Linkedin网站技术架构简介
引用说明:原文来自于http://skyuu.blog.163.com/blog/static/9959273920091024111332625,为了方便本人阅读,文本格式略有调整。
在JavaOne 2008的会议上,著名社交网站LinkedIn的开发者做了2个关于LinkedIn网站的架构技术的演讲
可以看一下LinkedIn网站的基本情况:
2. 每个月4百万独立用户访问
3. 每天4千万Page View
4. 每天2百万搜索流量
5. 每天25万邀请发送
6. 每天1百万的回答提交
7. 每天2百万的Email消息发送
这是一个世界顶尖级别流量的网站了,看看LinkedIn的系统架构:
- 操作系统:Solaris (running on Sun x86 platform and Sparc)
- 应用服务器:Tomcat and Jetty as application servers
- 数据库:Oracle and MySQL as DBs
- 没有ORM,直接用JDBC No ORM (such as Hibernate); th** use straight JDBC
- 用ActiveMQ在发送JMS. (It"s partitioned by type of messages. Backed by MySQL.)
- 用lucene做搜索Lucene as a foundation for search
- Spring做逻辑架构Spring as glue
下面是随着流量增加,LinkedIn的架构演化:
2003~2005
2 一个核心数据库,
3 在Cloud中缓存所有network图,Cloud是用来做缓存的独立server。
4 用Lucene做搜索,也跑在Cloud中。
2006年
2 把搜索从Cloud中移出来,单独一个Server跑搜索
3 增加Databus数据总线来更新数据,这是通过分布式更新的核心组件,任何组件都需要Databus
2008年
2 每个服务有自己的域数据库
3 新的架构允许其他应用链接LinkedIn,比如增加的招聘和广告业务。
The Cloud
2 Cloud大小:22M nodes, 120M edges
3 需要12GB RAM
4 在生产环境要跑40个实例
5 从硬盘重建Cloud一个实例需要8个小时
6 Cloud通过databus实时更新
7 关闭时持久化到硬盘
8 缓存通过C++实现,用JNI调用,LinkedIn选择C++而不是Java有两个原因:
2)垃圾收集暂停会杀死整个系统,LinkedIn用了最新的GC程序
10 Sun提供了2TB的RAM
Communication Architecture交流架构包括:
Communication Service是用来提供永久信息的,比如收件箱里面的消息和email
2 客户端用JMS发送消息
3 消息通过路径服务器来到达相应的邮箱或者直接放到email进程中
4 消息发送:同时使用Pull主动寻求信息(如用户需要信息)和Push发送信息(如发email)
5 使用Spring和LinkedIn专业Spring插件完成,使用HTTP-RPC
Scaling Techniques
2 通过类别来划分:用户信箱,访问者信箱等
3 等级划分:用户ID等级,Email等级等
4 所有的操作都是异步的。
PPT分享:
- LinkedIn Communication Architecture
- A Professional Network built with Java Technologies and Agile Practices
----------------------------------------------------------------------------------------------------------
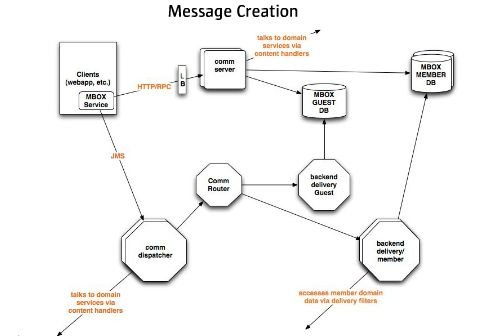
创建消息:
1 客户端通过 JMS 发帖子
2 消息通过路由服务器发到合适的贴箱或直邮流程
3 支持多会员或访客数据库
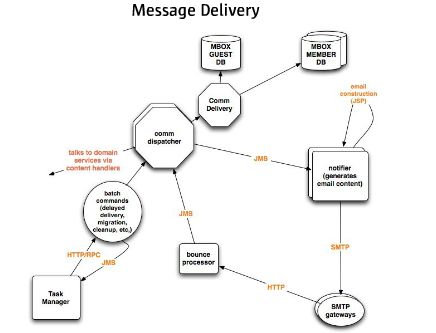
传递消息:
1 客户解发或定时任务触发消息传递
2 异步传送
3 批处理合并多个消息到一个收件消息
4 消息内容主体通过 jsp 漂亮展示
5 定时调度可以按照用户热度、延迟时间、系统负载进行调整
6 需要处理退回的消息和再次发送
7 提醒系统也走相同消息路由
故障恢复:
1 消息被退回
2 丢失消息的地方:
数据库问题
代码bug
内容传递bug
服务不可用
3 避免宕机
扩容:
1 功能分区:
发送、收到、归档
2 经典分区:
会员邮箱
访客邮箱
企业邮箱
3 范围分区:
会员ID 分区
邮件词典分区
4 异步流
微博:
1 用于大量短期存活的消息分发弹性
2 多种客户端方式都有效(web app,RSS,api,mobile,third-party...)
3 2007年是简单 UI, 2008 年是干净 UI
4 第一个阶段
(1)基于拉架构
(2)收藏:负责收集数据,并发收集提高性能
(3)解决:抓取状态,批查询队列,使用 EHCache 缓存数据
(4)发送:xml 格式
(5)经验教训:单一服务器更新故障,应该花时间调整http最大连接数和超时,不要将最常用的数据放到 EHCache 性能很差。
5 第二阶段
(1)“Don't call me, I'll call you”
(2)当事件发生后,使用推方法更新
(3)不再搜索读取非常快
(4)利弊:发送出去的微博从来没被读取,需要更多的存储空间
(5)推送
- 通过 JMS 推送
- 总体数据存储在每个目标用户的一个 CLOB 列中
- 传入的微博合并到总体数据结构时使用乐观锁,避免锁争
- 增加一个新的收集器用于从数据库中读取数据
- 使用池执行微博流的任意转换(将10个微博折叠成1个)
- 低估了微博的处理量
- CLOB 块大小设置为8k,导致大量浪费,这是不可回收的
- 实时监视、配置 JMX 规范是很有用的。
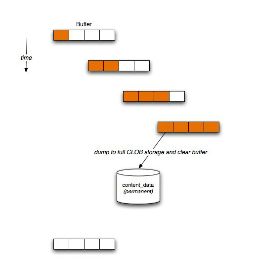
- 使用一个溢出缓冲区
- 减小更新的大小
- 增加一个 varchar(4000)字段担任缓冲区
- 当缓冲区装满了后,转存到 CLOB ,清空缓冲区
- 避免 CLOB 的超过 90% 更新(取决于类型),保持更多的存储弹性
- 单一数据库是搞不定的
- 参照完整性是不可能的
- 需要考虑成本因素了:数据库、硬件、存储
- 丢失数据是个问题了
- 数据仓库和分析成了问题
- 垃圾数据攻击和数据搜刮
- 所有事情都分区:用户群,地域,功能
- 缓存是好的,即使影响比较温柔
- 放弃 100% 的数据一致性
- 建立异步流
- 建立和报告考虑
- 预料可能在任意点失败
- 不要低估成长的轨迹
- 时间跨度
- 内存规模