Lucene学习总结之七:Lucene搜索过程解析(7)
2.4、搜索查询对象
2.4.3.2、并集DisjunctionSumScorer(A OR B)
DisjunctionSumScorer中有成员变量List<Scorer> subScorers,是一个Scorer的链表,每一项代表一个倒排表,DisjunctionSumScorer就是对这些倒排表取并集,然后将并集中的文档号在nextDoc()函数中依次返回。
DisjunctionSumScorer还有一个成员变量minimumNrMatchers,表示最少需满足的子条件的个数,也即subScorer中,必须有至少minimumNrMatchers个Scorer都包含某个文档号,此文档号才能够返回。
为了描述清楚此过程,下面举一个具体的例子来解释倒排表合并的过程:
(1) 假设minimumNrMatchers = 4,倒排表最初如下:

(2) 在DisjunctionSumScorer的构造函数中,将倒排表放入一个优先级队列scorerDocQueue中(scorerDocQueue的实现是一个最小堆),队列中的Scorer按照第一篇文档的大小排序。
| private void initScorerDocQueue() throws IOException { scorerDocQueue = new ScorerDocQueue(nrScorers); for (Scorer se : subScorers) { if (se.nextDoc() != NO_MORE_DOCS) { //此处的nextDoc使得每个Scorer得到第一篇文档号。 scorerDocQueue.insert(se); } } } |

(3) 当BooleanScorer2.score(Collector)中第一次调用nextDoc()的时候,advanceAfterCurrent被调用。
| public int nextDoc() throws IOException { if (scorerDocQueue.size() < minimumNrMatchers || !advanceAfterCurrent()) { currentDoc = NO_MORE_DOCS; } return currentDoc; } |
| protected boolean advanceAfterCurrent() throws IOException { do { currentDoc = scorerDocQueue.topDoc(); //当前的文档号为最顶层 currentScore = scorerDocQueue.topScore(); //当前文档的打分 nrMatchers = 1; //当前文档满足的子条件的个数,也即包含当前文档号的Scorer的个数 do { //所谓topNextAndAdjustElsePop是指,最顶层(top)的Scorer取下一篇文档(Next),如果能够取到,则最小堆的堆顶可能不再是最小值了,需要调整(Adjust,其实是downHeap()),如果不能够取到,则最顶层的Scorer已经为空,则弹出队列(Pop)。 if (!scorerDocQueue.topNextAndAdjustElsePop()) { if (scorerDocQueue.size() == 0) { break; // nothing more to advance, check for last match. } } //当最顶层的Scorer取到下一篇文档,并且调整完毕后,再取出此时最上层的Scorer的第一篇文档,如果不是currentDoc,说明currentDoc此文档号已经统计完毕nrMatchers,则退出内层循环。 if (scorerDocQueue.topDoc() != currentDoc) { break; // All remaining subscorers are after currentDoc. } //否则nrMatchers加一,也即又多了一个Scorer也包含此文档号。 currentScore += scorerDocQueue.topScore(); nrMatchers++; } while (true); //如果统计出的nrMatchers大于最少需满足的子条件的个数,则此currentDoc就是满足条件的文档,则返回true,在收集文档的过程中,DisjunctionSumScorer.docID()会被调用,返回currentDoc。 if (nrMatchers >= minimumNrMatchers) { return true; } else if (scorerDocQueue.size() < minimumNrMatchers) { return false; } } while (true); } |
advanceAfterCurrent具体过程如下:
- 最初,currentDoc=2,文档2的nrMatchers=1
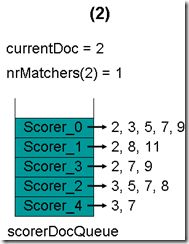
- 最顶层的Scorer 0取得下一篇文档,为文档3,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 1的第一篇文档号,都为2,文档2的nrMatchers为2。

- 最顶层的Scorer 1取得下一篇文档,为文档8,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 3的第一篇文档号,都为2,文档2的nrMatchers为3。

- 最顶层的Scorer 3取得下一篇文档,为文档7,重新调整最小堆后如下图。此时currentDoc还为2,不等于最顶层Scorer 2的第一篇文档3,于是退出内循环。此时检查,发现文档2的nrMatchers为3,小于minimumNrMatchers,不满足条件。于是currentDoc设为最顶层Scorer 2的第一篇文档3,nrMatchers设为1,重新进入下一轮循环。

- 最顶层的Scorer 2取得下一篇文档,为文档5,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 4的第一篇文档号,都为3,文档3的nrMatchers为2。
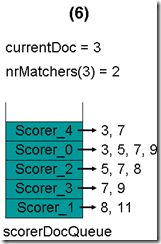
- 最顶层的Scorer 4取得下一篇文档,为文档7,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 0的第一篇文档号,都为3,文档3的nrMatchers为3。

- 最顶层的Scorer 0取得下一篇文档,为文档5,重新调整最小堆后如下图。此时currentDoc还为3,不等于最顶层Scorer 0的第一篇文档5,于是退出内循环。此时检查,发现文档3的nrMatchers为3,小于minimumNrMatchers,不满足条件。于是currentDoc设为最顶层Scorer 0的第一篇文档5,nrMatchers设为1,重新进入下一轮循环。
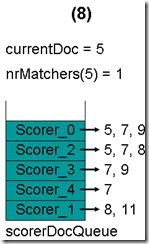
- 最顶层的Scorer 0取得下一篇文档,为文档7,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 2的第一篇文档号,都为5,文档5的nrMatchers为2。
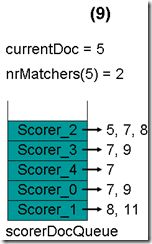
- 最顶层的Scorer 2取得下一篇文档,为文档7,重新调整最小堆后如下图。此时currentDoc还为5,不等于最顶层Scorer 2的第一篇文档7,于是退出内循环。此时检查,发现文档5的nrMatchers为2,小于minimumNrMatchers,不满足条件。于是currentDoc设为最顶层Scorer 2的第一篇文档7,nrMatchers设为1,重新进入下一轮循环。
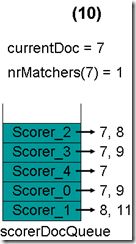
- 最顶层的Scorer 2取得下一篇文档,为文档8,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 3的第一篇文档号,都为7,文档7的nrMatchers为2。
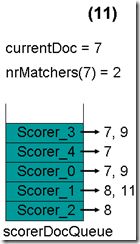
- 最顶层的Scorer 3取得下一篇文档,为文档9,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 4的第一篇文档号,都为7,文档7的nrMatchers为3。
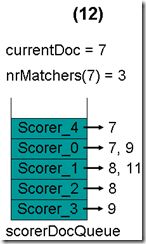
- 最顶层的Scorer 4取得下一篇文档,结果为空,Scorer 4所有的文档遍历完毕,弹出队列,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 0的第一篇文档号,都为7,文档7的nrMatchers为4。
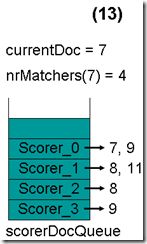
- 最顶层的Scorer 0取得下一篇文档,为文档9,重新调整最小堆后如下图。此时currentDoc还为7,不等于最顶层Scorer 1的第一篇文档8,于是退出内循环。此时检查,发现文档7的nrMatchers为4,大于等于minimumNrMatchers,满足条件,返回true,退出外循环。
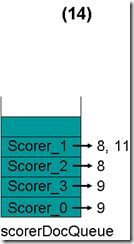
(4) currentDoc设为7,在收集文档的过程中,DisjunctionSumScorer.docID()会被调用,返回currentDoc,也即当前的文档号为7。
(5) 当再次调用nextDoc()的时候,文档8, 9, 11都不满足要求,最后返回NO_MORE_DOCS,倒排表合并结束。
2.4.3.3、差集ReqExclScorer(+A -B)
ReqExclScorer有成员变量Scorer reqScorer表示必须满足的部分(required),成员变量DocIdSetIterator exclDisi表示必须不能满足的部分,ReqExclScorer就是返回reqScorer和exclDisi的倒排表的差集,也即在reqScorer的倒排表中排除exclDisi中的文档号。
当nextDoc()调用的时候,首先取得reqScorer的第一个文档号,然后toNonExcluded()函数则判断此文档号是否被exclDisi排除掉,如果没有,则返回此文档号,如果排除掉,则取下一个文档号,看是否被排除掉,依次类推,直到找到一个文档号,或者返回NO_MORE_DOCS。
| public int nextDoc() throws IOException { if (reqScorer == null) { return doc; } doc = reqScorer.nextDoc(); if (doc == NO_MORE_DOCS) { reqScorer = null; return doc; } if (exclDisi == null) { return doc; } return doc = toNonExcluded(); } |
| private int toNonExcluded() throws IOException { //取得被排除的文档号 int exclDoc = exclDisi.docID(); //取得当前required文档号 int reqDoc = reqScorer.docID(); do { //如果required文档号小于被排除的文档号,由于倒排表是按照从小到大的顺序排列的,因而此required文档号不会被排除,返回。 if (reqDoc < exclDoc) { return reqDoc; } else if (reqDoc > exclDoc) { //如果required文档号大于被排除的文档号,则此required文档号有可能被排除。于是exclDisi移动到大于或者等于required文档号的文档。 exclDoc = exclDisi.advance(reqDoc); //如果被排除的倒排表遍历结束,则required文档号不会被排除,返回。 if (exclDoc == NO_MORE_DOCS) { exclDisi = null; return reqDoc; } //如果exclDisi移动后,大于required文档号,则required文档号不会被排除,返回。 if (exclDoc > reqDoc) { return reqDoc; // not excluded } } //如果required文档号等于被排除的文档号,则被排除,取下一个required文档号。 } while ((reqDoc = reqScorer.nextDoc()) != NO_MORE_DOCS); reqScorer = null; return NO_MORE_DOCS; } |
2.4.3.4、ReqOptSumScorer(+A B)
ReqOptSumScorer包含两个成员变量,Scorer reqScorer代表必须(required)满足的文档倒排表,Scorer optScorer代表可以(optional)满足的文档倒排表。
如代码显示,在nextDoc()中,返回的就是required的文档倒排表,只不过在计算score的时候打分更高。
| public int nextDoc() throws IOException { return reqScorer.nextDoc(); } |
2.4.3.5、有关BooleanScorer及scoresDocsOutOfOrder
在BooleanWeight.scorer生成Scorer树的时候,除了生成上述的BooleanScorer2外, 还会生成BooleanScorer,是在以下的条件下:
- !scoreDocsInOrder:根据2.4.2节的步骤(c),scoreDocsInOrder = !collector.acceptsDocsOutOfOrder(),此值是在search中调用TopScoreDocCollector.create(nDocs, !weight.scoresDocsOutOfOrder())的时候设定的,scoreDocsInOrder = !weight.scoresDocsOutOfOrder(),其代码如下:
| public boolean scoresDocsOutOfOrder() { int numProhibited = 0; for (BooleanClause c : clauses) { if (c.isRequired()) { return false; } else if (c.isProhibited()) { ++numProhibited; } } if (numProhibited > 32) { return false; } return true; } |
- topScorer:根据2.4.2节的步骤(c),此值为true。
- required.size() == 0,没有必须满足的子语句。
- prohibited.size() < 32,不需不能满足的子语句小于32。
从上面可以看出,最后两个条件和scoresDocsOutOfOrder函数中的逻辑是一致的。
下面我们看看BooleanScorer如何合并倒排表的:
|
public int nextDoc() throws IOException { boolean more; do { //bucketTable等于是存放合并后的倒排表的文档队列 while (bucketTable.first != null) { //从队列中取出第一篇文档,返回 current = bucketTable.first; bucketTable.first = current.next; if ((current.bits & prohibitedMask) == 0 && (current.bits & requiredMask) == requiredMask && current.coord >= minNrShouldMatch) { return doc = current.doc; } } //如果队列为空,则填充队列。 more = false; end += BucketTable.SIZE; //按照Scorer的顺序,依次用Scorer中的倒排表填充队列,填满为止。 for (SubScorer sub = scorers; sub != null; sub = sub.next) { Scorer scorer = sub.scorer; sub.collector.setScorer(scorer); int doc = scorer.docID(); while (doc < end) { sub.collector.collect(doc); doc = scorer.nextDoc(); } more |= (doc != NO_MORE_DOCS); } } while (bucketTable.first != null || more); return doc = NO_MORE_DOCS; } |
|
public final void collect(final int doc) throws IOException { final BucketTable table = bucketTable; final int i = doc & BucketTable.MASK; Bucket bucket = table.buckets[i]; if (bucket == null) table.buckets[i] = bucket = new Bucket(); if (bucket.doc != doc) { bucket.doc = doc; bucket.score = scorer.score(); bucket.bits = mask; bucket.coord = 1; bucket.next = table.first; table.first = bucket; } else { bucket.score += scorer.score(); bucket.bits |= mask; bucket.coord++; } } |
从上面的实现我们可以看出,BooleanScorer合并倒排表的时候,并不是按照文档号从小到大的顺序排列的。
从原理上我们可以理解,在AND的查询条件下,倒排表的合并按照算法需要按照文档号从小到大的顺序排列。然而在没有AND的查询条件下,如果都是OR,则文档号是否按照顺序返回就不重要了,因而scoreDocsInOrder就是false。
因而上面的DisjunctionSumScorer,其实"apple boy dog"是不能产生DisjunctionSumScorer的,而仅有在有AND的查询条件下,才产生DisjunctionSumScorer。
我们做实验如下:
对于查询语句"apple boy dog",生成的Scorer如下:
| scorer BooleanScorer (id=34) |
对于查询语句"+hello (apple boy dog)",生成的Scorer对象如下:
| scorer BooleanScorer2 (id=40) //weight(contents:apple) //weight(contents:boy) //weight(contents:cat) |