存储系统实现-跳跃表实现索引检索
这一篇是我所实现的一个通过跳跃表的方式来实现对索引的检索。大概看了下跳跃表的基本思想,遂用自己的程序来实现这样一种检索方式。
先用一张流程图来阐述我检索的步骤。顾名思义“跳跃表”就是利用跳跃读取的优势,而不用遍历整个索引表造成性能的损失。
读索引整体流程图:
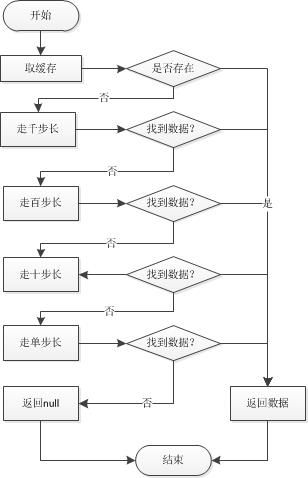
这里举一个例子具体的说一下检索的步骤,这里说一种检索到的情况,这里假设整个文件表10万条,id是连续自增,检索id=2312的值
第一步:走缓存(这里是第一次检索肯定不能命中缓存)
第二步:走千步长
1)id=1000,小于2312,继续
2)id=2000,小于2312,继续
3) id=3000,大于2312,回退到id=2000的值
第三步:走百步长
1)id=2100,小于2312,继续
2)id=2200,小于2312,继续
3)id=2300,小于2312,继续
4)id=2400,大于2312,回退到id=2300的值
第四步:走十步长
1)id=2310,小于2312,继续
2)id=2320,大于2312,回退到id=2310的值
第五步:走单步长
1)id=2311,小于2312,继续
2)id=2312,等于2312,定位到该值,返回数据
从这里可以看出检索这样一个值,最多只需要11步,如果缓存命中的话只需要一步就找到值,而如果顺序检索的话则需要2312步才能检索到值,这样检索性能得到极大的提升。
下面把两代码代码给贴出来。
/**
* 先走一级步长,如果id>key,回退,走二级步长,id>key,一步一步走
*
* @param id
* @return
*/
public synchronized DataOffset read(int id) {
DataOffset offset = getPosFromCache(id);
if(offset!=null){
return offset;
}
long len;
try {
len = reader.length();
//如果长度大于两倍一级步长,先走一级步长
int key = goByStepLevel(len, 0, id, 0, stepLevel_1000);
if (key != 0) {
key = goByStepLevel(len, reader.getFilePointer(), id, 0, stepLevel_100);
if (key != 0) {
key = goByStepLevel(len, reader.getFilePointer(), id, 0, stepLevel_10);
if (key != 0) {
//直接走0级步长
System.out.println("[IndexFileReader.read]key="+key);
key = goByStepLevel(len, reader.getFilePointer(), id, 0, skip);
}
}
}
System.out.println("[IndexFileReader.read]key2="+key);
if (key == 0) {
//拿到偏移量
reader.readInt();
offset = new DataOffset();
offset.setStartPos(reader.readLong());
//offset.setEndPos(reader.readLong());
//byte[] bytes = ByteUtil.longToByte(offset.getStartPos(),offset.getEndPos());
lruCache.put(indexPath + id, offset.getStartPos());
return offset;
}
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
这个方法是一个私有方法,是一个递归方法,走步长的时候通过递归走步长
/**
* @param len
* @param nowStep
* @param id
* @param key
* @param stepLevel
* @return 1:代表值还在后面,0:代表该节点即为值,-1:值在前面
* @throws IOException
*/
private int goByStepLevel(long len, long nowStep, int id, int key, long stepLevel)
throws IOException {
//如果后面的步骤已经小于一级步长
if (len > nowStep + stepLevel) {
//如果值仍然在后面,走一级步长
if (id > key) {
nowStep = nowStep + stepLevel;
reader.seek(nowStep);
//这里已经读出一个值了,需要回退
key = reader.readInt();
return goByStepLevel(len, nowStep, id, key, stepLevel);
} else if (id < key) {
//退出,走二级步长
reader.seek(nowStep - stepLevel);
return 1;
} else {
//相等,找到值直接定位到该值
reader.seek(nowStep);
return 0;
}
} else {
//如果值仍然在后面,走二级步长
if (id > key) {
reader.seek(nowStep);
return -1;
} else if (id < key) {
long preStep = nowStep - stepLevel;
if (preStep > 0) {
reader.seek(preStep);
} else {
//如果小于,则直接归0,走二级步长
reader.seek(0);
}
return 1;
} else {
//相等,如果找到值,直接seek到该偏移
reader.seek(nowStep);
return 0;
}
}
}
总结:这里跳跃表的实现就写完了。欢迎大家拍砖