HBase HFile与Prefix Compression内部实现全解--KeyValue格式
1. 引子
HFile (HBase File)是HBase使用的一种文件存储格式的抽象,
目前存在两种版本的HFile: HFile V1和HFile V2
HBase 0.92之前的版本仅支持HFile V1,
HBase 0.92/0.94同时支持HFile V1和HFile V2。
以下分别是HFile V1/V2的结构图:
HFile V1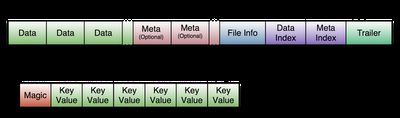
HFile V2
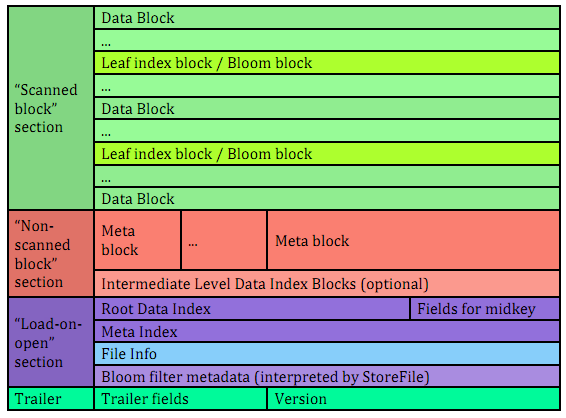
(注: 这两个图片在hbase 0.94的svn目录: src\site\resources\images)
图中的数据块(Data block)正是实际存放应用数据的地方,
每个数据块又由一系列的KeyValue组成,并且这些KeyValue之间是按Key升序排列的,
本文将说明KeyValue到底是什么以及当KeyValue越来越多时出现大量类似的数据有哪些算法能减少重复?
首先来看一个例子:
假设需要将用户的基本信息以及正在参与的开源项目的有关信息存入HBase:
- 用户基本信息 参与的开源项目
- --------------------- ----------------------------
- 用户Id 职业 性别 tomcat hbase
- --------------------- ----------------------------
- zhh2009 码农 男 提patch打酱油 提patch打酱油
- 用户Id 职业 性别 tomcat ant
- --------------------- ----------------------------
- jdd1999 码神 男 创始人 创始人
- ---------------------------------------------------------
- 表1.1
用户基本信息 参与的开源项目
--------------------- ----------------------------
用户Id 职业 性别 tomcat hbase
--------------------- ----------------------------
zhh2009 码农 男 提patch打酱油 提patch打酱油
用户Id 职业 性别 tomcat ant
--------------------- ----------------------------
jdd1999 码神 男 创始人 创始人
---------------------------------------------------------
表1.1
从这个例子来看,用户的基本信息比较好确定,但是参与的开源项目不确定且在开源项目中扮演的角色也不确定,
所以用关系数据库不太好建表,因为不知道具体有多少列,也无法把相关的列归成一个组。
1.1 列族
HBase是一种基于列的数据库,相关的列可以归到一个列族(Column Family),
每个列族中具体有哪些列不必事先知道,可以在需要的时候添加,比如在用户基本信息中为zhh2009加入email这样的列,
上例中"用户基本信息"和"参与的开源项目"可以作为两个列族,
不同的列族在HBase内部通常对应一个目录,这样不同的列值只会放到它所属的列族目录下。
1.2 rowKey
我们希望通过查询某个列就能把同一个列族或多个列族中的信息取出来,用户Id就是这样的列,
比如当我们要查询zhh2009的邮箱和参与的开源项目时,根据用户Id来查就不会查到jdd1999的信息,
在HBase中称这样的列为rowKey。
HBase是如何存放上例中的信息呢?
将用户Id这一列抽出来作为rowKey, 把上面的信息按如下格式扁平化:
- <rowKey, 列族名称, 列名 => 列值>
- -----------------------------------------------------
- <zhh2009, 用户基本信息, 职业 => 码农>
- <zhh2009, 用户基本信息, 性别 => 男>
- <zhh2009, 参与的开源项目, tomcat => 提patch打酱油>
- <zhh2009, 参与的开源项目, hbase => 提patch打酱油>
- <jdd1999, 用户基本信息, 职业 => 码神>
- <jdd1999, 用户基本信息, 性别 => 男>
- <jdd1999, 参与的开源项目, tomcat => 创始人>
- <jdd1999, 参与的开源项目, ant => 创始人>
- -----------------------------------------------------
- 表1.2
<rowKey, 列族名称, 列名 => 列值>
-----------------------------------------------------
<zhh2009, 用户基本信息, 职业 => 码农>
<zhh2009, 用户基本信息, 性别 => 男>
<zhh2009, 参与的开源项目, tomcat => 提patch打酱油>
<zhh2009, 参与的开源项目, hbase => 提patch打酱油>
<jdd1999, 用户基本信息, 职业 => 码神>
<jdd1999, 用户基本信息, 性别 => 男>
<jdd1999, 参与的开源项目, tomcat => 创始人>
<jdd1999, 参与的开源项目, ant => 创始人>
-----------------------------------------------------
表1.2
表1.2中的每一行在HBase中对应一个KeyValue,
"=>"左边的是KeyValue中的"Key","=>"右边对应KeyValue中的"Value"。
当然这只是KeyValue的一个简化格式,内部格式并非那么简单,我们接下来看看真实的KeyValue是怎样的?
2. KeyValue内部格式
KeyValue内部格式可以分成三部份: 头、Key、Value,如表2.1所示
- 名称 字节数 说明
- --------------------------------------------------------------------
- keyLength 4 表示Key所占的总字节数
- valueLength 4 表示Value所占的总字节数
- rowKeyLength 2 表示rowKey所占的字节数
- rowKey rowKeyLength rowKey
- columnFamilyLength 1 表示列族名称所占的字节数
- columnFamily columnFamilyLength 列族名称
- columnName columnNameLength 列名
- timestamp 8 时间戳
- type 1 Key类型,比如是新增(Put),还是删除(Delete)
- value valueLength 列值
- --------------------------------------------------------------------
- 表2.1
名称 字节数 说明
--------------------------------------------------------------------
keyLength 4 表示Key所占的总字节数
valueLength 4 表示Value所占的总字节数
rowKeyLength 2 表示rowKey所占的字节数
rowKey rowKeyLength rowKey
columnFamilyLength 1 表示列族名称所占的字节数
columnFamily columnFamilyLength 列族名称
columnName columnNameLength 列名
timestamp 8 时间戳
type 1 Key类型,比如是新增(Put),还是删除(Delete)
value valueLength 列值
--------------------------------------------------------------------
表2.1
keyLength和valueLength组成头部,
rowKeyLength到type这7项组成Key,最后一项value代表第三部份: Value,
上面有个地方值得注意,在columnFamily前面有columnFamilyLength,
但是在columnName之前并没有columnNameLength这一项,为了节省空间,这不是必需的,
当在解析KeyValue时,通过keyLength-8(timestamp)-1(type)就可以确定columnName在此KeyValue中的结束位置。
把表1.2中的前两行按表2.1中的格式生成两个KeyValue:
KeyValue A 代表: <zhh2009, 用户基本信息, 职业 => 码农>
KeyValue B 代表: <zhh2009, 用户基本信息, 性别 => 男>
- 名称 字节数 KeyValue A KeyValue B
- ----------------------------------------------------------------------------
- keyLength 4 35 35
- valueLength 4 4 2
- rowKeyLength 2 7 7
- rowKey rowKeyLength zhh2009 zhh2009
- columnFamilyLength 1 12 12
- columnFamily columnFamilyLength 用户基本信息 用户基本信息
- columnName columnNameLength 职业 性别
- timestamp 8 1329663787364 1329663787364
- type 1 4(Put) 4(Put)
- value valueLength 码农 男
- ----------------------------------------------------------------------------
- 表2.2
名称 字节数 KeyValue A KeyValue B
----------------------------------------------------------------------------
keyLength 4 35 35
valueLength 4 4 2
rowKeyLength 2 7 7
rowKey rowKeyLength zhh2009 zhh2009
columnFamilyLength 1 12 12
columnFamily columnFamilyLength 用户基本信息 用户基本信息
columnName columnNameLength 职业 性别
timestamp 8 1329663787364 1329663787364
type 1 4(Put) 4(Put)
value valueLength 码农 男
----------------------------------------------------------------------------
表2.2
(注: 在表2.2中,假设中文占两个字节,
1329663787364 对应的时间是Sun Feb 19 23:03:07 CST 2012,
keyLength = 2+7+1+12+4+8+1 = 35)
观察表2.2的最后两列,发现两者大多数都是相同的,
如果把每个这样的KeyValue放到内存或者硬盘中,肯定会浪费大量的空间,
为了解决这些问题,从HBase 0.94开始引入了一种称之为前缀压缩(prefix compression)的算法。
======================================
两篇讲演文章地址:、
http://news.csdn.net/a/20120523/2805878.html?bsh_bid=95993132
http://news.csdn.net/a/20120523/2805879.html?bsh_bid=95996832