trie树
Trie 树 及Java实现
来源于英文“retrieval”. Trie树就是字符树,其核心思想就是空间换时间。
举个简单的例子。
给你100000个长度不超过10的单词。对于每一个单词,我们要判断他出没出现过,如果出现了,第一次出现第几个位置。
这题当然可以用hash来,但是我要介绍的是trie树。在某些方面它的用途更大。比如说对于某一个单词,我要询问它的前缀是否出现过。这样hash就不好搞了,而用trie还是很简单。
现在回到例子中,如果我们用最傻的方法,对于每一个单词,我们都要去查找它前面的单词中是否有它。那么这个算法的复杂度就是O(n^2)。显然对于100000的范围难以接受。现在我们换个思路想。假设我要查询的单词是abcd,那么在他前面的单词中,以b,c,d,f之类开头的我显然不必考虑。而只要找以a开头的中是否存在abcd就可以了。同样的,在以a开头中的单词中,我们只要考虑以b作为第二个字母的……这样一个树的模型就渐渐清晰了……
假设有b,abc,abd,bcd,abcd,efg,hii这6个单词,我们构建的树就是这样的。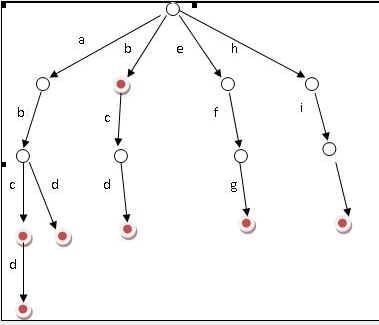
对于每一个节点,从根遍历到他的过程就是一个单词,如果这个节点被标记为红色,就表示这个单词存在,否则不存在。
那么,对于一个单词,我只要顺着他从根走到对应的节点,再看这个节点是否被标记为红色就可以知道它是否出现过了。把这个节点标记为红色,就相当于插入了这个单词。
我们可以看到,trie树每一层的节点数是26^i级别的。所以为了节省空间。我们用动态链表,或者用数组来模拟动态。空间的花费,不会超过单词数×单词长度。(转自一大牛)
Trie树的java代码 实现如下:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/** *//**
* A word trie which can only deal with 26 alphabeta letters.
* @author Leeclipse
* @since 2007-11-21
*/
public class Trie{
private Vertex root;//一个Trie树有一个根节点
//内部类
protected class Vertex{//节点类
protected int words;
protected int prefixes;
protected Vertex[] edges;//每个节点包含26个子节点(类型为自身)
Vertex() {
words = 0;
prefixes = 0;
edges = new Vertex[26];
for (int i = 0; i < edges.length; i++) {
edges[i] = null;
}
}
}
public Trie () {
root = new Vertex();
}
/** *//**
* List all words in the Trie.
*
* @return
*/
public List< String> listAllWords() {
List< String> words = new ArrayList< String>();
Vertex[] edges = root.edges;
for (int i = 0; i < edges.length; i++) {
if (edges[i] != null) {
String word = "" + (char)('a' + i);
depthFirstSearchWords(words, edges[i], word);
}
}
return words;
}
/** *//**
* Depth First Search words in the Trie and add them to the List.
*
* @param words
* @param vertex
* @param wordSegment
*/
private void depthFirstSearchWords(List words, Vertex vertex, String wordSegment) {
Vertex[] edges = vertex.edges;
boolean hasChildren = false;
for (int i = 0; i < edges.length; i++) {
if (edges[i] != null) {
hasChildren = true;
String newWord = wordSegment + (char)('a' + i);
depthFirstSearchWords(words, edges[i], newWord);
}
}
if (!hasChildren) {
words.add(wordSegment);
}
}
public int countPrefixes(String prefix) {
return countPrefixes(root, prefix);
}
private int countPrefixes(Vertex vertex, String prefixSegment) {
if (prefixSegment.length() == 0) { //reach the last character of the word
return vertex.prefixes;
}
char c = prefixSegment.charAt(0);
int index = c - 'a';
if (vertex.edges[index] == null) { // the word does NOT exist
return 0;
} else {
return countPrefixes(vertex.edges[index], prefixSegment.substring(1));
}
}
public int countWords(String word) {
return countWords(root, word);
}
private int countWords(Vertex vertex, String wordSegment) {
if (wordSegment.length() == 0) { //reach the last character of the word
return vertex.words;
}
char c = wordSegment.charAt(0);
int index = c - 'a';
if (vertex.edges[index] == null) { // the word does NOT exist
return 0;
} else {
return countWords(vertex.edges[index], wordSegment.substring(1));
}
}
/** *//**
* Add a word to the Trie.
*
* @param word The word to be added.
*/
public void addWord(String word) {
addWord(root, word);
}
/** *//**
* Add the word from the specified vertex.
* @param vertex The specified vertex.
* @param word The word to be added.
*/
private void addWord(Vertex vertex, String word) {
if (word.length() == 0) { //if all characters of the word has been added
vertex.words ++;
} else {
vertex.prefixes ++;
char c = word.charAt(0);
c = Character.toLowerCase(c);
int index = c - 'a';
if (vertex.edges[index] == null) { //if the edge does NOT exist
vertex.edges[index] = new Vertex();
}
addWord(vertex.edges[index], word.substring(1)); //go the the next character
}
}
public static void main(String args[]) //Just used for test
{
Trie trie = new Trie();
trie.addWord("China");
trie.addWord("China");
trie.addWord("China");
trie.addWord("crawl");
trie.addWord("crime");
trie.addWord("ban");
trie.addWord("China");
trie.addWord("english");
trie.addWord("establish");
trie.addWord("eat");
System.out.println(trie.root.prefixes);
System.out.println(trie.root.words);
List< String> list = trie.listAllWords();
Iterator listiterator = list.listIterator();
while(listiterator.hasNext())
{
String s = (String)listiterator.next();
System.out.println(s);
}
int count = trie.countPrefixes("ch");
int count1=trie.countWords("china");
System.out.println("the count of c prefixes:"+count);
System.out.println("the count of china countWords:"+count1);
}
}
运行:
C:\test>java Trie
10
0
ban
china
crawl
crime
eat
english
establish
the count of c prefixes:4
the count of china countWords:4
文章来自:http://oivoiv.blog.163.com/