Removing GC Synchronisation
Removing GC Synchronisation
| Andy C. King [email protected] ACM No. 5256805 |
Computing Laboratory University of Kent Canterbury, Kent, CT2 7NF, UK |
Richard Jones (Advisor) [email protected] |
1. Problem & Motivation
<!-- ---------------------------------------------------- -->Java server applications typically exhibit distinctive characteristics: they are usually long-running, heavily multi-threaded, require very large heaps, are executed on large multiprocessors, load classes dynamically and demand that the garbage collector [jone96 ] provide good throughput and low pause times.
Garbage collection is based on the notion of liveness by reachability from a set of known locations, the roots . Unless the stack is scanned conservatively [boeh88 ], the mutator1 must emit stack maps [diwa92 ,ages98 ] that describe which slots in a stack frame hold roots. Because stack maps are typically updated only at certain GC points (method calls, backward branches, etc.) in order to reduce storage overheads, it is only safe to collect when the stack map is up-to-date, i.e. at a GC point.
This scheme works well for single-threaded programs as all allocation requests are GC safe points. In a multi-threaded environment, however, we must ensure that all threads are at GC safe points before a collection can continue (even concurrent systems must `stop the world' briefly to synchronise). Unless every instruction is a GC point [stic99 ], each mutator thread must be rolled forward to a GC point (either by polling or code patching [ages98a ]). The cost of this synchronisation in heavily multi-threaded environments is considerable. For example, thread suspension in the VolanoMark client [volano01 ], a client-server chat application that uses thousands of threads, incurs up to 23% of total time spent in GC (see Table 1 ).
Many objects are used by only a single thread (see Table 2 or [blan99 , bogd99 , choi99 , whal99 , ruf00 , aldr99 , aldr03 ]). If those objects that cannot escape (even potentially) the thread that allocated them are placed in a thread-specific region of the heap, that region can be collected independently of the activity of other mutator threads.
Contributions
The contributions of this work are a static analysis and novel garbage collector design and implementation that segregate objects into many thread-specific heaplets and one shared heap
:
- The analysis is based on Ruf-Steensgard [ruf00 , stee00 ] but can classify objects even in presence of incomplete knowledge.
- The system requires neither synchronisation nor locks for local collections (in contrast to [stee00 ];
- It does not use a write-barrier that may do an unbounded work (in contrast to [doma02 )];
- It is safe in the presence of dynamic class loading; and
- It has been incorporated into a production JVM, Sun's RJVM2 [whit98 ].
Since our OOPSLA'02 paper, we have improved the precision of our analysis by modelling object fields on a per-instance rather than per-class basis (although more compact, the per-class analysis allowed too many objects to escape), and we have added method specialisations.
Paper Overview
The rest of this paper is organised as follows. In Section 2 , we consider related work. Section 3 describes the heap layout that supports thread-local collection. Sections 4 explains our analysis; Section 5 describes the the collector and its implementation. We evaluate our system in Section 7 , suggest directions for future work in Section 7 and conclude in Section 8 .
2. Background & Related Work
<!-- ------------------------------------------------------------ -->Most work on synchronisation has focussed on mutator-mutator synchronisation [blan99 , bogd99 , choi99 , whal99 , ruf00 , aldr99 , aldr03 ], elimination of allocator-allocator contention through local allocation blocks [whit98 , dimp00 , ossi02 )] or collector-collector synchronisation to allow multiple collector threads to be run in parallel on each processor [ossi02 ]. Ageson compares polling and code patching techniques for rolling threads forward to GC points [ages98a ]. Stichnoth et al. [stic99 ] show how stack maps can be compressed sufficiently to allow any instruction to be a GC point.
In contrast, our work uses static analysis and a novel heap organisation to allow independent collection of thread-specific heaps without any synchronisation: it does not require all collector threads to rendezvous, nor does it require any locks to copy objects. In contrast, Steensgard [stee00 ] (upon whose escape analysis ours is based) initiates collection of all thread-specific heaps simultaneously through a global rendezvous, only after which may all threads start collection of their thread-specific heap. A global lock must also be acquired if a thread copies an object in the shared heap. Furthermore, Steensgard's system is embedded in a native code compiler rather than one that supports dynamic class loading.
A run-time alternative is to use a write barrier to trap any write of a reference to a local object into the shared heap and to mark the object as global. Marking may either take the form of setting a bit (in the object's header or the bitmap) or of copying the object out of the thread-specific region into a global heap region. The former is faster but risks fragmentation by leaving global objects in local regions [doma02 .] The latter, conversely, involves a potentially costly copy operation but maintains the strict partition between local and global objects and preserves object locality. Neither technique bounds the work done by the write-barrier.
Finally, we note that systems that use non-pre-emptive threads [alpe99 , alpe00 ] typically only switch thread contexts at GC points and hence never need to roll mutator threads forward before collection can start. Nevertheless, object segregation would allow such JVMs to collect threads independently.
<!-- ------------------------------------------------------------ -->3. Heap Layout
<!-- ------------------------------------------------------------ -->3.1 Closed Systems
We first consider closed systems, that is, systems in which we have complete knowledge of all classes that may be loaded. All threads, including the main thread, have their own local heaplets. In a closed world, there are two cases to consider.
| An object may be strictly local to a thread. No matter what method (including methods of classes yet to be loaded) may call the object's allocating method, or invoke this object's methods the object remains unreachable from any other thread. Such objects are said to be local (L ) and are allocated in the thread's L heaplet, TL . | int foo (int x) {
Thing t = new Thing(x);
return t.bar();
}
|
| An object may be (potentially) reachable from more than one thread. Such objects are said to be global (G ) and are allocated in the shared heap. There may, however, be references from local heaplets into the shared heap, H . | void foo () {
Thing t = new Thing();
Stuff.s = t;
}
|
3.2 Dynamic Class Loading
| With dynamic class loading, we do not have complete knowledge of all the classes that may be loaded. It is therefore imperative that our system function with incomplete knowledge of the program and also remain safe after new classes are loaded. As analysis is performed on a snapshot of the world, i.e. only those classes currently loaded, it is possible that classes loaded subsequently may cause objects that appeared to be local in our snapshot to become reachable by other threads. Such objects are said to be optimistically-local (OL ) and allocated in the thread's OL heaplet, T0L . | void foo (Mumble m) {
Thing t = new Thing(x);
m.wibble(t);
}
|
In summary, our analysis proves that, provided no further classes are loaded, OL objects cannot be reached by other than their allocating thread. However, should further classes be loaded, an OL object (and its transitive closure under the points-to relation) may become reachable by other threads. L , objects on the other hand, can never escape their allocating thread. <!-- <a href="#fig:lattice">Fig. 1</a> shows legitimate references between <i>L</i>, <i>OL</i> and <i>G</i> objects. --> The points-to invariants are:
|
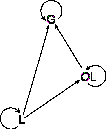 |
3.3 Non-conforming Classes
Because our analysis guarantees that there are neither G-OL , G-L nor OL-L references, we can collect a thread's L heaplet independently of all other heaplets, and its OL heaplet independently of the shared heap and of other threads. In practice, we usually collect a thread's L and OL together, independently of other threads. Only the shared heap requires a global thread rendezvous before it can be collected.
However, suppose that the loading of a new class allows an object o allocated at a site s (and o 's transitive closure, o* ) to change from OL to G . We call such a class non-conforming . All objects in o* must have been allocated in the same OL heaplet TOL as o or in the shared heap. Because we do not maintain any record of which site allocated which object, we must treat all objects in TOL as global. TOL can no longer be collected independently but instead is treated as if it were part of the shared heap, H . Furthermore, any thread Ti that invokes allocation at this site s must be treated in the same way: all Ti,OL become global.
We justify this design decision as follows. Our collector is designed for long-running server applications. We expect analysis to be delayed until most classes have been loaded so that it can take advantage of as much knowledge of the program as possible. This reduces the chance of loading a non-conforming class in the future. We expect most classes that might be loaded to conform. It is unusual for a sub-class to allow an object to escape its thread (for example, by allocating it to a static field) when its parent did not. The worst-case outcome is that there were no L heaplets and that all OL heaplets become global. But this case is simply the status quo: a single shared heap.
<!-- ---------------------------------------- -->4. Analysis
<!-- ---------------------------------------- -->Our analysis is a development of Ruf's and Steensgard's algorithms for synchronisation removal [ruf00 , stee00 ]. We group potentially aliased expressions into equivalence classes and construct polymorphic method summaries (method contexts ) that can be reused at different call sites. The algorithm is thus context-sensitive and flow-insensitive : it does not require iteration to a fixed point. Although, in the worst-case, time and space complexity is exponential, Ruf demonstrates that these analyses are fast in practice.
Unlike Ruf-Steensgard, our algorithm is compositional : any class loaded after a partial analysis of a snapshot of the program is also analysed for conformance (i.e. that no execution of any method of this class could infringe the pointer-direction invariants ) and incorporated into the system. Support for dynamic class loading is achieved by presuming fields and method parameters to be OL rather than L (unless proven otherwise). Consequently, our analysis deems only those objects that do not escape their allocating method (and thus are stack allocatable) to be L . Our current conformance check is very simple: we accept the class as conforming if and only if its method contexts are identical to those of the class that it over-rides (if any).
4.1 Specialisation
| Our analysis is context-sensitive: a method invoked with one parameter may allocate in the thread's OL heaplet and with a different parameter in the shared heap. Thus, the end-product of our analysis is a list of methods to be specialised and allocation sites to be patched. Note that it is insufficient simply to compare the locality of the formal and actual parameters to a method call. For example, consider the fragment adjoining and suppose an OL actual parameter t to a method foo has a field f that may hold a reference to a static. It is important that wherever foo passes f to any further method bar also propagates the the fact that f is G rather than OL . | Thing t = new Thing();
t.f = Mumble.g; //g is global
foo(t);
void foo (Thing t) {
bar(t.f);
}
|
Specialisation has consequences for a class' constant pool and its vtable. Both are of a fixed size, determined at class load time, but our specialisations increase the size of the pool and add further entries to the vtable. To accommodate this, we provide a second, shadow constant pool that is only used by our specialisations. Note that the shadow constant pool is guaranteed to be fully resolved. Calls to specialised methods are also handled through a shadow vtable. The cost of specialisation is thus an increase in space. Currently, we also require extra indirections for method calls but planned compiler modifications will remove these.
Finally, there is a trade-off between performing analysis earlier or later. Analysis is performed by a background thread. The sooner analysis is complete, the fewer objects that turn out to be thread-local are allocated in the shared heap. On the other hand, the later the analysis is performed, the more complete is our information (as more classes have been loaded and analysed). Thus fewer objects have to be allocated conservatively as thread-escaping. A closed system faces none of these issues as it has complete knowledge of all classes; no L objects need be allocated in the shared heap in a closed system.
<!-- -------------------------------------------- -->
5. GC Implementation
<!-- -------------------------------------------- -->Our heap comprises one shared heap and one heaplet per thread, including the main thread. The root set for the collection of a region is those locations, outside that region, that hold a reference to an object inside that region. Roots include registers, stack, globals and objects in other regions holding inter-region references. Local, thread-specific heaplets may be collected independently of each other and without collecting the shared heap as their roots are only found within that thread's stack (and registers). Thus, when a request for allocation into a thread-local heaplet cannot be satisfied, only the thread making the request need be blocked while its heaplets are collected. The invariants above allow an object to be moved by the collector as no reference to that object can be held in any object that might be accessed by another thread. Neither global rendezvous, tricolour marking nor locks are required to allow a local collection to be performed. On the other hand, collection of the shared heap does require the usual global rendezvous. All threads must be stopped since objects in the shared heap may escape the thread that allocated them. Not only may there may be references to shared objects from outside the shared heap but shared objects may be reachable from more than one thread.
It is important that space in the heap be divided appropriately between the shared heap and the thread-specific heaplets. It would, for example, be inappropriate to divide the heap equally between each heaplet and the shared heap unless the pattern of memory demands of each thread were similar. Furthermore, it is probably desirable in most environments to avoid the situation in which all threads exhaust their heaplet simultaneously; although we still do not need to synchronise, all mutator threads would be stopped.
At the lowest level, the heap is constructed from local allocation blocks (LABs), each of 4KB. When a thread runs out of space, it requests one or more new LABs from the LAB-manager. Assuming that this request can be satisfied, the thread has the exclusive right to allocate objects in that (those) LAB(s). Most allocation is therefore linear, fast and synchronisation-free. This scheme also allows heaplets to grow dynamically, making better use of available space, rather than being constrained to a fixed size. We expect this scheme to respond well to program phase changes [wils95 ] since garbage collecting a heaplet compacts it into fewer LABs.
A heaplet is a list of LABs. Our analysis requires that heaplets either be collected by their owning thread (if they do not contain any shared objects) or with the shared heap3 in a stop-the-world collection. The heaplet's header indicates whether the heaplet is L , OL or G . Each thread can collect its L and OL heaplets independently of other threads. However, dynamic class loading may mean that objects allocated in a thread's OL heaplet can no longer be guaranteed not to be shared. In this case, it is the responsibility of the loader to set the header of the OL heaplets of each affected thread to G . G heaplets are collected only by stop-the-world collection.
Objects allocated by sites later determined to be L or OL will be placed in the shared heap if they are allocated before the analysis is run. These objects may refer to objects placed in the same thread's L or OL heaplet after the analysis has run. However, this does not break invariant Inv.2 and is safe for the following reasons. Although allocated in the shared heap, the object cannot be reached by any thread other than the one that is blocked. Whenever the shared heap is collected, so are all local heaplets. Thus, inter-heaplet references can be safely updated. On the other hand, any local object that was placed in the shared heap must be treated as a root of its thread's local collection. For reasons of simplicity of implementation and because we have many more heap regions than any RJVM heap configuration, we use remsets rather than card-tables [jone96 ] to detect inter-region references. We have found the size of these sets to be very small.
The collectors can move local objects allocated in the shared heap. At collection time, a thread T 's remset is examined. Each entry must refer to an L or OL object that was placed in the shared heap. Furthermore, any other reference to this object must be from other objects local to this thread. It is therefore safe to move these objects out of the shared heap. If an object o contains a reference to an object in TL , then o must be local and can be moved to TL . Otherwise, o is either L or OL : in either case, it is safe to move o to TOL . Any future write of a TL -pointer to an object moved into TOL must be trapped and added to T 's remset in a similar fashion. This is necessary to allow TL to continue to be collected independently even after the loading of a class has caused TOL to be treated as global.
Over the shared-heap/local-heaplets structure, we lay a generational organisation. The design of this generational system is orthogonal to the design of the shared/local structure. The shared heap and the local heaplets each have two generations. However, other generational configurations are possible. For example, the system might be configured to have just a single, shared, old generation, rather than one old generation per thread. <!-- ----------------------------------------- -->
6. Evaluation
<!-- ----------------------------------------- -->The benchmarks used were the VolanoMark Client and Server [volano01 ], a client-server chat application, and SPECjbb2000 [specjbb ], which emulates a 3-tier business system. Volano Client used 1024 connections (2048 threads) and SPECjbb2000 used 4 warehouses, each running 4 threads. All benchmarks were run on a lightly loaded Sun Ultra 60, with two 450 MHz UltraSPARC-II processors sharing 512 Mbytes of memory, running the Solaris 8 operating system.
| Classes | Classes resolved | Methods | Methods resolved | L | OL | G | Specs | Bytecode (K) | Bloat | Compiled code (K) | Bloat | time (s) | |
| Volano client | 456 | 67% | 3343 | 96% | 51 | 534 | 93 | 1011 | 125 | +33% | 611 | +55% | 9.19 (10) |
| Volano server | 879 | 67% | 7662 | 95% | 236 | 1707 | 762 | 3848 | 302 | +65% | 657 | +153% | 2.40 (5) |
| SPECjbb | 681 | 73% | 5611 | 96% | 221 | 1829 | 223 | 2058 | 292 | +38% | 1974 | +58% | 3.16 (30) |
Table 3: Static analysis results.
Table 3 shows the number of classes and methods (total and fraction resolved in the snapshot), the number of L , OL and G allocation sites, the number of methods specialised, the code size (original and increase for both bytecode and compiled code) and the analysis time (and start time) for each benchmark.
The snapshot tactic resolves almost all methods despite capturing a smaller fraction of classes (but note that these benchmark applications typically load small reporting classes at the end of the run). The number of L and OL allocation sites is encouraging (but we have yet to measure volume or space rental of objects allocated). Analysis times are acceptable for long-running server applications but very susceptible to the number of threads running (the analysis runs in a separate background thread). However, code size is increased significantly; it may be better to profile methods and only specialise those that allocate heavily.
7. Future Work
<!-- ----------------------------------------- -->At the time of writing, the implementation of the analysis and the collector is complete and run-time experiments are about to start.
We plan a number of improvements to the system. The collector should move thread-local objects allocated in the shared heap (before analysis) to their own heaplet whenever they are discovered in the heaplet's remset. Methods in dynamically loaded classes are only assumed to conform if their method contexts are identical to those of already loaded methods. Better conformance rules for dynamically loaded classes are almost certainly possible. Efficient use of the heap by many heaplets will be vital. We intend to investigate better GC triggers than simply `heap full'. We intend to remove the additional indirections required by calls to specialised methods (through shadow vtables).
Above all, this system offers a wide design space for garbage collection policy. For example, how rapidly and to what size should heaplets be expanded? The simplest growth policy is to expand heaplets by one LAB at a time. However, it might be better to allow memory-greedy threads to expand more rapidly in order to reduce LAB-manager synchronisation overhead. It is also important to decide when to collect and what to collect. Again, a simple solution may be allow heaplets to grow without restraint and to collect a heaplet only when the heap is full. However, as we noted above, this policy is likely to cause all threads to collect at about the same time - when the heap is full. It may be better to force a thread to collect (by denying a request for a LAB) when its volume of allocation since its last collection has exceed a threshold [zorn89 ]. Assuming a mix of thread behaviours, such a policy will reduce the tendency of all threads to collect simultaneously. A variation on this solution is to favour threads that are more active. Suppose the thread mix consists of a number of threads with growing memory footprints and other threads that have more stationary footprints. Rather than force the growing threads to collect repeatedly (which may offer comparatively small returns if the thread is constructing a large data structure - a commonly observed behaviour), it may be better to force collection of threads whose growth phase has stopped (by denying LAB allocation requests). Similarly, denial of LAB requests may be used to ensure that no thread remains uncollected for long periods of time. Other collection policies based on a thread's allocation and collection history are possible. <!-- ----------------------------------------- -->
8. Conclusion
<!-- ----------------------------------------- -->We have presented a novel static analysis and garbage collector design that allows the heap to be divided into thread-specific heaplets that can be collected independently, thereby removing need to synchronise all mutator threads for GC. The analysis and collector has been incorporated into a production JVM.
Acknowledgements
Much gratitude is due to the following people: Richard Jones, for the invaluable contributions he made and the immeasurable patience he showed throughout this work; Steve Heller and David Detlefs of the Java Technology Group at Sun Microsystems Laboratories East for providing RJVM; Ralph Miarka, for assisting with the layout of this document.
Footnotes
| 1. | Liveness by reachability provides a conservative estimate of what is live. Objects may no longer be needed by the application even though they are reachable from the roots [hirz02a ]. |
| 2. | Mutator is the term used in the memory management literature for the application program. From the memory manager's point of view, all it does is change the shape of the object graph. |
| 3. | Sun Microsystems Laboratories' Virtual Machine for Research, previously known as ExactVM, EVM or Java 2 SDK (1.2.2_06) Production Release for Solaris. |
| 4. | Actually, shared heaplets could be collected separately (cf . Beltway [blac02 ]) but either the world would have to be stopped or an incremental collector used. |