1 map-reduce 简介
a) 是一个基础框架模型,后面学的框架都是对这个框架的包装,类比于 jdbc <----> mybatis/hibernate.
b) 是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.
c) MR由两个阶段组成:Map和Reduce,只需要实现map()和reduce()两个函数,即可实现分布式计算
d) 这两个函数的形参是key、value对,表示函数的输入信息。
核心在于<k1,v1> ---> <k2,v2> ---> <k3,v3> 的转变
2 map-reduce 执行过程
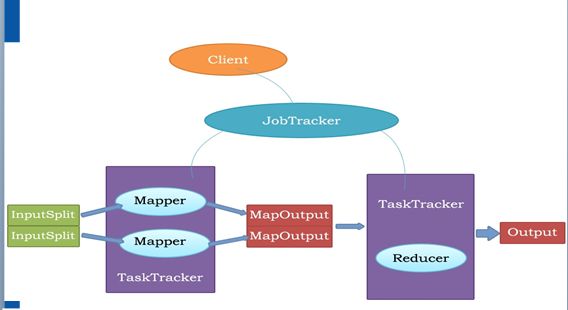
2.0 对上图解释补充如下:
a) Reducer不一定只执行在一个TaskTracker上,举例如下:
统计销售部门1,2,3 在2012,2013,2014年每个部门的绩效,
那么假如在TaskTracker1上执行map得到部门1,2,3 2012年的绩效
在TaskTracker2上执行map得到部门1,2,3 2013年的绩效
在TaskTracker3上执行map得到部门1,2,3 2014年的绩效
而reduce只针对某个部门执行所有年汇总,那么此时就要开启三个reduce,分别在三台TaskTracker上执行
b) Reducer放在哪个TaskTracker或者哪些个TaskTracker上执行是由JobTracker决定的
c) hdfs ----> 将数据传递给map ----> reduce ----> 将汇总结果写到hdfs,具体写在哪个datanode节点是由hdfs决定的。
d) map的输出是放在Linux磁盘上的, reduce获取的是每个map任务产生的数据,比如这个reduce是处理销售部门1的,那么就会专门获取销售部门1在所有map中产生的数据,而每个map任务仅仅是处理一部分数据,
map和reduce之间数据传递的过程叫做shuffle,shuffle属于reduce的第一阶段
e) reduce阶段是主动通过HTTP协议来获取map阶段产生的中间值,默认配置的路径可在mapred-default.xml/136行(<value>${hadoop.tmp.dir}/mapred/staging</value>运行时产生临时数据,运行完删除)
在执行map任务结束后,会通知jobtracker,然后jobtracker会决定在哪个/哪些个 tasktracker上启动reduce,
然后reduce会根据jobtracker记录的地址去Linux磁盘中获取map产生的中间值。
f) 要存储的数据被划分为100个block 可以简单理解为会启动100个map
map在输出的时候,会确定分成多少个区,如果分成3个区,那么就会对应三个reduce任务,即reduce的数量
是由map的分区决定的。
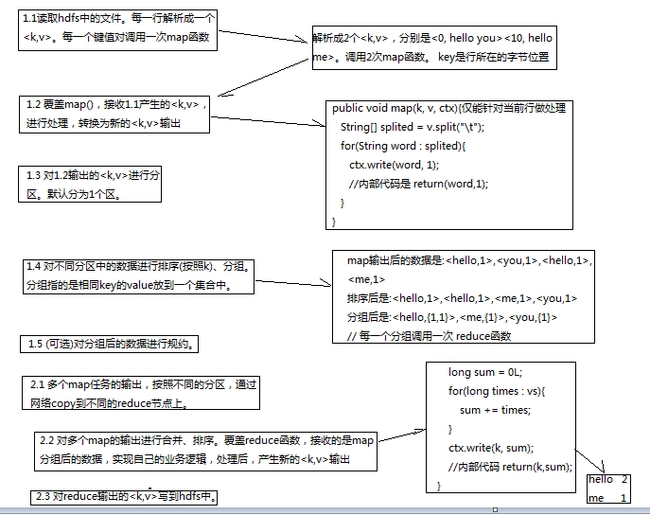
mapper: 5步
reduce: 3步
1. map任务处理
a) 读取输入文件内容(从hdfs中读取 类比于文件类型有红豆 黄豆等类型),
解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数
map仅能处理一行数据。map中分组的作用就是让不同行的数据有见面的机会,从而为reduce的合并做准备(联想单词计数案例)
这个key是当前文本行的字节首地址, value是当前行的内容
b) 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
c) 对输出的key、value进行分区(将不同类型的豆放在一起)。
d) 对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中(分组仅仅是将map处理的中间结果具有相同key的value见面的机会,并不是作为减少网络开销的目的,其实也达不到减少网络开销的效果)
e) (可选)分组后的数据进行归约。
2 reduce
a) 对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
b) 对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出, 得到最终结果 <k3,v3>
c) 把reduce的输出保存到文件中
下面贴出 wordcount的代码:
package mapreduce;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* 实现单词计数功能
* 测试文件 hello内容为:
* hello you
* hello me
* @author zm
*
*/
public class MyWordCount {
static String FILE_ROOT = "hdfs://master:9000/";
static String FILE_INPUT = "hdfs://master:9000/hello";
static String FILE_OUTPUT = "hdfs://master:9000/out";
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI(FILE_ROOT),conf);
Path outpath = new Path(FILE_OUTPUT);
if(fileSystem.exists(outpath)){
fileSystem.delete(outpath, true);
}
// 0 定义干活的人
Job job = new Job(conf);
// 1.1 告诉干活的人 输入流位置 读取hdfs中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数
FileInputFormat.setInputPaths(job, FILE_INPUT);
// 指定如何对输入文件进行格式化,把输入文件每一行解析成键值对
job.setInputFormatClass(TextInputFormat.class);
//1.2 指定自定义的map类
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//1.3 分区
job.setNumReduceTasks(1);
//1.4 TODO 排序、分组 目前按照默认方式执行
//1.5 TODO 规约
//2.2 指定自定义reduce类
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//2.3 指定写出到哪里
FileOutputFormat.setOutputPath(job, outpath);
job.setOutputFormatClass(TextOutputFormat.class);
// 让干活的人干活
job.waitForCompletion(true);
}
}
/**
* 继承mapper 覆盖map方法,hadoop有自己的参数类型
* 读取hdfs中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数,
* 这样,对于文件hello而言,调用MyMapper方法map后得到结果:
* <hello,1>,<you,1>,<hello,1>,<me,1>
* 方法后,得到结果为:
* KEYIN, 行偏移量
* VALUEIN, 行文本内容(当前行)
* KEYOUT, 行中出现的单词
* VALUEOUT 行中出现单词次数,这里固定写为1
*
*/
class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
String[] v1s = v1.toString().split(" ");
for(String word : v1s){
context.write(new Text(word), new LongWritable(1));
}
}
}
/**
* <hello,{1,1}>,<me,{1}>,<you,{1}>, 每个分组调用一次 reduce方法
*
* KEYIN, 行中出现单词
* VALUEIN, 行中出现单词个数
* KEYOUT, 文件中出现不同单词
* VALUEOUT 文件中出现不同单词总个数
*/
class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context ctx)
throws IOException, InterruptedException {
long times = 0L;
for(LongWritable l : v2s){
times += l.get();
}
ctx.write(k2, new LongWritable(times));
}
}
结果如下:
[root@master ~]# hadoop fs -text /out/part-r-00000 Warning: $HADOOP_HOME is deprecated. hello 2 me 3 you 1 测试文件内容: hello you hello me me me
输出结果如下: [root@master hadoop]# hadoop fs -lsr /out Warning: $HADOOP_HOME is deprecated. -rw-r--r-- 3 zm supergroup 0 2014-11-27 00:59 /out/_SUCCESS -rw-r--r-- 3 zm supergroup 26 2014-11-27 00:59 /out/part-r-00000 在linux中, _开头的文件常表示忽略不被处理的文件, part-r-00000 中的 r表示reduce输出的结果,如果是map输出结果则为m,00000表示序号
执行流程如下:
上述流程中,job.waitForCompletion(true);是将任务提交给hadoop的jobtacker,然后剩下工作交给hadoop执行,那么任务是如何提交给jobtracker的呢:
1 如何连接到配置文件指定的jobtracker机器连接
找到waitForCompletion()--->submit();--->connect();--->JobClient---> init(conf);---> createRPCProxy--->
(JobSubmissionProtocol)RPC.getProxy--->JobSubmissionProtocol:Protocol that a JobClient and the central JobTracker use to communicate.
这样就和 执行任务的JobTracker连接上,如上流程是获取真实配置的jobtracker连接
2 如何将任务提交到指定的Jobtracker机器:
submit()--->jobClient.submitJobInternal(conf); ---> jobSubmitClient.submitJob(...)---> 客户端通过代理调用的是JobTracker服务端的submitJob方法--->然后
可以去JobTracker.submitJob(...)看任务执行流程
上述流程部分代码贴出如下:
private void connect() throws IOException, InterruptedException {
ugi.doAs(new PrivilegedExceptionAction<Object>() {
public Object run() throws IOException {
jobClient = new JobClient((JobConf) getConfiguration());
return null;
}
});
}
看init():
public void init(JobConf conf) throws IOException {
String tracker = conf.get("mapred.job.tracker", "local"); // 从配置文件中获取Key为mapred.job.tracker对应的数据,若没有则用local替代
tasklogtimeout = conf.getInt( //mapred.job.tracker属性在配置Hadoop mapred-site.xml时必须填写,因此下面的local分支不会执行
TASKLOG_PULL_TIMEOUT_KEY, DEFAULT_TASKLOG_TIMEOUT);
this.ugi = UserGroupInformation.getCurrentUser();
if ("local".equals(tracker)) {
conf.setNumMapTasks(1);
this.jobSubmitClient = new LocalJobRunner(conf);
} else {
this.rpcJobSubmitClient =
createRPCProxy(JobTracker.getAddress(conf), conf); // 通过rpc获取 jobtrack连接
this.jobSubmitClient = createProxy(this.rpcJobSubmitClient, conf);
}
}
看submit():
public void submit() throws IOException, InterruptedException,
ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
// Connect to the JobTracker and submit the job
connect(); // 获取配置文件中配置好的jobtracker机器地址 eg: >master:9001
info = jobClient.submitJobInternal(conf); // 提交到jobtracker机器
super.setJobID(info.getID());
state = JobState.RUNNING;
}
总结下如下:
(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法
connect();
info = jobClient.submitJobInternal(conf);
(2)在connect()方法中,实际上创建了一个JobClient对象。
在调用该对象的构造方法时,获得了JobTracker的客户端代理对象JobSubmissionProtocol。
JobSubmissionProtocol的实现类是JobTracker。
(3)在jobClient.submitJobInternal(conf)方法中,调用了
JobSubmissionProtocol.submitJob(...),
即执行的是JobTracker.submitJob(...)。