1.count
2.groupByKey
3.join
4.union
5.reduceByKey
Shuffle/Dependency总结
ShuffleMapTask将数据写到内存(或者磁盘)供ResultTask来拉取,那么写的策略是什么?ResultTask怎么知道拉取属于它的数据,那么这里头Mapper和Reducer应该通力协作,工作完成数据的写和读操作。
1. count
/** * Return the number of elements in the RDD. */ def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
Utils.getIteratorSize算出一个worker上的elements的数目,然后然后通过sum操作,将所有worker节点上的elements数目进行相加
先在每个 partition 上执行 count,然后执行结果被发送到 driver,最后在 driver 端进行 sum。
2. groupByKey
package spark.examples
import java.util.Random
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.SparkContext._
/**
* Usage: GroupByTest [numMappers] [numKVPairs] [valSize] [numReducers]
*/
object SparkGroupByTest {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("GroupBy Test").setMaster("local ")
val numMappers = 1//100
val numKVPairs = 100//00
val valSize = 10//00
val numReducers = 36
val sc = new SparkContext(sparkConf)
///定义numMappers个元素的集合,对每个元素调用flatMap操作
val pairs1 = sc.parallelize(0 until numMappers, numMappers).flatMap { p =>
///随机数,作为arr1的元素类型(K,V)中的K
val ranGen = new Random
///定义一个数组,长度为numKVPairs。元素类型是(K,V)的二元组,K的类型是Int,V的类型是字节数组(字节长度为valSize)
val arr1 = new Array[(Int, Array[Byte])](numKVPairs)
///对长度为numKVPairs的arr1进行填充值
for (i <- 0 until numKVPairs) {
///创建数组元素的字节数组,数组长度为valSize
val byteArr = new Array[Byte](valSize)
ranGen.nextBytes(byteArr)
//K是随机生成的整数
arr1(i) = (ranGen.nextInt(Int.MaxValue), byteArr)
}
arr1
}.cache
// Enforce that everything has been calculated and in cache
//action操作,将数据缓存,并且返回所有的(K,V)对
println(pairs1.toDebugString);
/*cache的是FlatMappedRDD
FlatMappedRDD[1] at flatMap at SparkGroupbyTest.scala:26 [Memory Deserialized 1x Replicated]
ParallelCollectionRDD[0] at parallelize at SparkGroupbyTest.scala:26 [Memory Deserialized 1x Replicated]
*/
pairs1.count
///根据Reducer个数做groupBy操作,
println(pairs1.groupByKey(numReducers).count)
sc.stop()
}
}
1. groupByKey的含义是对(K,V)进行合并。
例如:
节点1: (1,2),(1,3),(2,6)
节点2: (1,7),(3,8),(2,9)
那么groupByKey结束后得到的结果是什么?
(1,(2,7)),(1,(3,7)),(2,(6,9)), (3,(_,8))? 不对,最后的结果,应该是Key是唯一的
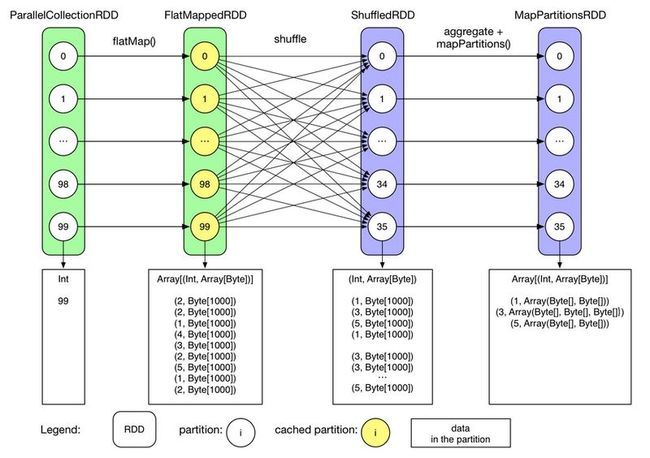
2. 上面的例子中,reducer的个数是36,那么要做group操作,所以,来自各个worker节点的相同的Key必须由同一个reducer上来处理,这是怎么做到的?即reducer拉取数据时,是按照Key做Hash么?hash(key)%36. 即m个mapper结果,由r个reducer消费,如何消费?每个mapper都有reducer的数据,reducer如何拉取应该由它处理的这些数据?从不同的mapper中拉取数据,这就是Shuffle Write的工作!是分布式计算框架的核心之一
3. 如下图所示:ShuffledRDD存放的时比较合并的结果,只是从FlatMappRDD将原始数据拉取过来?拉取数据时,Mapp端没有做预combine操作??
4. groupByKey操作是一个根据Key把所有的Value聚合到一起的操作,这跟SQL的groupBy操作不一样,SQL的groupBy操作的结果是,一组的结果是每个占据一行。
5. groupByKey不要是用map端的combine
/**
* Group the values for each key in the RDD into a single sequence. Allows controlling the
* partitioning of the resulting key-value pair RDD by passing a Partitioner.
* The ordering of elements within each group is not guaranteed, and may even differ
* each time the resulting RDD is evaluated.
*
* Note: This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using [[PairRDDFunctions.aggregateByKey]]
* or [[PairRDDFunctions.reduceByKey]] will provide much better performance.
*/
//groupByKey不使用map端的combine,为什么还要创建combineByKey?额。。指明了mapSideCombine=false
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = {
// groupByKey shouldn't use map side combine because map side combine does not
// reduce the amount of data shuffled and requires all map side data be inserted
// into a hash table, leading to more objects in the old gen.
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKey[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine=false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}
3. join
package spark.examples
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.SparkContext._
object SparkRDDJoin {
def main(args : Array[String]) {
val conf = new SparkConf().setAppName("Join").setMaster("local");
val sc = new SparkContext(conf);
//第一个参数是集合,第二个参数是分区数
val rdd1 = sc.parallelize(List((1,2),(2,3), (3,4),(4,5),(5,6)), 3)
val rdd2 = sc.parallelize(List((3,6),(2,8)), 2);
//join操作的RDD的元素类型必须是K/V类型
val pairs = rdd1.join(rdd2);
println(pairs.foreach(println(_)));
/*
(3) FlatMappedValuesRDD[4] at join at SparkRDDJoin.scala:17 []
| MappedValuesRDD[3] at join at SparkRDDJoin.scala:17 []
| CoGroupedRDD[2] at join at SparkRDDJoin.scala:17 []
+-(3) ParallelCollectionRDD[0] at parallelize at SparkRDDJoin.scala:13 []
+-(2) ParallelCollectionRDD[1] at parallelize at SparkRDDJoin.scala:14 []
*/
println(pairs.toDebugString)
}
}
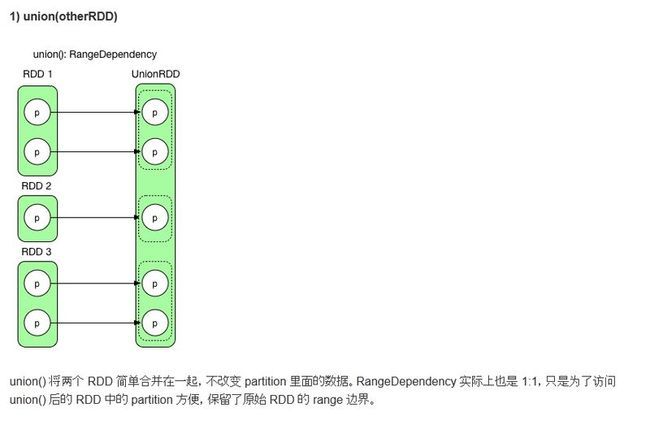
4. Union
源代码:
package spark.examples
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.SparkContext._
object SparkRDDUnion {
def main(args : Array[String]) {
val conf = new SparkConf().setAppName("Join").setMaster("local");
val sc = new SparkContext(conf);
//第一个参数是集合,第二个参数是分区数
val rdd1 = sc.parallelize(List((1,2),(2,3), (3,4),(4,5),(5,6)), 3)
val rdd2 = sc.parallelize(List((3,6),(2,8)), 2);
val pairs = rdd1.union(rdd2);
pairs.saveAsTextFile("file:///D:/union" + System.currentTimeMillis());
println(pairs.toDebugString)
}
}
1. RDD依赖图
UnionRDD[2] at union at SparkRDDUnion.scala:16 []
| ParallelCollectionRDD[0] at parallelize at SparkRDDUnion.scala:13 []
| ParallelCollectionRDD[1] at parallelize at SparkRDDUnion.scala:14 []
2. 没有Shuffle过程,因为执行过程中没有执行ShuffleMapTask,而是仅仅执行了ResultTask(一共有五个任务)
3. 结果有5个结果文件,part-00000到part-00004,内容分布为
part-00000:(1,2)
part-00001:(2,3) (3,4)
part-00002:(4,5) (5,6)
part-00003: (3,6)
part-00004:(2,8)
问题:结果的规律在哪里?
4. RDD的依赖图
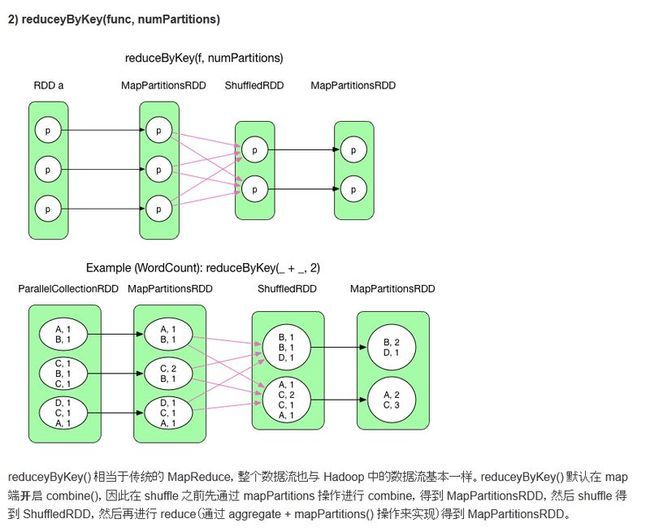
5. reduceByKey
1.源代码
2.RDD依赖图
object SparkWordCount {
def main(args: Array[String]) {
System.setProperty("hadoop.home.dir", "E:\\devsoftware\\hadoop-2.5.2\\hadoop-2.5.2");
val conf = new SparkConf()
conf.setAppName("SparkWordCount")
conf.setMaster("local[3]")
conf.set("spark.shuffle.manager", "sort");
val sc = new SparkContext(conf)
val rdd1 = sc.textFile("file:///D:/word.in.3");
val rdd2 = rdd1.flatMap(_.split(" "))
val rdd3 = rdd2.map((_, 1))
val rdd4 = rdd3.reduceByKey(_ + _); ///关键看预reduce是在第一个stage的哪个RDD中执行的
println("rdd3:" + rdd3.toDebugString)
rdd3.saveAsTextFile("file:///D:/wordout" + System.currentTimeMillis());
sc.stop
}
}
3.RDD的reduceByKey会在mapper端做mini reduce,即进行数据的预reduce,在map端对重复Key进行func操作
4. reduceByKey使用了mapper端的combine,那么,它是在调用RDD的reduceByKey的时候,由于隐式类型转换,而调用
combineKey的三个函数参数含义解释:
假设一组具有相同 K 的 <K, V> records 正在一个个流向 combineByKey(),createCombiner 将第一个 record 的 value 初始化为 c (比如,c = value),然后从第二个 record 开始,来一个 record 就使用 mergeValue(c, record.value) 来更新 c,比如想要对这些 records 的所有 values 做 sum,那么使用 c = c + record.value。等到 records 全部被 mergeValue(),得到结果 c。假设还有一组 records(key 与前面那组的 key 均相同)一个个到来,combineByKey() 使用前面的方法不断计算得到 c'。现在如果要求这两组 records 总的 combineByKey() 后的结果,那么可以使用 final c = mergeCombiners(c, c') 来计算。
/**
* Generic function to combine the elements for each key using a custom set of aggregation
* functions. Turns an RDD[(K, V)] into a result of type RDD[(K, C)], for a "combined type" C
* Note that V and C can be different -- for example, one might group an RDD of type
* (Int, Int) into an RDD of type (Int, Seq[Int]). Users provide three functions:
*
* - `createCombiner`, which turns a V into a C (e.g., creates a one-element list)
* - `mergeValue`, to merge a V into a C (e.g., adds it to the end of a list)
* - `mergeCombiners`, to combine two C's into a single one.
*
* In addition, users can control the partitioning of the output RDD, and whether to perform
* map-side aggregation (if a mapper can produce multiple items with the same key).
*/
def combineByKey[C](createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null): RDD[(K, C)] = {
require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0
if (keyClass.isArray) {
if (mapSideCombine) {
throw new SparkException("Cannot use map-side combining with array keys.")
}
if (partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("Default partitioner cannot partition array keys.")
}
}
val aggregator = new Aggregator[K, V, C](createCombiner, mergeValue, mergeCombiners) ///Aggragator的构造是三个函数
if (self.partitioner == Some(partitioner)) { ////这是什么意思?无需生成ShuffledRDD,但还是做了combineValuesByKey操作
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else { ///得到ShuffleRDD,携带aggregator以及mapSieCombine
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
}
RDD算子与shuffleDependency小结
combineByKey()
分析了这么多 RDD 的逻辑执行图,它们之间有没有共同之处?如果有,是怎么被设计和实现的?
仔细分析 RDD 的逻辑执行图会发现,ShuffleDependency 左边的 RDD 中的 record 要求是 <key, value> 型的,经过 ShuffleDependency 后,包含相同 key 的 records 会被 aggregate 到一起,然后在 aggregated 的 records 上执行不同的计算逻辑。实际执行时很多 transformation() 如 groupByKey(),reduceByKey() 是边 aggregate 数据边执行计算逻辑的,因此共同之处就是 aggregate 同时 compute()。Spark 使用 combineByKey() 来实现这个 aggregate + compute() 的基础操作。
combineByKey() 的定义如下:
/**
* Generic function to combine the elements for each key using a custom set of aggregation
* functions. Turns an RDD[(K, V)] into a result of type RDD[(K, C)], for a "combined type" C
* Note that V and C can be different -- for example, one might group an RDD of type
* (Int, Int) into an RDD of type (Int, Seq[Int]). Users provide three functions:
*
* - `createCombiner`, which turns a V into a C (e.g., creates a one-element list)
* - `mergeValue`, to merge a V into a C (e.g., adds it to the end of a list)
* - `mergeCombiners`, to combine two C's into a single one.
*
* In addition, users can control the partitioning of the output RDD, and whether to perform
* map-side aggregation (if a mapper can produce multiple items with the same key).
*/
def combineByKey[C](createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null): RDD[(K, C)] = {
require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0
if (keyClass.isArray) {///如果Key是数组,那么既不能做map端的combine,也不能使用Hash分区器
if (mapSideCombine) {
throw new SparkException("Cannot use map-side combining with array keys.")
}
if (partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("Default partitioner cannot partition array keys.")
}
}
////通过createCombiner, mergeValue, mergeCombiners三元组构造Aggregator
val aggregator = new Aggregator[K, V, C](createCombiner, mergeValue, mergeCombiners)
if (self.partitioner == Some(partitioner)) { ///
self.mapPartitions(iter => { ///转换为MapPartitionsRDD,这是窄依赖
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else {///构造ShuffleRDD时,需要带入Aggregator
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
}
其中主要有三个参数 createCombiner,mergeValue 和 mergeCombiners。简单解释下这三个函数及 combineByKey() 的意义,注意它们的类型:
假设一组具有相同 K 的 <K, V> records 正在一个个流向 combineByKey(),createCombiner 将第一个 record 的 value 初始化为 c (比如,c = value),然后从第二个 record 开始,来一个 record 就使用 mergeValue(c, record.value) 来更新 c,比如想要对这些 records 的所有 values 做 sum,那么使用 c = c + record.value。等到 records 全部被 mergeValue(),得到结果 c。假设还有一组 records(key 与前面那组的 key 均相同)一个个到来,combineByKey() 使用前面的方法不断计算得到 c'。现在如果要求这两组 records 总的 combineByKey() 后的结果,那么可以使用 final c = mergeCombiners(c, c') 来计算。
代码中有段关键的逻辑,如下所示,含义是如果条件成立,则返回MappedPartitionRDD,这是一个窄依赖,否则就是ShuffledRDD(宽依赖)
if (self.partitioner == Some(partitioner)) {
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
}
self.partitioner表示的父RDD的partitioner,而Some(partitioner)的partitioner表示的combineByKey传入的参数,问题这个partitioner是如何传入的?
对于reduceByKey而言,
/**
* Merge the values for each key using an associative reduce function. This will also perform
* the merging locally on each mapper before sending results to a reducer, similarly to a
* "combiner" in MapReduce. Output will be hash-partitioned with numPartitions partitions.
*/
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)] = {
reduceByKey(new HashPartitioner(numPartitions), func) ////使用HashPartitioner
}
/**
* Merge the values for each key using an associative reduce function. This will also perform
* the merging locally on each mapper before sending results to a reducer, similarly to a
* "combiner" in MapReduce. Output will be hash-partitioned with the existing partitioner/
* parallelism level.
*/
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = {
reduceByKey(defaultPartitioner(self), func) ////也是使用HashPartitioner
}
defaultPartitioner的代码:
/**
* Choose a partitioner to use for a cogroup-like operation between a number of RDDs.
*
* If any of the RDDs already has a partitioner, choose that one.
*
* Otherwise, we use a default HashPartitioner. For the number of partitions, if
* spark.default.parallelism is set, then we'll use the value from SparkContext
* defaultParallelism, otherwise we'll use the max number of upstream partitions.
*
* Unless spark.default.parallelism is set, the number of partitions will be the
* same as the number of partitions in the largest upstream RDD, as this should
* be least likely to cause out-of-memory errors.
*
* We use two method parameters (rdd, others) to enforce callers passing at least 1 RDD.
*/
def defaultPartitioner(rdd: RDD[_], others: RDD[_]*): Partitioner = {
val bySize = (Seq(rdd) ++ others).sortBy(_.partitions.size).reverse
for (r <- bySize if r.partitioner.isDefined) {
return r.partitioner.get
}
if (rdd.context.conf.contains("spark.default.parallelism")) {
new HashPartitioner(rdd.context.defaultParallelism)
} else {
new HashPartitioner(bySize.head.partitions.size)
}
}
}