java笔记:关于复杂数据存储的问题--基础篇:数组以及浅拷贝与深拷贝的问题
记得我在写javascript笔记时候说过:程序就是由数据和运算组成。所以对数据存储以及读取方式的研究是熟练掌握语言精髓的重要途径。我在上篇文章里说道我想重新回顾一些知识,这些知识就是数据存储的问题,而且是复杂数据存储的问题。我个人认为一名优秀的程序员应该有四个主要指标:一是项目经验,二是程序优化的能力,三是良好的设计理念,四是快速准确定位程序bug的能力。项目经验不说,这个需要积累,而其他的能力都是可以通过学习而不断强化的。而语言中数据存储能力掌握的优劣是你优化程序的水平的高低的重要指标,你想让自己的程序越来越快,按什么数据模型快速存储数据,并且能很快的检索被存储的数据才是程序优化的本质,因此学习数据的存储方式特别是复杂数据的存储方式就十分的重要了。
(学习和提高是永无止尽的,我不是技术狂热分子,但我是一个想把事业做精做透的人,更想自己有一天能做到真正意义的创新,所以我要不断的自我激励,时刻准备抓住机会和灵感的那天,因为我相信创新的灵感和机会源自于你不断准备灵感和机会到来的这个过程之中。)
呵呵,不说大话了,开始干实事了。不想创新,我只想写程序时候思路开阔,不会只要是数组就写ArrayList,碰到键值对就是HashMap,也许我们会有更好的选择,但你一定要知道更好的选择是什么。
java的第一个真理:在java里除了基本类型就是对象。java比C好用的一个重要指标:java里提供了大量对对象操作的集合类,这些集合类大部分都在java.util包里。
但是第一个用来存储复杂数据的数据结构不是List、Set或者是Map,而是数组(Array)。我就先从数组说起。
如何定义数组
如果有位面试官让你说出这个问题的答案,你能很全面的说出来吗?或许很多童鞋可以,但是我好几次都回答的不全面,大家先看下面的代码:
结果如下:
b5.length:3
b6.length:3
b7.length:3
下面我就对注释做一一解释:
注释一:java里提供了两组定义数组的方式,二者是等价的,而int a2[]是C和C++语言的风格。在java里定义一个数组只是表明某个变量获得了数组的引用,但此时数组是没有被分配任何空间的,要让数组获得相应的内存空间就得对数组进行初始化。
注释二:假如我们知道我们那些数据要放到数组中,这些数据是确定无疑的,那么注释二的做法是一个简便的 数组初始化方式:直接使用花括号初始化数组。
注释三:这个实例给了我们另外一种选择:当我们只知道数组的个数而不知道数组内容时候数组该如何定义了?这个时候数组的length属性里存储了数组的长度,length或许是我们在使用数组这个数据结构中最常用的一个属性,适当了用局部变量记下它的值,而不是每次通过数组重新计算length的值是一种提高程序效率的有效方式。
注释四:这里我将数据类型换成了对象,用法和基本类型一样。
注释五:用花括号初始化对象,大家看到对于Integer类型我们可以直接使用int类型初始化,java会自动把int转化这个Integer对象。
注释六:这里给出了对象数组定义的另一种做法,效果和注释五下面的代码类似,不过注释六下面的代码会灵活点,例如我们把Integer换成Object,那么这个数组就变成了通用数组了,这个小技巧太小儿科了,这里就不深入了。
虽然数组存储基本类型和对象从代码表象上看用法差不多,但是它们在本质上还是有区别的:对象的数组保存的是引用而基本类型的数组是直接保存基本类型的值。
在java里我们会常常忽视数组,这是一个极其不好的习惯,数组不管在那个编程语言里它有时都会是优秀的复杂数据存储结构,我们把数组和java里的ArrayList类作比较,数组有如下的优势:
效率很高:数组是java中一种效率最高的存储和随机访问对象引用的方式,数组是使用一个简单的线性结构,这就让线程的访问速度非常的快。另外线程的长度是固定的,这就免去了动态长度所带来的性能开销,这也是数组比较快的重要原因。最后数组存储的数据都是统一类型的,因此使用数组时候就少了对数据类型的校验和转化工作,这样数组的效率相比集合类的那种可以存储任何类型的的特点比较起来,效率又会提升很多。
数组有存储基本类型的能力:java中的集合类是针对对象的存储设计的,而数组是什么数据类型都可以作为它的存储的内容。
不过java的util包还是提供对数组操作的工具类Arrays,该类的方式都是静态使用起来很方便,但是我个人觉得这个类使用价值不大,很多功能我们自己去写可能会更好些。
Arrays虽然不讨我喜欢,但是System类里的arraycopy倒是很讨我喜欢,在看大伙看代码之前我们先看看arrayCopy方法在jdk文档里的解释吧:
arraycopy
public static void arraycopy(Object src,
int srcPos,
Object dest,
int destPos,
int length)从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束。从 src 引用的源数组到 dest 引用的目标数组,数组组件的一个子序列被复制下来。被复制的组件的编号等于 length 参数。源数组中位置在 srcPos 到 srcPos+length-1 之间的组件被分别复制到目标数组中的 destPos 到 destPos+length-1 位置。
如果参数 src 和 dest 引用相同的数组对象,则复制的执行过程就好像首先将 srcPos 到 srcPos+length-1 位置的组件复制到一个带有 length 组件的临时数组,然后再将此临时数组的内容复制到目标数组的 destPos 到 destPos+length-1 位置一样。
If 如果 dest 为 null,则抛出 NullPointerException 异常。
如果 src 为 null, 则抛出 NullPointerException 异常,并且不会修改目标数组。
否则,只要下列任何情况为真,则抛出 ArrayStoreException 异常并且不会修改目标数组:
src 参数指的是非数组对象。
dest 参数指的是非数组对象。
src 参数和 dest 参数指的是那些其组件类型为不同基本类型的数组。
src 参数指的是具有基本组件类型的数组且 dest 参数指的是具有引用组件类型的数组。
src 参数指的是具有引用组件类型的数组且 dest 参数指的是具有基本组件类型的数组。
否则,只要下列任何情况为真,则抛出 IndexOutOfBoundsException 异常,并且不会修改目标数组:
srcPos 参数为负。
destPos 参数为负。
length 参数为负。
srcPos+length 大于 src.length,即源数组的长度。
destPos+length 大于 dest.length,即目标数组的长度。
否则,如果源数组中 srcPos 到 srcPos+length-1 位置上的实际组件通过分配转换并不能转换成目标数组的组件类型,则抛出 ArrayStoreException 异常。在这种情况下,将 k 设置为比长度小的最小非负整数,这样就无法将 src[srcPos+k] 转换为目标数组的组件类型;当抛出异常时,从 srcPos 到 srcPos+k-1 位置上的源数组组件已经被复制到目标数组中的 destPos 到 destPos+k-1 位置,而目标数组中的其他位置不会被修改。(因为已经详细说明过的那些限制,只能将此段落有效地应用于两个数组都有引用类型的组件类型的情况。)
参数:
src - 源数组。
srcPos - 源数组中的起始位置。
dest - 目标数组。
destPos - 目标数据中的起始位置。
length - 要复制的数组元素的数量。
抛出:
IndexOutOfBoundsException - 如果复制会导致对数组范围以外的数据的访问。
ArrayStoreException - 如果因为类型不匹配而使得无法将 src 数组中的元素存储到 dest 数组中。
NullPointerException - 如果 src 或 dest 为 null。
我们的代码如下:
运行结果如下:
========================基本数据类型==========================
[7, 7, 7, 7, 7]arr1的长度是:5
[9, 9, 9, 9, 9, 9, 9, 9, 9]arr2的长度是:9
新的数组:[7, 7, 7, 7, 7, 9, 9, 9, 9]arr2的长度是:9
========================对象的操作==========================
[7, 7, 7, 7, 7]arrObj1的长度是:5
[9, 9, 9, 9, 9, 9, 9, 9, 9]arrObj2的长度是:9
新的数组:[7, 7, 7, 7, 7, 9, 9, 9, 9]arrObj2的长度是:9
代码里我顺便演示了Arrays类的部分功能,使用数组经常因为数组大小一开始就固定好的缺点,我们不得不去重新拷贝数组,System.arraycopy方法提供了一个十分简便的方案,不过这个方法也是有问题的,从代码里我们可以认为System的arrayCopy方法什么样的数组都可以拷贝,但是对象数组的拷贝就有点不同,对象拷贝复制的是对象的引用而非对象的本身,这种拷贝叫做浅拷贝(shallow copy)。
方法的问题就是这个浅拷贝所造成,下面我就谈谈浅拷贝以及它对应的深拷贝。
浅拷贝和深拷贝的定义如下:
浅拷贝:比如A对象被复制到B对象,但是B对象只是复制了A对象本身,如果A对象里还有存在指向其他对象数组或者是引用,B对象内部不会复制这些内部的信息而是指向原来A对象引用的信息。
深拷贝:还是列举A对象被复制到B对象的例子,B对象拷贝到的是A对象的所有信息,包括A对象内部的对象引用。
可能看到上面的解释很多人还是不太清晰浅拷贝和深拷贝的区别,我下面用图形来展示它们的区别,首先是A对象,A里包含了两个内部对象innerA和innerB,如下图:
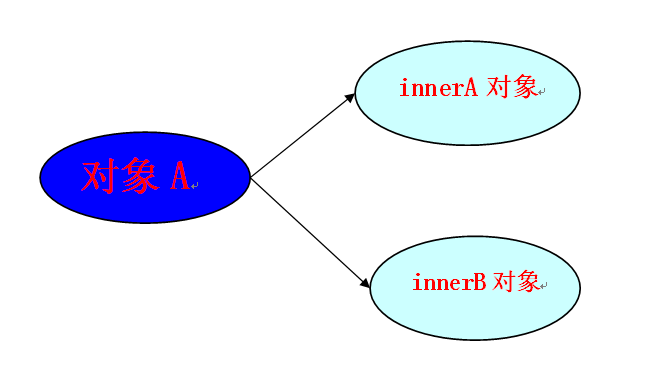
如果把A对象拷贝到B对象,但是B对象内部并没有拷贝innerA对象和innerB对象,B对象内部还是指向原来的innerA对象和innerB对象,如下图:
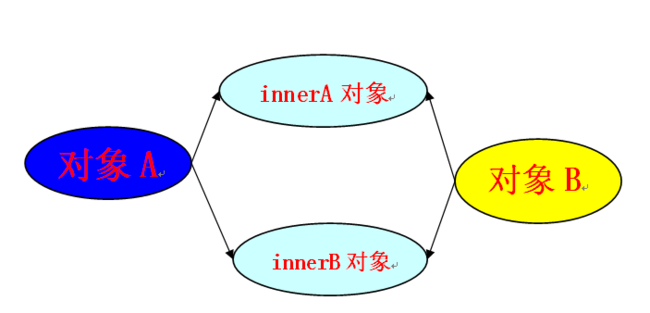
如果把A对象深拷贝到B对象,那么结果如下图:
A的内部对象也会拷贝到B对象内部。
上面的图形应该可以清晰的表达出浅拷贝和深拷贝的区别了吧。为什么会有浅拷贝和深拷贝了,到底是什么原因产生了浅拷贝和深拷贝了?昨天一个朋友用C语言的方式给我做了解答,哎,可惜C语言我只是在大学里学过,现在忘记的差不多了,但是我哪位朋友指出了浅拷贝和深拷贝是因为指针所产生的,产生的条件就是值的传递和返回,本质是数据在内存中存放的方式所造成。
下面我就要探求深浅拷贝的本质了,首先我又要说一个java语言里的真理:Java中所有参数传递都是按引用传递。
引用,引用还是引用,我前面讲了太多引用了啊。
今天写累了,我下一篇博文就从这个万恶的引用讲起。
重新研究编程语言是件很开心的事情,特别是在你已经做过一些项目以后你再看使用的语言的语法知识,你会有种豁然开朗的感觉:你知道那些知识很有用,那些知识比较难,更重要的是你知道你重新复习这些技术你今后能把他们用到什么样的地方,或许有人说这些都是基础,我们都做不少的项目了,何必再浪费时间,但你如果是对你所做的技术有更高的要求,你想进步而不是应付工作,学精一个东西一定会让你的成长不会很快碰到瓶颈了,不断学习和工作的人总会比懈怠的人收获的更多,这就是我的想法。
我们首先看看下面代码:
代码是在定义字符串,我想所有学过编程语言的人都知道这是怎么回事,但是二者是有区别的:@1这里只是创建了字符串对象的引用,而实际的对象是没有被创建的,@2既创建了字符串对象的引用也创建了引用对应的对象(其实就是我们经常做的初始化操作),大家看到代码如果我们使用str2对象程序可以正常运行,但是如果我们同样去使用str1时候,程序会报编译错误,错误内容如下:
The local variable str1 may not have been initialized
那么在java里引用到底是怎么定义的呢?
引用(reference):能操作java对象的标示符被称为引用。
我们再看上面的例子,引用就是指str1和str2两个标示符,有人一定会奇怪:我们要的是对象,你说现在我们看到只是对象的标示符,那么对象到哪里去了啊?要回答这个问题就要说说对象和引用的关系了,他们的关系是:对象和引用的关系我们可以想象成遥控器(引用)和电视机(对象),用户通过掌握遥控器来控制对电视机的使用,我们要转移对电视机的操作权也就是转移遥控器的控制权而已。
这样的存储和操作对象的方式在编程语言里并不神秘,其实java里的方式还算比较简单的,总比C或者C++语言里的指针要简单许多。这里我也要强调下,有很多人认为java里的引用就是C里面的指针,但是很多经典的java的书籍里都否认这样的说法,我以前面试有人这么问过我,但是那时我就回答的是指针,虽然很多时候面试并没有否定,但也有人会刨根问底,最后搞的你不知道如何回答是好,其实java里的引用可以说成指针,但是这个指针是有限的指针,用户无法控制的指针,我想要是再碰到这样的问题我就说java里的引用就是被阉割的指针。
编程语言里变量的存储归结到计算机的底层都是内存的分配问题,知道java语言里数据在内存的分配方式,对我们编写程序一定会有帮助的,在java里有六种不同的存储方式:
寄存器:这是最快的保存区域,因为它位于和其他所有保存方式不同的地方:处理器内部。然而,寄存 器的数量十分有限,所以寄存器是根据需要由编译器分配。我们对此没有直接的控制权,也不可能在自己的 程序里找到寄存器存在的任何踪迹。
堆栈:驻留于常规 RAM (随机访问存储器)区域,但可通过它的“堆栈指针”获得处理的直接支持。堆 栈指针若向下移,会创建新的内存;若向上移,则会释放那些内存。这是一种特别快、特别有效的数据保存 方式,仅次于寄存器。创建程序时,Java 编译器必须准确地知道堆栈内保存的所有数据的“长度”以及“存 在时间”。这是由于它必须生成相应的代码,以便向上和向下移动指针。这一限制无疑影响了程序的灵活 性,所以尽管有些 Java 数据要保存在堆栈里——特别是对象句柄,但Java 对象并不放到其中。
堆:一种常规用途的内存池(也在 RAM 区域),其中保存了Java 对象。和堆栈不同,“内存堆”或 “堆”(Heap )最吸引人的地方在于编译器不必知道要从堆里分配多少存储空间,也不必知道存储的数据要 在堆里停留多长的时间。因此,用堆保存数据时会得到更大的灵活性。要求创建一个对象时,只需用new 命 令编制相关的代码即可。执行这些代码时,会在堆里自动进行数据的保存。当然,为达到这种灵活性,必然 会付出一定的代价:在堆里分配存储空间时会花掉更长的时间!
静态存储:这儿的“静态”(Static)是指“位于固定位置”(尽管也在RAM 里)。程序运行期间,静 态存储的数据将随时等候调用。可用 static 关键字指出一个对象的特定元素是静态的。但 Java 对象本身永 远都不会置入静态存储空间。
常数存储:常数值通常直接置于程序代码内部。这样做是安全的,因为它们永远都不会改变。有的常数 需要严格地保护,所以可考虑将它们置入只读存储器(ROM)。
非RAM 存储:若数据完全独立于一个程序之外,则程序不运行时仍可存在,并在程序的控制范围之外。 其中两个最主要的例子便是“流式对象”和“固定对象”。对于流式对象,对象会变成字节流,通常会发给 另一台机器。而对于固定对象,对象保存在磁盘中。即使程序中止运行,它们仍可保持自己的状态不变。对 于这些类型的数据存储,一个特别有用的技巧就是它们能存在于其他媒体中。一旦需要,甚至能将它们恢复 成普通的、基于RAM 的对象。
Java里基本类型和引用都是存放到堆栈里,因为它们所占的空间比较少,没有必要放到堆内存中去,而存在堆栈里使用起来会更高效。这里还要说的是数组,数组可以和对象等同,哪怕你在创建一个基本类型的数组也是如此,数组可以完全当做对象来使用。
现在我们可以回到我们在上篇要谈的内容:java里对象的传递和返回都是通过引用传递和返回的,这就是导致System.arraycopy方法是浅拷贝的症结了。下面的代码显示了java是按引用传递的:我们把一个引用传入到某个方法里,我们在方法内部发现传入的引用指向的还是原来的对象,大家看下面的代码:
运行结果如下:
p inside main():cn.com.sxia.PassRef@119298d
h inside f():cn.com.sxia.PassRef@119298d
大家看到了p和h引用都是指向了同一个对象,因为他们的地址是一样的。
Java里还有一个别名效应的问题。
别名效应:是指多个引用指向同一个对象。这种情况就是一台电视机多台遥控器,突然一个遥控器换了台,其他的遥控器可能并不想换台,这就有问题了。
大家看下面的代码:
运行结果如下:
x: 7
y: 7
增加变量x里的i的数值:
x: 8
y: 8
大家可以看到x和y变量的值都被改变了。这种被串行修改的情况我们大多时候都不愿意发生。解决这个问题的方法很简单:不要在同一个作用域里生成多个对象的引用,特别是传值的时候,我们不要随意用局部变量存储传来的值。
但是在一个局部环境里(局部环境就是一个方法内的作用域),我们从外部传参数进来总会产生这样的问题。那么在一个局部环境也就是在一个方法内的作用域里,变量和对象到底是什么样的情况,很高兴有些人总结了这里面的情况:
当我们向方法里传递参数别名的效应就会发生。这个很好理解了,当传参数时候,局部环境外部有个引用和局部环境内部的参数的引用都是指向了同一个对象,多个引用指向同一个对象就是别名效应了。
在一个局部环境里,我们构建一个对象,这个对象有引用,引用是属于这个局部环境的,离开了局部环境引用就被销毁,但是创建的对象还会存在,特别是我们用了return关键字返回时候,外部会有另外一个引用使用到这个对象,所以局部环境内没有局部对象只有局部引用。
上面的问题还引出了一种情况:在局部环境里引用是有作用域的,但是对象是没有的,对象的销毁是在没有可以使用该对象的引用后在一定时间内被垃圾回收机制所回收。
在java里我们关心的是引用的生命周期,而不是对象的生命周期,对象的生命周期是java自己管理的。
引用传递虽然存在很多问题,但是引用传递是java默认的传递方式,因为大多数情况引用不会影响到我们程序的正确运行,而且传递参数只传递引用也就是只对堆栈的内存进行读取,效率会更高,因此有时我们也可以片面的理解引用是java为程序的高效性所做的妥协了。
下面我就写个浅拷贝的代码,我这个小系列里不会对如果写出正确拷贝问题作出深入的分析,因为我想着重学习的是java里复杂的数据存储方式,我只是由浅拷贝引出一个很重要的观点:java里传递的是引用这个真理,这个对我后面写复杂数据存储问题很有帮助。不过在我后面的内容中也会进一步阐释深拷贝和浅拷贝的问题,解决正确拷贝的问题会穿插到我后面文章的内容之中。好了,大家看下面的代码吧:
运行结果如下:
arr1:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
arr1:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
我们使用clone方法进行复制,arr1复制到了arr2,但是arr2的改变影响到了arr1的值,这就说明这个拷贝是浅拷贝,arr2只是复制了arr1的引用,而arr1指向的对象是没有被拷贝的。实际上java里的对象由以下几个部分所组成:对象的引用,引用所指向的对象,这些对象指向的另外一些对象,一直指向下去这就构成了一个对象网络图,深拷贝就是将这整个对象网路图全拷贝下来。
下面的内容我就开始讲解多java.util包的使用了。这个是我要讲的重点了。
(学习和提高是永无止尽的,我不是技术狂热分子,但我是一个想把事业做精做透的人,更想自己有一天能做到真正意义的创新,所以我要不断的自我激励,时刻准备抓住机会和灵感的那天,因为我相信创新的灵感和机会源自于你不断准备灵感和机会到来的这个过程之中。)
呵呵,不说大话了,开始干实事了。不想创新,我只想写程序时候思路开阔,不会只要是数组就写ArrayList,碰到键值对就是HashMap,也许我们会有更好的选择,但你一定要知道更好的选择是什么。
java的第一个真理:在java里除了基本类型就是对象。java比C好用的一个重要指标:java里提供了大量对对象操作的集合类,这些集合类大部分都在java.util包里。
但是第一个用来存储复杂数据的数据结构不是List、Set或者是Map,而是数组(Array)。我就先从数组说起。
如何定义数组
如果有位面试官让你说出这个问题的答案,你能很全面的说出来吗?或许很多童鞋可以,但是我好几次都回答的不全面,大家先看下面的代码:
package cn.com.sxia;
import java.util.ArrayList;
import java.util.List;
public class ArrayDefine {
public static void main(String[] args) {
// 注释一
int[] a1;
int a2[];
// 注释二
int[] a3 = { 1, 2, 3, 4, 5 };
int a4[] = { 6, 7, 8, 9, 0 };
// 注释三
int[] a5 = new int[3];
int a6[] = new int[3];
// 注释四
Integer[] b1;
Integer b2[];
Integer[] b3 = new Integer[3];
Integer b4[] = new Integer[3];
// 注释五
Integer[] b5 = { 1, 2, 3 };
Integer[] b6 = { new Integer(4), new Integer(5), new Integer(6) };
System.out.println("b5.length:" + b5.length);
System.out.println("b6.length:" + b6.length);
// 注释六
Integer[] b7 = new Integer[] { new Integer(4), new Integer(5),
new Integer(6) };
System.out.println("b7.length:" + b7.length);
}
}
结果如下:
b5.length:3
b6.length:3
b7.length:3
下面我就对注释做一一解释:
注释一:java里提供了两组定义数组的方式,二者是等价的,而int a2[]是C和C++语言的风格。在java里定义一个数组只是表明某个变量获得了数组的引用,但此时数组是没有被分配任何空间的,要让数组获得相应的内存空间就得对数组进行初始化。
注释二:假如我们知道我们那些数据要放到数组中,这些数据是确定无疑的,那么注释二的做法是一个简便的 数组初始化方式:直接使用花括号初始化数组。
注释三:这个实例给了我们另外一种选择:当我们只知道数组的个数而不知道数组内容时候数组该如何定义了?这个时候数组的length属性里存储了数组的长度,length或许是我们在使用数组这个数据结构中最常用的一个属性,适当了用局部变量记下它的值,而不是每次通过数组重新计算length的值是一种提高程序效率的有效方式。
注释四:这里我将数据类型换成了对象,用法和基本类型一样。
注释五:用花括号初始化对象,大家看到对于Integer类型我们可以直接使用int类型初始化,java会自动把int转化这个Integer对象。
注释六:这里给出了对象数组定义的另一种做法,效果和注释五下面的代码类似,不过注释六下面的代码会灵活点,例如我们把Integer换成Object,那么这个数组就变成了通用数组了,这个小技巧太小儿科了,这里就不深入了。
虽然数组存储基本类型和对象从代码表象上看用法差不多,但是它们在本质上还是有区别的:对象的数组保存的是引用而基本类型的数组是直接保存基本类型的值。
在java里我们会常常忽视数组,这是一个极其不好的习惯,数组不管在那个编程语言里它有时都会是优秀的复杂数据存储结构,我们把数组和java里的ArrayList类作比较,数组有如下的优势:
效率很高:数组是java中一种效率最高的存储和随机访问对象引用的方式,数组是使用一个简单的线性结构,这就让线程的访问速度非常的快。另外线程的长度是固定的,这就免去了动态长度所带来的性能开销,这也是数组比较快的重要原因。最后数组存储的数据都是统一类型的,因此使用数组时候就少了对数据类型的校验和转化工作,这样数组的效率相比集合类的那种可以存储任何类型的的特点比较起来,效率又会提升很多。
数组有存储基本类型的能力:java中的集合类是针对对象的存储设计的,而数组是什么数据类型都可以作为它的存储的内容。
不过java的util包还是提供对数组操作的工具类Arrays,该类的方式都是静态使用起来很方便,但是我个人觉得这个类使用价值不大,很多功能我们自己去写可能会更好些。
Arrays虽然不讨我喜欢,但是System类里的arraycopy倒是很讨我喜欢,在看大伙看代码之前我们先看看arrayCopy方法在jdk文档里的解释吧:
arraycopy
public static void arraycopy(Object src,
int srcPos,
Object dest,
int destPos,
int length)从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束。从 src 引用的源数组到 dest 引用的目标数组,数组组件的一个子序列被复制下来。被复制的组件的编号等于 length 参数。源数组中位置在 srcPos 到 srcPos+length-1 之间的组件被分别复制到目标数组中的 destPos 到 destPos+length-1 位置。
如果参数 src 和 dest 引用相同的数组对象,则复制的执行过程就好像首先将 srcPos 到 srcPos+length-1 位置的组件复制到一个带有 length 组件的临时数组,然后再将此临时数组的内容复制到目标数组的 destPos 到 destPos+length-1 位置一样。
If 如果 dest 为 null,则抛出 NullPointerException 异常。
如果 src 为 null, 则抛出 NullPointerException 异常,并且不会修改目标数组。
否则,只要下列任何情况为真,则抛出 ArrayStoreException 异常并且不会修改目标数组:
src 参数指的是非数组对象。
dest 参数指的是非数组对象。
src 参数和 dest 参数指的是那些其组件类型为不同基本类型的数组。
src 参数指的是具有基本组件类型的数组且 dest 参数指的是具有引用组件类型的数组。
src 参数指的是具有引用组件类型的数组且 dest 参数指的是具有基本组件类型的数组。
否则,只要下列任何情况为真,则抛出 IndexOutOfBoundsException 异常,并且不会修改目标数组:
srcPos 参数为负。
destPos 参数为负。
length 参数为负。
srcPos+length 大于 src.length,即源数组的长度。
destPos+length 大于 dest.length,即目标数组的长度。
否则,如果源数组中 srcPos 到 srcPos+length-1 位置上的实际组件通过分配转换并不能转换成目标数组的组件类型,则抛出 ArrayStoreException 异常。在这种情况下,将 k 设置为比长度小的最小非负整数,这样就无法将 src[srcPos+k] 转换为目标数组的组件类型;当抛出异常时,从 srcPos 到 srcPos+k-1 位置上的源数组组件已经被复制到目标数组中的 destPos 到 destPos+k-1 位置,而目标数组中的其他位置不会被修改。(因为已经详细说明过的那些限制,只能将此段落有效地应用于两个数组都有引用类型的组件类型的情况。)
参数:
src - 源数组。
srcPos - 源数组中的起始位置。
dest - 目标数组。
destPos - 目标数据中的起始位置。
length - 要复制的数组元素的数量。
抛出:
IndexOutOfBoundsException - 如果复制会导致对数组范围以外的数据的访问。
ArrayStoreException - 如果因为类型不匹配而使得无法将 src 数组中的元素存储到 dest 数组中。
NullPointerException - 如果 src 或 dest 为 null。
我们的代码如下:
package cn.com.sxia;
import java.util.Arrays;
public class ArraysCopy {
public static void main(String[] args) {
/*基本数据类型*/
System.out.println("========================基本数据类型==========================");
int arr1[] = new int[5];
int arr2[] = new int[9];
//Arrays工具类的部分方法使用
Arrays.fill(arr1, 7);
System.out.println(Arrays.toString(arr1) + "arr1的长度是:" + arr1.length);
Arrays.fill(arr2, 9);
System.out.println(Arrays.toString(arr2) + "arr2的长度是:" + arr2.length);
//数组拷贝
System.arraycopy(arr1, 0, arr2, 0, arr1.length);
System.out.println("新的数组:" + Arrays.toString(arr2) + "arr2的长度是:" + arr2.length);
/*对象的操作*/
System.out.println("========================对象的操作==========================");
Integer[] arrObj1 = new Integer[5];
Integer[] arrObj2 = new Integer[9];
Arrays.fill(arrObj1, new Integer(7));
System.out.println(Arrays.toString(arrObj1) + "arrObj1的长度是:" + arrObj1.length);
Arrays.fill(arrObj2, new Integer(9));
System.out.println(Arrays.toString(arrObj2) + "arrObj2的长度是:" + arrObj2.length);
//数组拷贝
System.arraycopy(arrObj1, 0, arrObj2, 0, arrObj1.length);
System.out.println("新的数组:" + Arrays.toString(arrObj2) + "arrObj2的长度是:" + arrObj2.length);
}
}
运行结果如下:
========================基本数据类型==========================
[7, 7, 7, 7, 7]arr1的长度是:5
[9, 9, 9, 9, 9, 9, 9, 9, 9]arr2的长度是:9
新的数组:[7, 7, 7, 7, 7, 9, 9, 9, 9]arr2的长度是:9
========================对象的操作==========================
[7, 7, 7, 7, 7]arrObj1的长度是:5
[9, 9, 9, 9, 9, 9, 9, 9, 9]arrObj2的长度是:9
新的数组:[7, 7, 7, 7, 7, 9, 9, 9, 9]arrObj2的长度是:9
代码里我顺便演示了Arrays类的部分功能,使用数组经常因为数组大小一开始就固定好的缺点,我们不得不去重新拷贝数组,System.arraycopy方法提供了一个十分简便的方案,不过这个方法也是有问题的,从代码里我们可以认为System的arrayCopy方法什么样的数组都可以拷贝,但是对象数组的拷贝就有点不同,对象拷贝复制的是对象的引用而非对象的本身,这种拷贝叫做浅拷贝(shallow copy)。
方法的问题就是这个浅拷贝所造成,下面我就谈谈浅拷贝以及它对应的深拷贝。
浅拷贝和深拷贝的定义如下:
浅拷贝:比如A对象被复制到B对象,但是B对象只是复制了A对象本身,如果A对象里还有存在指向其他对象数组或者是引用,B对象内部不会复制这些内部的信息而是指向原来A对象引用的信息。
深拷贝:还是列举A对象被复制到B对象的例子,B对象拷贝到的是A对象的所有信息,包括A对象内部的对象引用。
可能看到上面的解释很多人还是不太清晰浅拷贝和深拷贝的区别,我下面用图形来展示它们的区别,首先是A对象,A里包含了两个内部对象innerA和innerB,如下图:
如果把A对象拷贝到B对象,但是B对象内部并没有拷贝innerA对象和innerB对象,B对象内部还是指向原来的innerA对象和innerB对象,如下图:
如果把A对象深拷贝到B对象,那么结果如下图:
A的内部对象也会拷贝到B对象内部。
上面的图形应该可以清晰的表达出浅拷贝和深拷贝的区别了吧。为什么会有浅拷贝和深拷贝了,到底是什么原因产生了浅拷贝和深拷贝了?昨天一个朋友用C语言的方式给我做了解答,哎,可惜C语言我只是在大学里学过,现在忘记的差不多了,但是我哪位朋友指出了浅拷贝和深拷贝是因为指针所产生的,产生的条件就是值的传递和返回,本质是数据在内存中存放的方式所造成。
下面我就要探求深浅拷贝的本质了,首先我又要说一个java语言里的真理:Java中所有参数传递都是按引用传递。
引用,引用还是引用,我前面讲了太多引用了啊。
今天写累了,我下一篇博文就从这个万恶的引用讲起。
重新研究编程语言是件很开心的事情,特别是在你已经做过一些项目以后你再看使用的语言的语法知识,你会有种豁然开朗的感觉:你知道那些知识很有用,那些知识比较难,更重要的是你知道你重新复习这些技术你今后能把他们用到什么样的地方,或许有人说这些都是基础,我们都做不少的项目了,何必再浪费时间,但你如果是对你所做的技术有更高的要求,你想进步而不是应付工作,学精一个东西一定会让你的成长不会很快碰到瓶颈了,不断学习和工作的人总会比懈怠的人收获的更多,这就是我的想法。
我们首先看看下面代码:
package cn.com.sxia;
public class RefObj {
public static void main(String[] args) {
String str1;//@1
String str2 = new String();//@2
System.out.println(str2.equals(""));
System.out.println(str1.equals(""));
}
}
代码是在定义字符串,我想所有学过编程语言的人都知道这是怎么回事,但是二者是有区别的:@1这里只是创建了字符串对象的引用,而实际的对象是没有被创建的,@2既创建了字符串对象的引用也创建了引用对应的对象(其实就是我们经常做的初始化操作),大家看到代码如果我们使用str2对象程序可以正常运行,但是如果我们同样去使用str1时候,程序会报编译错误,错误内容如下:
The local variable str1 may not have been initialized
那么在java里引用到底是怎么定义的呢?
引用(reference):能操作java对象的标示符被称为引用。
我们再看上面的例子,引用就是指str1和str2两个标示符,有人一定会奇怪:我们要的是对象,你说现在我们看到只是对象的标示符,那么对象到哪里去了啊?要回答这个问题就要说说对象和引用的关系了,他们的关系是:对象和引用的关系我们可以想象成遥控器(引用)和电视机(对象),用户通过掌握遥控器来控制对电视机的使用,我们要转移对电视机的操作权也就是转移遥控器的控制权而已。
这样的存储和操作对象的方式在编程语言里并不神秘,其实java里的方式还算比较简单的,总比C或者C++语言里的指针要简单许多。这里我也要强调下,有很多人认为java里的引用就是C里面的指针,但是很多经典的java的书籍里都否认这样的说法,我以前面试有人这么问过我,但是那时我就回答的是指针,虽然很多时候面试并没有否定,但也有人会刨根问底,最后搞的你不知道如何回答是好,其实java里的引用可以说成指针,但是这个指针是有限的指针,用户无法控制的指针,我想要是再碰到这样的问题我就说java里的引用就是被阉割的指针。
编程语言里变量的存储归结到计算机的底层都是内存的分配问题,知道java语言里数据在内存的分配方式,对我们编写程序一定会有帮助的,在java里有六种不同的存储方式:
寄存器:这是最快的保存区域,因为它位于和其他所有保存方式不同的地方:处理器内部。然而,寄存 器的数量十分有限,所以寄存器是根据需要由编译器分配。我们对此没有直接的控制权,也不可能在自己的 程序里找到寄存器存在的任何踪迹。
堆栈:驻留于常规 RAM (随机访问存储器)区域,但可通过它的“堆栈指针”获得处理的直接支持。堆 栈指针若向下移,会创建新的内存;若向上移,则会释放那些内存。这是一种特别快、特别有效的数据保存 方式,仅次于寄存器。创建程序时,Java 编译器必须准确地知道堆栈内保存的所有数据的“长度”以及“存 在时间”。这是由于它必须生成相应的代码,以便向上和向下移动指针。这一限制无疑影响了程序的灵活 性,所以尽管有些 Java 数据要保存在堆栈里——特别是对象句柄,但Java 对象并不放到其中。
堆:一种常规用途的内存池(也在 RAM 区域),其中保存了Java 对象。和堆栈不同,“内存堆”或 “堆”(Heap )最吸引人的地方在于编译器不必知道要从堆里分配多少存储空间,也不必知道存储的数据要 在堆里停留多长的时间。因此,用堆保存数据时会得到更大的灵活性。要求创建一个对象时,只需用new 命 令编制相关的代码即可。执行这些代码时,会在堆里自动进行数据的保存。当然,为达到这种灵活性,必然 会付出一定的代价:在堆里分配存储空间时会花掉更长的时间!
静态存储:这儿的“静态”(Static)是指“位于固定位置”(尽管也在RAM 里)。程序运行期间,静 态存储的数据将随时等候调用。可用 static 关键字指出一个对象的特定元素是静态的。但 Java 对象本身永 远都不会置入静态存储空间。
常数存储:常数值通常直接置于程序代码内部。这样做是安全的,因为它们永远都不会改变。有的常数 需要严格地保护,所以可考虑将它们置入只读存储器(ROM)。
非RAM 存储:若数据完全独立于一个程序之外,则程序不运行时仍可存在,并在程序的控制范围之外。 其中两个最主要的例子便是“流式对象”和“固定对象”。对于流式对象,对象会变成字节流,通常会发给 另一台机器。而对于固定对象,对象保存在磁盘中。即使程序中止运行,它们仍可保持自己的状态不变。对 于这些类型的数据存储,一个特别有用的技巧就是它们能存在于其他媒体中。一旦需要,甚至能将它们恢复 成普通的、基于RAM 的对象。
Java里基本类型和引用都是存放到堆栈里,因为它们所占的空间比较少,没有必要放到堆内存中去,而存在堆栈里使用起来会更高效。这里还要说的是数组,数组可以和对象等同,哪怕你在创建一个基本类型的数组也是如此,数组可以完全当做对象来使用。
现在我们可以回到我们在上篇要谈的内容:java里对象的传递和返回都是通过引用传递和返回的,这就是导致System.arraycopy方法是浅拷贝的症结了。下面的代码显示了java是按引用传递的:我们把一个引用传入到某个方法里,我们在方法内部发现传入的引用指向的还是原来的对象,大家看下面的代码:
package cn.com.sxia;
public class PassRef {
public static void f(PassRef h){
System.out.println("h inside f():" + h);
}
public static void main(String[] args) {
PassRef p = new PassRef();
System.out.println("p inside main():" + p);
f(p);
}
}
运行结果如下:
p inside main():cn.com.sxia.PassRef@119298d
h inside f():cn.com.sxia.PassRef@119298d
大家看到了p和h引用都是指向了同一个对象,因为他们的地址是一样的。
Java里还有一个别名效应的问题。
别名效应:是指多个引用指向同一个对象。这种情况就是一台电视机多台遥控器,突然一个遥控器换了台,其他的遥控器可能并不想换台,这就有问题了。
大家看下面的代码:
package cn.com.sxia;
public class Alias {
private int i;
public Alias(int ii){
i = ii;
}
public static void main(String[] args) {
Alias x = new Alias(7);
Alias y = x;
System.out.println("x: " + x.i);
System.out.println("y: " + y.i);
System.out.println("增加变量x里的i的数值:");
x.i++;
System.out.println("x: " + x.i);
System.out.println("y: " + y.i);
}
}
运行结果如下:
x: 7
y: 7
增加变量x里的i的数值:
x: 8
y: 8
大家可以看到x和y变量的值都被改变了。这种被串行修改的情况我们大多时候都不愿意发生。解决这个问题的方法很简单:不要在同一个作用域里生成多个对象的引用,特别是传值的时候,我们不要随意用局部变量存储传来的值。
但是在一个局部环境里(局部环境就是一个方法内的作用域),我们从外部传参数进来总会产生这样的问题。那么在一个局部环境也就是在一个方法内的作用域里,变量和对象到底是什么样的情况,很高兴有些人总结了这里面的情况:
当我们向方法里传递参数别名的效应就会发生。这个很好理解了,当传参数时候,局部环境外部有个引用和局部环境内部的参数的引用都是指向了同一个对象,多个引用指向同一个对象就是别名效应了。
在一个局部环境里,我们构建一个对象,这个对象有引用,引用是属于这个局部环境的,离开了局部环境引用就被销毁,但是创建的对象还会存在,特别是我们用了return关键字返回时候,外部会有另外一个引用使用到这个对象,所以局部环境内没有局部对象只有局部引用。
上面的问题还引出了一种情况:在局部环境里引用是有作用域的,但是对象是没有的,对象的销毁是在没有可以使用该对象的引用后在一定时间内被垃圾回收机制所回收。
在java里我们关心的是引用的生命周期,而不是对象的生命周期,对象的生命周期是java自己管理的。
引用传递虽然存在很多问题,但是引用传递是java默认的传递方式,因为大多数情况引用不会影响到我们程序的正确运行,而且传递参数只传递引用也就是只对堆栈的内存进行读取,效率会更高,因此有时我们也可以片面的理解引用是java为程序的高效性所做的妥协了。
下面我就写个浅拷贝的代码,我这个小系列里不会对如果写出正确拷贝问题作出深入的分析,因为我想着重学习的是java里复杂的数据存储方式,我只是由浅拷贝引出一个很重要的观点:java里传递的是引用这个真理,这个对我后面写复杂数据存储问题很有帮助。不过在我后面的内容中也会进一步阐释深拷贝和浅拷贝的问题,解决正确拷贝的问题会穿插到我后面文章的内容之中。好了,大家看下面的代码吧:
package cn.com.sxia;
import java.util.Arrays;
class Int{
private int i;
public Int(int j){
i = j;
}
public void increment(){
i++;
}
public String toString(){
return Integer.toString(i);
}
}
public class Cloning {
public static void main(String[] args) {
Int[] arr1 = new Int[10];
for (int i = 0;i < 10;i++){
arr1[i] = new Int(i);
}
System.out.println("arr1:" + Arrays.toString(arr1));
Int[] arr2 = arr1.clone();
for (int j = 0;j < arr2.length;j++){
arr2[j].increment();
}
System.out.println("arr1:" + Arrays.toString(arr1));
}
}
运行结果如下:
arr1:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
arr1:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
我们使用clone方法进行复制,arr1复制到了arr2,但是arr2的改变影响到了arr1的值,这就说明这个拷贝是浅拷贝,arr2只是复制了arr1的引用,而arr1指向的对象是没有被拷贝的。实际上java里的对象由以下几个部分所组成:对象的引用,引用所指向的对象,这些对象指向的另外一些对象,一直指向下去这就构成了一个对象网络图,深拷贝就是将这整个对象网路图全拷贝下来。
下面的内容我就开始讲解多java.util包的使用了。这个是我要讲的重点了。