搜索引擎–Python下的分词插件 jieba 结巴分词
主机平台:Ubuntu 13.04
Python版本:2.7.4
jieba分词满足了Pyhon下对高效率高准确率进行中文分词的要求,是一款很不错的开源分词组建。并且支持繁体字和自定义短语以提高分词的准确性。
分词支持三种模式:
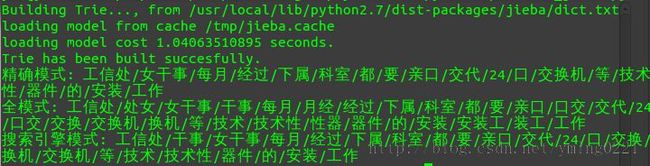
a,精确模式,试图将句子最精确地切开,适合文本分析;
b,全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
c,搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
b,全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
c,搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
结巴分词组建的安装:
git clone https://github.com/fxsjy/jieba.git
cd jieba
python setup.py build
python setup.py install
调用接口:
- 组件只提供jieba.cut 方法用于分词
- cut方法接受两个输入参数:
- 1) 第一个参数为需要分词的字符串
- 2) cut_all参数用来控制分词模式
- 待分词的字符串可以是gbk字符串、utf-8字符串或者unicode
- jieba.cut返回的结构是一个可迭代的generator,可以使用for循环来获得分词后得到的每一个词语(unicode),也可以用list(jieba.cut(…))转化为list
Python的使用实例:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import jieba
text = ‘工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作’
default_mode = jieba.cut(text)
full_mode = jieba.cut(text,cut_all=True)
search_mode = jieba.cut_for_search(text)
print “精确模式:”,”/”.join(default_mode)
print “全模式:”,”/”.join(full_mode)
print “搜索引擎模式:”,”/”.join(search_mode)
分词结果执行如下: