Lucene Payload 的研究与应用
Lucene 是最初是由 Douglass R. Cutting 博士发布在自己主页上的一个 Java 全文信息检索工具包,后来成为 Apache Jakarta 家族中的一个开源项目,目前已经成为 Apache 基金会的顶级项目。索引是现代搜索引擎的核心,建立索引的过程就是把源数据处理成方便查询的索引文件的过程。 Lucene 采用的是一种被称为倒排索引 (Inverted Index) 的机制,倒排索引也是大多现代搜索引擎的基础。
Payload (元数据) 诞生于 Lucene 的2.2 版本,它是在 Lucene 2.1 索引文件格式的基础上扩展而来,提供了一种可以灵活配置的高级索引技术。本文重点研究了 Payload 的实现原理、索引结构的变化、接口 API ,在本文的最后举例说明了 Payload 是如何帮助改善搜索体验的。
倒排索引就是说我们维护了一个词条表,对于这个表中的每个词条,都有一个链表描述了有哪些文档包含了这个词条。假定我们有三篇文档 D0,D1,D2:
D0 = "it is what it is" D1 = "what is it" D2 = "it is a banana" |
那么,我们可以创建如下倒排索引结构:
Term Posting-list
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
|
一般情况下,将一个词条所索引的文档(一般用文档编号表示)称之为 Posting,那么一个词条索引的多个文档就称之为 Posting-list。除了在 Posting-list 中记录文档编号,Lucene 也在Posting-list 中添加了词频和位置信息。词频的添加有助于结果的排序,位置信息的添加解决了短语检索的问题。
在Lucene 2.1 中,记录位置信息的即 .prx 文件,它的格式如下:
ProxFile (.prx) --> <TermPositions> TermCount TermPositions --> <Positions> DocFreq Positions --> <PositionDelta> Freq PositionDelta --> VInt |
仔细观察我们可以发现,文档 D0 中 what 词条是加粗显示而文档 D1 中的 what 则没有。显然,Lucene 2.1 的索引结构是无法表示出两者的差异。为了解决这个问题,从 Lucene2.2 开始,引入了 Payload 的概念。 Payload 即词条 (Term) 的元数据或称载荷, Lucene 支持用户在索引的过程中将词条的元数据添加的索引库中,同时也提供了在检索结果时读取 Payload 信息的功能。Payload 的诞生为用户提供了一种可灵活配置的高级索引技术,为支持更加丰富的搜索体验创造了条件。
那么 Lucene 是如何改进索引文件以支持 Payload 功能的呢?
为了更加形象的描述改进后的索引结构,我们用不同的颜色表示出文档 ID ,词频,位置和 Payload,如图 1 所示,(U表示下划线,B表示粗体)
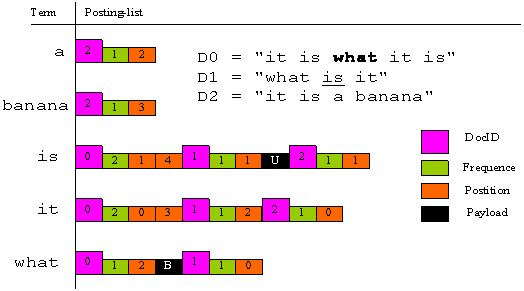
对比 Lucene2.1 的索引结构,Lucene2.2 的索引结构的表达式如下:
ProxFile (.prx) --> <TermPositions> TermCount TermPositions --> <Positions> DocFreq Positions --> <PositionDelta,Payload?> Freq Payload --> <PayloadLength?,PayloadData> PositionDelta --> VInt PayloadLength --> VInt PayloadData --> bytePayloadLength |
从上面的索引表达式中可以看出只有当一个词汇包含 Payload 信息时,Lucene 才会为之分配相应的 Payload 存储空间,这是一种高效率的空间实现。Lucene2.2 之后的 Payload 特指词条的元数据,那么文档的元数据如何表示呢?
我们知道,Lucene 中 Document 由 Field 组成,而 Field 由 Term 组成,文档的 Payload 可以用存储的 Field 表示。这样存在的问题是,如果需要读取大量的文档的元数据,因为 Field 的索引信息与存储信息是分开的,那么 I/O 效率将是较差的。而 Payload 信息则是直接存储在索引中,因此可以利用词条的 Payload 功能存储文档级别的元数据。文档级 Payload 可表示为如下图2所示格式(省略了词频和位置信息):
如图2所示,以文档的 url 信息为例,通过为每一个文档构造一个特殊的词条 ”url” ,将每个文档的 ur l值作为 payload 信息,把 Payload 与文档编号关联起来,这样就可以实现文档级的 Payload。
从 Lucene2.2 的索引结构可以看出,Payload 的存储与词条的位置信息是紧密联系在一起的,因此 Payload 的存储和检索 API 位于Token类和 TermPositions 类当中。
org.apache.lucene.analysis.Token void setPayload(Payload payload) |
org.apache.lucene.index.Payload
Payload(byte[] data)
Payload(byte[] data,
int offset,
int length)
|
org.apache.lucene.index.TermPositions
boolean next();
int doc()
int freq();
int nextPosition();
int getPayloadLength();
byte[] getPayload(byte[] data,
int offset)
|
日期检索是区间检索的常见例子,如用户需要在图书馆中检索特定年代的图书,满足如下条件:
Date>1954/08/01 & Date<1955/08/01 |
常见的做法就是将日期作为一个独立 Field 进行存储,利用 RangeQuery 进行区间检索,Posting-list 的格式如图3中左图所示。如果图书日期分布区间很广,用 Field 存储日期信息,我们需要将日期细化到年月日进行存储,因此词条数目是非常庞大的。这种情况下,我们可以利用 Payload 功能来减少词条的数目,提高检索效率,可以将日期的年月作为词条,日作为 Payload 信息,这几乎将词条数目减小了近 30 倍,改进后的存储结构如图3右图所示:
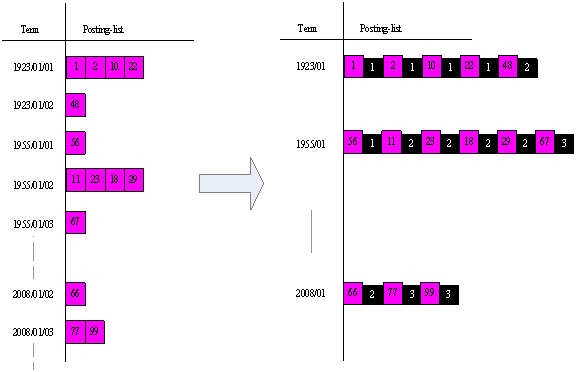
利用 Payload 功能,还可以提高文档中特定词汇的评分,如黑体词汇、斜体词汇等,从而优化搜索结果排序。
下面还以文档 D0 和 D1 为例说明如何设置和检索 Payload。
D0 = "it is what it is" D1 = "what is it" |
Step1:在 Analyzer 处理过程中,为特殊词汇添加评分 Payload
final byte BoldBoost = 5;
final byte ItalicBoost = 5;
…
Token token = new Token(…);
…
if (isBold) {//如果是黑体字
token.setPayload(
new Payload(new byte[] {BoldBoost}));
}else if(isItalic){//如果是斜体字
token.setPayload(
new Payload(new byte[] { ItalicBoost }));
}
…
return token;
|
Step2:重写 Similarity (主要负责排名和评分)
Similarity boostingSimilarity =
new DefaultSimilarity() {
// @override
public float scorePayload(byte [] payload,
int offset,
int length) {
//读取payload的值,payload存储的即为词汇的评分。
if (length == 1) return payload[offset];
};
|
Step3:使用重写的 boostingSimilarity 进行检索
Query btq = new BoostingTermQuery(
new Term(“field”, “what”));
Searcher searcher = new IndexSearcher(…);
Searcher.setSimilarity(boostingSimilarity);
…
Hits hits = searcher.search(btq);
|
Payload 是 Lucene 一个允许在索引中为词条储存元数据信息。希望通过阅读本文,你可以对Payload 功能有一个整体的了解,进而可以灵活运用 Payload 的功能来优化具体的应用。