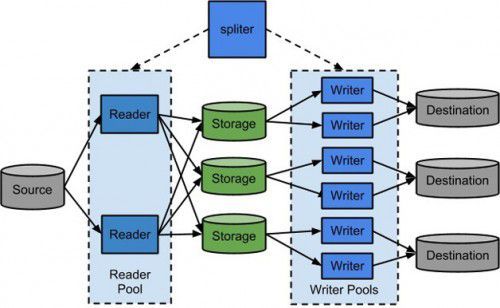
图2 Wormhole的结构图
Wormhole(https://github.com /dianping/wormhole)是一个结构化数据传输工具,用于解决多种异构数据源间的数据交换,具有高效、易扩展等特点,由Reader、 Storage、Writer三部分组成(如图2所示)。Reader是个线程池,可以启动多个Reader线程从数据源读出数据,写入Storage。 Writer也是线程池,多线程的Writer不仅用于提高吞吐量,还用于写入多个目的地。Storage是个双缓冲队列,如果使用一读多写,则每个目的地都拥有自己的Storage。
当写入过程出错时,将自动执行用户配置的Rollback方法,消除错误状态,从而保证数据的完整性。通过开发不同的Reader和Writer插件,如MySQL、MongoDB、Hive、HDFS、SFTP和Salesforce,我们就可以支持多种数据源间的数据交换。Wormhole在大众点评内部得到了大量使用,获得了广泛好评。
随着越来越多的部门接入Hadoop,特别是数据仓库(DW)部门接入后,我们对数据的安全性需求变得更为迫切。而Hadoop默认采用Simple的用户认证模式,具有很大的安全风险。
默认的Simple认证模式,会在Hadoop的客户端执行whoami命令,并以whoami命令的形式返回结果,作为访问Hadoop的用户名(准确地说,是以whoami的形式返回结果,作为Hadoop RPC的userGroupInformation参数发起RPC Call)。这样会产生以下三个问题。
(1)User Authentication。假设有账号A和账号B,分别在Host1和Host2上。如果恶意用户在Host2上建立了一个同名的账号A,那么通过RPC Call获得的UGI就和真正的账号A相同,伪造了账号A的身份。用这种方式,恶意用户可以访问/修改其他用户的数据。
(2)Service Authentication。Hadoop采用主从结构,如NameNode-DataNode、JobTracker-Tasktracker。Slave节点启动时,主动连接Master节点。Slave到Master的连接过程,没有经过认证。假设某个用户在某台非Hadoop机器上,错误地启动了一个Slave实例,那么也会连接到Master;Master会为它分配任务/数据,可能会影响任务的执行。
(3)可管理性。任何可以连到Master节点的机器,都可以请求集群的服务,访问HDFS,运行Hadoop Job,无法对用户的访问进行控制。
从Hadoop 0.20.203开始,社区开发了Hadoop Security,实现了基于Kerberos的Authentication。任何访问Hadoop的用户,都必须持有KDC(Key Distribution Center)发布的Ticket或者Keytab File(准确地说,是Ticket Granting Ticket),才能调用Hadoop的服务。用户通过密码,获取Ticket,Hadoop Client在发起RPC Call时读取Ticket的内容,使用其中的Principal字段,作为RPC Call的UserGroupInformation参数,解决了问题(1)。Hadoop的任何Daemon进程在启动时,都需要使用Keytab File做Authentication。因为Keytab File的分发是由管理员控制的,所以解决了问题(2)。最后,不论是Ticket,还是Keytab File,都由KDC管理/生成,而KDC由管理员控制,解决了问题(3)。
在使用了Hadoop Security之后,只有通过了身份认证的用户才能访问Hadoop,大大增强了数据的安全性和集群的可管理性。之后我们基于Hadoop Secuirty,与DW部门一起开发了ACL系统,用户可以自助申请Hive上表的权限。在申请通过审批工作流之后,就可以访问了。
JDBC是一种很常用的数据访问接口,Hive自带了Hive Server,可以接受Hive JDBC Driver的连接。实际 上,Hive JDBC Driver是将JDBC的请求转化为Thrift Call发给Hive Server,再由Hive Server将Job 启动起来。但Hive自带的Hive Server并不支持Security,默认会使用启动Hive Server的用户作为Job的owner提交到 Hadoop,造成安全漏洞。因此,我们自己开发了Hive Server的Security,解决了这个问题。
但在Hive Server的使用过程中,我们发现Hive Server并不稳定,而且存在内存泄漏。更严重的是由于Hive Server自身的设计缺陷,不能很好地应对并发访问的情况,所以我们现在并不推荐使用Hive JDBC的访问方式。
社区后来重新开发了Hive Server 2,解决了并发的问题,我们正在对Hive Server 2进行测试。
有一些同事,特别是BI的同事,不熟悉以CLI的方式使用Hive,希望Hive可以有个GUI界面。在上线Hive Server之后,我们调研了开源的SQL GUI Client——Squirrel,可惜使用Squirrel访问Hive存在一些问题。
- 办公网与线上环境是隔离的,在办公机器上运行的Squirrel无法连到线上环境的Hive Server。
- Hive会返回大量的数据,特别是当用户对于Hive返回的数据量没有预估的情况下,Squirrel会吃掉大量的内存,然后Out of Memory挂掉。
- Hive JDBC实现的JDBC不完整,导致Squirrel的GUI中只有一部分功能可用,用户体验非常差。
基于以上考虑,我们自己开发了Hive Web,让用户通过浏览器就可以使用Hive。Hive Web最初是作为大众点评第一届Hackathon的一个项目被开发出来的,技术上很简单,但获得了良好的反响。现在Hive Web已经发展成了一个RESTful的Service,称为Polestar(https://github.com/dianping /polestar)。
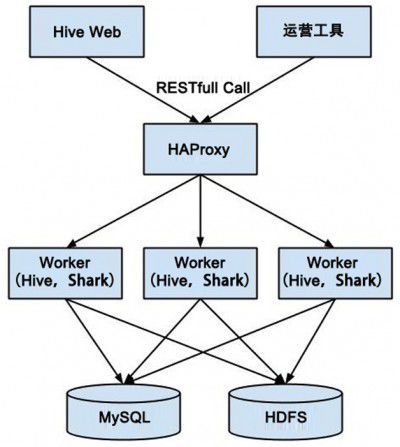
图3 Polestar的结构
图3是Polestar的结构图。目前Hive Web只是一个GWT的前端,通过HAProxy将RESTfull Call分发到执行引擎Worker执行。Worker将自身的状态保存在MySQL,将数据保存在HDFS,并使用JSON返回数据或数据在HDFS的 路径。我们还将Shark与Hive Web集成到了一起,用户可以选择以Hive或者Shark执行Query。
一开始我们使用LZO作为存储格式,使大文件可以在MapReduce处理中被切分,提高并行度。但LZO的压缩比不够高,按照我们的测试,Lzo压缩的文件,压缩比基本只有Gz的一半。
经过调研,我们将默认存储格式替换成RCFile,在RCFile内部再使用Gz压缩,这样既可保持文件可切分的特性,同时又可获得Gz的高压缩比,而且因 为RCFile是一种列存储的格式,所以对于不需要的字段就不用从I/O读入,从而提高了性能。图4显示了将Nginx数据分别用Lzo、 RCFile+Gz、RCFfile+Lzo压缩,再不断增加Select的Column数,在Hive上消耗的CPU时间(越小越好)。
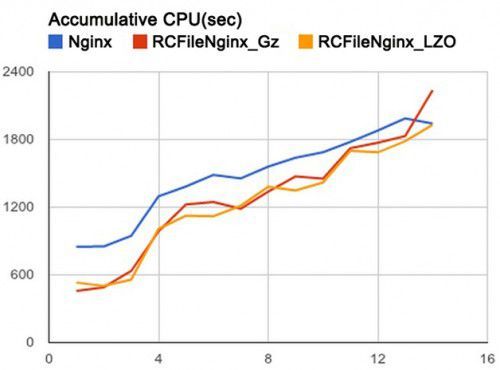
图4 几种压缩方式在Hive上消耗的CPU时间
但RCFile的读写需要知道数据的Schema,而且需要熟悉Hive的Ser/De接口。为了让MapReduce Job能方便地访问RCFile,我们使用了Apache Hcatalog。
社区又针对Hive 0.11开发了ORCFile,我们正在对ORCFile进行测试。
随着Facebook、淘宝等大公司成功地在生产环境应用HBase,HBase越来越受到大家的关注,我们也开始对HBase进行测试。通过测试我们发现 HBase非常依赖参数的调整,在默认配置下,HBase能获得很好的写性能,但读性能不是特别出色。通过调整HBase的参数,在5台机器的HBase 集群上,对于1KB大小的数据,也能获得5万左右的TPS。在HBase 0.94之后,HBase已经优化了默认配置。
原来我们希望HBase集群与主Hadoop集群共享HDFS,这样可以简化运维成本。但在测试中,发现即使主Hadoop集群上没有任何负载,HBase的性能也很糟糕。我们认为,这是由于大量数据属于远程读写所引起的。所以我们现在的HBase集群都是单独部署的。并且通过封装HBase Client与Master-Slave Replication,使用2套HBase集群实现了HBase的HA,用来支撑线上业务。
2013年持续演进
在建立了公司主要的大数据架构后,我们上线了HBase的应用,并引入Spark/Shark以提高Ad Hoc Query的执行时间,并调研分布式日志收集系统,来取代手工脚本做日志导入。
现在HBase上线的应用主要有OpenAPI和手机团购推荐。OpenAPI类似于HBase的典型应用Click Stream,将开放平台开发者的访问日志记录在HBase中,通过Scan操作,查询开发者在一段时间内的Log,但这一功能目前还没有对外开放。手机 团购推荐是一个典型的KVDB用法,将用户的历史访问行为记录在HBase中,当用户使用手机端访问时,从HBase获得用户的历史行为数据,做团购推 荐。
当Hive大规模使用之后,特别是原来使用OLAP数据库的BI部门的同事转入后,一个越来越大的抱怨就是Hive的执行速度。对于离 线的ETL任务,Hadoop/Hive是一个良好的选择,但动辄分钟级的响应时间,使得Ad Hoc Query的用户难以忍受。为了提高Ad Hoc Query的响应时间,我们将目光转向了Spark/Shark。
Spark是美国加州大学伯克利分校AMPLab开发的分布式计算系统,基于RDD(Resilient Distributed Dataset),主要使用内存而不是硬盘,可以很好地支持迭代计算。因为是一个基于Memory的系统,所以在数据量能够放进Memory的情况下,能 够大幅缩短响应时间。Shark类似于Hive,将SQL解析为Spark任务,并且Shark复用了大量Hive的已有代码。
在Shark接入之后,大大降低了Ad Hoc Query的执行时间。比如SQL语句:
select host, count(1) from HIPPOLOG where dt = '2013-08-28' group by host order by host desc;
在Hive执行的时间是352秒,而Shark只需要60~70秒。但对于Memory中放不下的大数据量,Shark反而会变慢。
目前用户需要在Hive Web中选择使用Hive还是Shark,未来我们会在Hive中添加Semantic-AnalysisHook,通过解析用户提交的Query,根据 数据量的大小,自动选择Hive或者Shark。另外,因为我们目前使用的是Hadoop 1,不支持YARN,所以我们单独部署了一个小集群用于Shark任务的执行。
Wormhole解决了结构化数据的交换问题,但对于非结构化数据,例如各种日志,并不适合。我们一直采用脚本或用户程序直接写HDFS的方式将用户的Log导入HDFS。缺点是,需要一定的开发和维护成本。我们 希望使用Apache Flume解决这个问题,但在测试了Flume之后,发现了Flume存在一些问题:Flume不能保证端到端的数据完整性,数据可能丢失,也可能重复。
例如,Flume的HDFSsink在数据写入/读出Channel时,都有Transcation的保证。当Transaction失败时,会回滚,然后重试。但由于HDFS不可修改文件的内容,假设有1万行数据要写入HDFS,而在写入5000行时,网络出现问题导致写入失败,Transaction回滚,然后重写这10000条记录成功,就会导致第一次写入的5000行重复。我们试图修正Flume的这些问题,但由于这些问题是设计上的,并不能通过简单的Bugfix来解决,所以我们转而开发Blackhole系统将数据流导入HDFS。目前Blackhole正在开发中。
总结
图5是各系统总体结构图,深蓝部分为自行开发的系统。
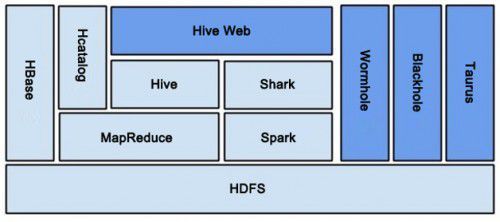
图5 大众点评各系统总体结构图
在这2年多的Hadoop实践中,我们得到了一些宝贵经验。
- 建设一支强大的技术团队是至关重要的。Hadoop的生态系统,还处在快速演化中,而且文档相当匮乏。只有具备足够强的技术实力,才能用好开源软件,并在开源软件不能满足需求时,自行开发解决问题。
- 要立足于解决用户的需求。用户需要的东西,会很容易被用户接受,并推广开来;某些东西技术上很简单,但可以解决用户的大问题。
- 对用户的培训,非常重要。