ufferedInputStream是一个带有缓冲区的输入流,通常使用它可以提高我们的读取效率,现在我们看下BufferedInputStream的实现原理:
BufferedInputStream 内部有一个缓冲区,默认大小为8M,每次调用read方法的时候,它首先尝试从缓冲区里读取数据,若读取失败(缓冲区无可读数据),则选择从物理数据源 (譬如文件)读取新数据(这里会尝试尽可能读取多的字节)放入到缓冲区中,最后再将缓冲区中的内容部分或全部返回给用户.由于从缓冲区里读取数据远比直接 从物理数据源(譬如文件)读取速度快,所以BufferedInputStream的效率很高!
在具体看源码之前,我们还需要了解BufferedInputStream的mark操作:void mark(int markLimit)
当 你调用mark方法时,内部会保存一个markPos标志,它的值为目前读取字节流的pos位置,倘若你调用reset方法,这时候会把pos重置为 markPos的值,这样你就可以重读已经读过的字节.好像说的不是很清楚,那我们打个比方:有一段字节流是abcdefg, 当你读取完字母a调用mark方法(此时markPos指向字母b),接着你继续读取字母b,字母c,字母d,然后此时你调用reset方法(内部把 pos重置为markPos),当你再读取下一个字节的时候,你会发现你读取到的是b而不是字母e,这样通过mark方法我们就是实现了重复读(re- read the same bytes)
mark 方法中还有个参数markLimit,它的值表示在调用mark方法后reset方法前最多允许读取的字节数(根据我的测试,以及查看源代码发现,这个最 大字节数,其实是由markLimit和buffer.size中较大的那个决定的),如果超过这个限制,则在调用reset方法时会 报:Reseting to invalid mark 异常
说完了这么多,让我们来赶紧看看源码吧:
- // BufferedInputStream主要有这两个构造方法
- public BufferedInputStream(InputStream in) {
- this(in, defaultBufferSize); // 默认缓冲区为8M
- }
- public BufferedInputStream(InputStream in, int size) {
- super(in);
- if (size <= 0) {
- throw new IllegalArgumentException("Buffer size <= 0");
- }
- buf = new byte[size];
- }
你需要指定InputStream(装饰模式的体现)以及bufferSize(可选)
当我们调用read()方法时,它在内部做了一下事情:
- public synchronized int read() throws IOException {
- if (pos >= count) { // 检查是否有可读缓冲数据
- fill(); // 没有缓冲数据可读,则从物理数据源读取数据并填充缓冲区
- if (pos >= count) // 若物理数据源也没有多于可读数据,则返回-1,标示EOF
- return -1;
- }
- // 从缓冲区读取buffer[pos]并返回(由于这里读取的是一个字节,而返回的是整型,所以需要把高位置0)
- return getBufIfOpen()[pos++] & 0xff;
- }
- private byte[] getBufIfOpen() throws IOException {
- byte[] buffer = buf; // buf为内部缓冲区
- if (buffer == null)
- throw new IOException("Stream closed");
- return buffer;
- }
其中pos为缓冲区buffer下一个可读的数组下标,我们可以一直从缓冲区里读取数据,直到pos变为count(此时只能从物理数据源读取数据),下面我们就分析下,当缓冲区里没有数据可读时,BufferInputStream是如何处理的:
1. 若用户没有开启re-read功能(即未调用mark方法),当pos == count时,我们只需要将pos重新置为0,然后从物理源读取数据(假设读到了n个字节),最后把count设置成 n + pos 即可 (其实就是n,因为pos之前被设置成了0), 当下次你在调用read方法时,就直接从缓冲读取,非常快速(如下图); 
2.若用户调用了mark方法,情况就变得很复杂了,为什么呢? 这意味着我们需要保存从markPos到pos这段数据(以供用户re-read),现在我们分情况讨论:
a.此时pos < buffer.length,这意味着缓冲区还有多余空间,所以我们可以继续从物理数据源读取数据放入到缓冲区中(如下图); 
b.pos == buffer.length,这意味着缓冲区已经没有多余空间,所以只能清空缓冲区内容,但是不要忘了,我们还必须保留原来
markPos到pos那段数据,以供用户re-read,所以我需要这样做:
- // 计算需要保留多少字节的数据
- int sz = pos - markPos;
- // 然后拷贝到缓冲头部
- System.arraycopy(buffer, markpos, buffer, 0, sz);
- // 重置pos以及markPos
- pos=sz;
- markPos=0;
接着从缓冲区的sz 到 buffer.length又变成可用区间,用来存放从物理数据源读到的数据(如下图) 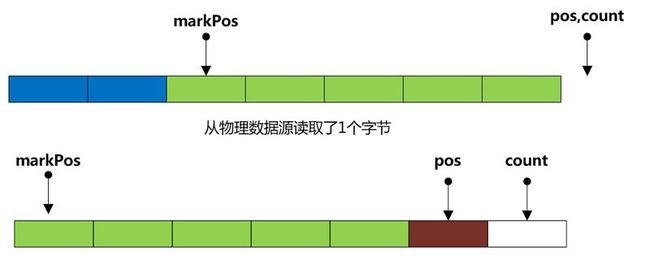
到 这里似乎问题完美的解决了,其实不然,我们忘记考虑markPos失效问题,以及若pos - markPos == buffer.length,那么移了等于白移动,还是没有挪出多余空间,所以实我们应该这样做(后面讨论都是建立在pos == buffer.length的基础上):
2.1 若markPos > 0, 那么 pos - makrPos一定小于缓冲区大小,这样意味着我们按照刚才的算法挪动后,缓冲区就有了空余空间 
2.2 若makrPos == 0, 这意味着需要保存的数据满满的充斥着缓冲区,所以这时候我们是无法通过挪动位置来使缓冲区有多余空间的,所以我们只可以清空或扩展缓冲区
2.2.1 当buffer.length >= marklimit时 ,此时意味着markPos已经失效,用户不可以在进行re-read,所以此时我们就可以简单释放整个缓冲区了:pos=0, markPos=-1;
2.2.2 其余情况,意味着markPos还有效,所以我们只能通过扩展缓冲区的方式来使缓冲区有多余空间 
说了这么多,我们还是看下相关代码吧:
- private void fill() throws IOException {
- byte[] buffer = getBufIfOpen(); // 得到当前缓冲区
- if (markpos < 0) // 对应情况1
- pos = 0;
- else if (pos >= buffer.length) // 对应情况2
- if (markpos > 0) { // 对应情况2.1
- int sz = pos - markpos;
- System.arraycopy(buffer, markpos, buffer, 0, sz);
- pos = sz;
- markpos = 0;
- } else if (buffer.length >= marklimit) { // 对应情况2.2.1
- markpos = -1;
- pos = 0;
- } else { // 对应情况2.2.2
- int nsz = pos * 2;
- if (nsz > marklimit)
- nsz = marklimit;
- byte nbuf[] = new byte[nsz];
- System.arraycopy(buffer, 0, nbuf, 0, pos);
- ...
- }
- count = pos;
- int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
- if (n > 0)
- count = n + pos;
- }
好 了关于BufferedInputStream就说道这里,它的 read(byte b[], int off, int len)其实内部实现也大概如此:先从缓冲区读,如果读不到则从物理数据源读取并刷新到缓冲区(可能需要对缓冲区原来内容作必要的挪动或者对缓冲区大小进 行扩展)