一、Index属性介绍
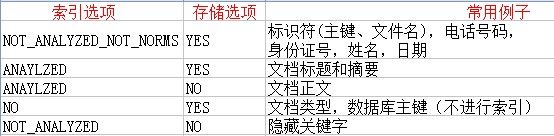
Field.Store.YES或者NO(存储域选项)
YES:将会存储域值,原始字符串的值会保存在索引中,以此可以进行相应的恢复操作,对于主键,标题可以是这种方式存储
NO:不会存储域值,通常与Index.ANAYLIZED合起来使用,索引一些如文章正文等不需要恢复的文档 , 此时内容无法完全还原(doc.get)
Field.Index(索引选项)
Index.ANALYZED:进行分词和索引,适用于标题、内容等
Index.NOT_ANALYZED:进行索引,但是不进行分词,如果身份证号,姓名,ID等,适用于精确搜索
Index.ANALYZED_NOT_NORMS:进行分词但是不存储norms信息,这个norms中包括了创建索引的时间和权值等信息
Index.NOT_ANALYZED_NOT_NORMS:即不进行分词也不存储norms信息
Index.NO:不进行索引
使用场景
二、索引文件的初步认识:
_0.fdt
_0.fdx
---存储域的值---
_0.fnm
---存储域的名称---
_0.frq
---分词出现的频率---
_0.nrm
---存储评分信息---
_0.prx
---位偏移量---
_0.tii
_0.tis
---索引信息---
三、索引建立步骤
1、创建Directory
Directory directory = FSDirectory.open(new File("D:/test/index01"));
2、创建Writer
IndexWriter writer = new IndexWriter(directory, new IndexWriterConfig(Version.LUCENE_35,new StandardAnalyzer(Version.LUCENE_35)));
3、创建文档并且添加索引
文档和域的概念很重要
文档相当于表中的每一条记录,域相当于表中每一个字段
Document document = null;
Collection<File> files = FileUtils.listFiles(new File("D:/test/lucene"),FileFileFilter.FILE, null);
for (File file : files) {
document = new Document();
document.add (new Field ("content ", new FileReader(file)));
//域名可以重复使用,在 使用 的时候 这样取出,doc.getValues("content")[1]
document.add (new Field ("content ", "可以再次放置一些内容");
document.add(new Field("filename", file.getName(), Field.Store.YES, Field.Index.NOT_ANALYZED));
document.add(new Field("path", file.getAbsolutePath(), Field.Store.YES,Field.Index.NOT_ANALYZED));//是否存储路径,是否进行分词
writer.addDocument (document);
}
4、查询索引的基本信息
IndexReader reader = IndexReader.open(directory);
//通过reader可以有效的获取到文档的数量
System.out.println("numDocs:" + reader.numDocs() );//可以使用的文档数量
System.out.println("maxDocs:" + reader.maxDoc() );//所有的文档数量,包括被删除的文档
System.out.println("deleteDocs:" + reader.numDeletedDocs() );//被删除的文档数量
reader.close();
5、删除索引
//参数是一个选项,可以是一个Query,也可以是一个term,term是一个精确查找的值
//此时删除的文档并不会被完全删除,而是存储在一个回收站中的,可以恢复
writer.deleteDocuments (new Term ("id", "1"));
writer.commit();
6、恢复删除
try {
//恢复时,必须把IndexReader的只读(readOnly)设置为false
IndexReader reader = IndexReader.open(directory, false);
reader.undeleteAll ();
reader.close();
}
7、强制删除,相当于删除回收站里面的,彻底删除了
writer = new IndexWriter(directory, new IndexWriterConfig(Version.LUCENE_35, new StandardAnalyzer(Version.LUCENE_35))); writer.forceMergeDeletes ();
8、优化和合并索引
writer = new IndexWriter(directory, new IndexWriterConfig(Version.LUCENE_35, new StandardAnalyzer(Version.LUCENE_35))); //会将索引合并为2段,这两段中的被删除的数据会被清空 //特别注意:此处Lucene在3.5之后不建议使用,因为会消耗大量的开销, //Lucene会根据情况自动处理的 writer.forceMerge (2);
9、更新索引
writer = new IndexWriter(directory, new IndexWriterConfig(Version.LUCENE_35,
new StandardAnalyzer(Version.LUCENE_35)));
/*
* Lucene并没有提供更新,这里的更新操作其实是如下两个操作的合集
* 先删除之后再添加
*/
Document doc = new Document();
doc.add(new Field("id", "11", Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS));
doc.add(new Field("email", emails[0], Field.Store.YES, Field.Index.NOT_ANALYZED));
doc.add(new Field("content", contents[0], Field.Store.NO, Field.Index.ANALYZED));
doc .add(new Field("name", names[0], Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS));
writer.updateDocument(new Term("id", "1"), doc);
//会把原来id=1的那个文档删掉,新增id=11的那个文档