运行Nutch的时候提示Generator: 0 records selected for fetching, exiting ...然后程序退出,怎么回事呢?
原因多种多样,归根结底就是CrawlDB中的URL经过爬虫抓取调度器(默认是org.apache.nutch.crawl.DefaultFetchSchedule)判断,断定都不应该去抓,所以,Stop The World。
我们使用命令如下命令来查看CrawlDB的统计信息:
bin/nutch readdb data/crawldb -stats
结果如下:
CrawlDb statistics start: data/crawldb Statistics for CrawlDb: data/crawldb TOTAL urls: 347457 retry 0: 346506 retry 1: 951 min score: 0.0 avg score: 6.605134E-6 max score: 1.0 status 1 (db_unfetched): 951 status 2 (db_fetched): 337818 status 3 (db_gone): 3637 status 4 (db_redir_temp): 5006 status 5 (db_redir_perm): 45 CrawlDb statistics: done
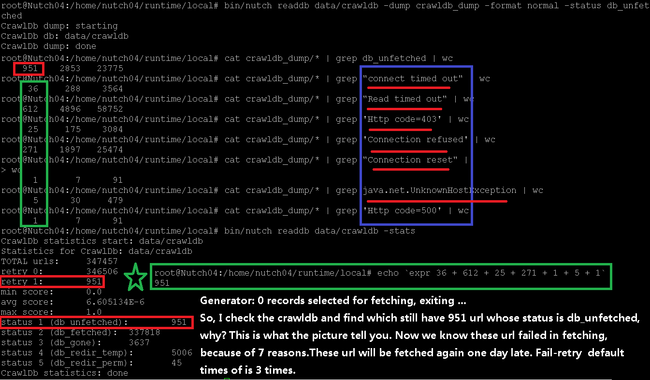
我们发现db_unfetched状态的URL还有951个,怎么不抓了呀?呵呵,别急,继续看,发现retry 1的URL也有951个,retry 1是什么东东呢?就是抓取失败了,等待1天(默认)后再次去抓的URL,哦,现在明白了吧,这些db_unfetched状态的URL其实都已经抓过了,不过都抓取失败了,因为只有抓取成功的URL的状态才会变为非db_unfetched的其他状态。
弄明白了为什么爬虫退出的原因之后,还有疑问吗?对这些抓取失败的URL是什么原因导致的失败不感兴趣吗?
我们把CrawlDB中db_unfetched状态的URL导出为文本文件,看看到底是些什么URL,失败的原因都是些什么,用如下命令:
bin/nutch readdb data/crawldb -dump crawldb_dump -format normal -status
命令执行完毕我们就可以看这个导出的文本文件里面的内容了,文件位于当前路径下crawldb_dump/part-00000。
我们要确认一下导出的文本文件的db_unfetched状态的URL的数目是否为951,用如下命令:
cat crawldb_dump/* | grep db_unfetched | wc
结果如下:
951 2853 23775
数目没问题。然后使用如下命令找到抓取失败的信息:
cat crawldb_dump/* | grep exception | wc
结果如下:
951 7300 91535
数目也是951,这就说明了状态为db_unfetched的951条URL都抓过了,不幸的是都失败了。
接着我们要从这951条失败信息中提取出抓取失败的类型,使用如下命令去除重复的失败信息:
cat crawldb_dump/* | grep exception | sort | uniq | wc
结果如下:
35 242 4034
去重之后只剩下35条了,太好了,人眼可以识别了呀,呵呵,我们进一步去除以:隔开的前三个字段,这3个字段每条数据都相同,使用以下命令:
cat crawldb_dump/* | grep exception | sort | uniq | awk -F ":" '{print $4 $5}' | uniq | more
结果如下:
Http code=403, url=http//bgt.mof.gov.cn/mofhome/mof/1557/ Http code=403, url=http//bgt.mof.gov.cn/mofhome/mof/zhengwuxinxi/tianbanli/2006tabl/rdjydf/ Http code=403, url=http//bgt.mof.gov.cn/mofhome/mof/zhengwuxinxi/tianbanli/2006tabl/zs/ Http code=403, url=http//bgt.mof.gov.cn/mofhome/mof/zhengwuxinxi/tianbanli/2006tabl/zxtadf/ Http code=403, url=http//bgt.mof.gov.cn/mofhome/mof/zhuantihuigu/czgg0000_1/spjl/ Http code=403, url=http//gjs.mof.gov.cn/mofhome/mof/1557/ Http code=403, url=http//gjs.mof.gov.cn/mofhome/mof/zhengwuxinxi/tianbanli/2006tabl/rdjydf/ Http code=403, url=http//gjs.mof.gov.cn/mofhome/mof/zhengwuxinxi/tianbanli/2006tabl/zs/ Http code=403, url=http//gjs.mof.gov.cn/mofhome/mof/zhengwuxinxi/tianbanli/2006tabl/zxtadf/ Http code=403, url=http//gjs.mof.gov.cn/mofhome/mof/zhuantihuigu/czgg0000_1/spjl/ Http code=403, url=http//gjs.mof.gov.cn/pindaoliebiao/dhjz/qqhzjz/20Ghy/czyhhzhy/5156/ Http code=403, url=http//gjs.mof.gov.cn/pindaoliebiao/zcyd/dhjz/20Ghy/czyhhzhy/5156/ Http code=403, url=http//kjhx.mof.gov.cn/gongzhongcanyu/ Http code=403, url=http//sn.mof.gov.cn/lanmudaohang/zixz/ Http code=403, url=http//wjb.mof.gov.cn/pindaoliebiao/ Http code=403, url=http//www.mof.gov.cn/1557/ Http code=403, url=http//www.mof.gov.cn/zhengwuxinxi/tianbanli/2006tabl/rdjydf/ Http code=403, url=http//www.mof.gov.cn/zhengwuxinxi/tianbanli/2006tabl/zs/ Http code=403, url=http//www.mof.gov.cn/zhengwuxinxi/tianbanli/2006tabl/zxtadf/ Http code=403, url=http//www.mof.gov.cn/zhuantihuigu/czgg0000_1/spjl/ Http code=403, url=http//xxzx.mof.gov.cn/zaixianfuwuxxzx/ Http code=403, url=http//xxzx.mof.gov.cn/zhuantilanmuxxzx/ Http code=403, url=http//zcpg.mof.gov.cn/skzd/skjs/ Http code=403, url=http//zcpg.mof.gov.cn/zywk/pgll/ Http code=403, url=http//zhs.mof.gov.cn/zhuantilanmu/ Http code=500, url=http//zcgl.mof.gov.cn/ java.net.ConnectException Connection refused java.net.SocketException Connection reset java.net.SocketTimeoutException connect timed out java.net.SocketTimeoutException Read timed out java.net.UnknownHostException czxh.mof.gov.cn java.net.UnknownHostException docsvr.mof.gov.cn java.net.UnknownHostException shdk.mof.gov.cn java.net.UnknownHostException www.hn.mof.gov.cn java.net.UnknownHostException ysyj.mof.gov.cn
经过人工分析(自动分析不奏效了)发现了7种不同类型的抓取错误(注意:你的系统中跟我的可能不同):
Http code=403 Http code=500 Connection refused Connection reset connect timed out Read timed out java.net.UnknownHostException
分别使用这7种不同的抓取错误类型重新从导出的文件中进行统计,结果仍然是951。
cat crawldb_dump/* | grep "connect timed out" | wc cat crawldb_dump/* | grep "Read timed out" | wc cat crawldb_dump/* | grep 'Http code=403' | wc cat crawldb_dump/* | grep 'Connection refused' | wc cat crawldb_dump/* | grep "Connection reset" | wc cat crawldb_dump/* | grep java.net.UnknownHostException | wc cat crawldb_dump/* | grep 'Http code=500' | wc
好了,分析完毕,贴一张更直观完整的图来结束文章: