汇编与高级语言
汇编与高级语言
1. 汇编基础知识
1.1. 寄存器
| 寄存器 |
用途 |
| EAX,EBX,EDX,ECX |
通用寄存器,由程序员自己指定用途,也有一些不成文的用法: EAX:常用于运算。 EBX:常用于地址索引。 ECX:常用于计数。 EDX:常用于数据传递。 |
| EIP |
指令寄存器,指出当前指令所在的地址。 |
| ESP |
栈指针,指向当前线程的栈顶。 |
| EBP |
栈基址指针,对调试起着很重要的作用。 |
| EDI,ESI |
没有规定作什么用,一般用在源指针和目标指针的操作。 |
| FR |
标志寄存器,由多个标志位组成,存放运算结果的标志,比如借位,进位,是否为0等等。 |
| FS |
在Windows中,FS:[0]用来指向异常处理机制的链接头。 |
说明:
l ESP和EBP对高级语言的函数实现起着非常重要的作用。
l FS是SEH(Structured Exception Handling)中起重要作用的一个段寄存器,它的0偏移指向异常结构连表的表头,Windows在进行结构化异常处理时,就是从FS:[0]开始遍历异常结构并调用其中的异常处理函数的。
1.2. 堆栈
堆是一块内存区域,一般用于内存的动态分配和释放,比如用New方法分配一个指针,此时即在程序地址空间的堆中分配了一块内存。又比如Delphi的对象也是在堆中创建的。
栈是一种先进后出的列表数据结构,在高级语言的编程中使用广泛,在低级语言中更是不可或缺的基础概念。栈也是一个内存区域,不过它具有快速灵活的特点,CPU直接提供指令去访问栈。
从汇编的角度来看,栈具有如下的性质:
l 栈有两个基础动作,压栈(PUSH)和出栈(POP)。
l 栈是向下增长的,即每压一次栈,栈顶的地址就减少一次,也可以说ESP的值就减小一次。
l 栈是线程相关的,每一个线程都拥有一个栈。
l 程序利用ESP可以很灵活地访问栈,不一定要执行PUSH和POP栈顶才会改变,直接操作ESP也可以改变栈顶,也就是说ESP决定了栈顶的值。
l 栈是有最大值的,通过编程环境可以设置,超出最大值就会发生栈溢出。
看一个简单的例子,下面的指令是一条压栈指令,意思是将EAX的值压入栈中:
PUSH EAX
根据上面的性质,这条指令等价于下面的指令:
SUB ESP, 4
MOV ESP, EAX
用下面的图表示指令的操作过程:


2. 调用规则
2.1. 从汇编的角度看函数调用
汇编语言没有变量的概念,因此对函数的调用,第一个要解决的问题是参数要如何传递,有的将参数放在栈中,有的将参数放在寄存器中,对于参数压栈的还要确定是从最左边的参数开始压栈,还是从最右边开始,所有这些,就构成了调用规则的内容。
第二个问题是函数如何被调用,其实很简单,就是一个跳转指令JMP,跳到函数的首地址去,并从那里开始执行指令。
比如下面的代码:
C := Add(10, 20);
按照上面的讨论,汇编代码应该如下:
MOV EAX, 10
MOV EDX, 20
JMP @Add
现在我们又遇到另一个问题:函数执行完后如何返回?在调用Add函数时,执行点跳到函数里面去,但当函数执行完之后,执行点必须返回到C:=Add(10, 20)下面的语句,可是此时已经没有办法得到那个指令地址。为了解决这个问题,必须把 C := Add(10, 20)之后的指令地址保存起来,一般压到栈中是比较好的做法,汇编代码成了下面的样子:
MOV EAX, 10
MOV EDX, 20
PUSH [EIP + Len]
JMP @Add
[EIP +LEN]就是JMP @Add的下一条指令的地址,现在当Add函数执行完毕后,只要在栈中找到这个地址,执行点就可以回来了。大概有人觉得函数调用实在是很常用的事情,于是干脆把最后两条指令合成一条,变成了Call,所以最后的汇编代码如下:
MOV EAX, 10
MOV EDX, 20
CALL @Add
接下来看看Add函数,函数执行完后怎么在栈中找到返回地址?解决这个问题的关键点就是栈平衡,不管函数对栈如何操作,但一定要保证在函数退出时栈现场和刚进来时的一样,这里包括栈顶和栈的内容一样。只要做到这一点,就可以确定在函数将返回时的栈顶值就是正确的返回值,我们只需要从栈顶弹出这个值,再执行一个跳转就行了。
假设它的代码是这样:
Function Add(a, b: Integer): Integer;
begin
Result := a + b;
end;
那么汇编代码就是这样:
ADD EAX, EDX
POP EDX
JMP EDX
同样后两个指令太常用了,因此合成一条,成了Ret,最后的汇编代码是这样的:
ADD EAX, EDX
RET
从汇编角度函数调用大概就是如此。
2.2. 调用规则
调用规则讨论的是函数的参数怎么传递,函数结果又是怎么返回,另外栈平衡由谁负责(函数本身或调用者)。下面就介绍几个比较常用的调用规则:
Register
Delphi默认的调用规则,效率非常高,但规则很复杂,下面是它的简要规则:
1. 头三个不大于4个字节(DWORD)的参数从左到右的传入EAX,EDX,ECX寄存器;接下去的参数按从左到右压栈。
比如函数:function Add1(I1: Byte; I2: Int64; I3: Integer; I4: Integer; I5: Integer): Integer;
用汇编来调用就是这样的:
var
I: Integer;
begin
//I := Add1(10, 20, 30, 40, 50);
asm
mov al, 10
push 0
push 20
mov edx, 30
mov ecx, 40
push 50
call Add1
mov I, eax
end;
end;
2. 浮点数总压栈,不管它所占的字节是多少。
3. 对象方法总是有一个Self隐含参数,这个参数在所有的参数前面,即总是传给EAX。
比如一个类中有一个方法:function Add2(a, b: Integer): Integer;
用汇编调用如下所示:
var
I: Integer;
begin
//I := Add2(10, 20);
asm
mov eax, Self
mov edx, 10
mov ecx, 20
call Add2
mov I, eax
end;
end;
4. 栈现场必须由函数自己清理。
Stdcall
Windows API的标准调用规则,效率不高,但规则很简单:
1. 参数总是从右向左地压栈。
比如,对于函数:function Add3(a, b: Integer): Integer; stdcall;
下在是调用的代码:
var
I: Integer;
begin
//I := Add3(10, 20);
asm
push 20
push 10
call Add3
mov I, eax
end;
end;
2. 栈现场必须由函数自己清理。
Cdecl
这是C语言的标准调用规则,在Delphi中很少需要用到这种规则,但Delphi仍然提供了支持。
1. 与stdcall类似,参数总是从右向左地压栈。
2. 栈现场必须由调用者清理。
这就为可变参数提供了可能,举一个例子,C语言里面有一个运行时函数叫Sprintf,类似于Delphi的Format,C的声明如下:
int sprintf( char *buffer, const char *format [, argument] ... );
用Delphi的声明则是这样的:
function sprintf(buffer: PChar; const format: PChar): Integer; cdecl; varargs; external 'msvcrt.dll' name 'sprintf';
用Delphi可以这样调用:
var
S: string;
begin
SetLength(S, 30);
sprintf(PChar(S), '%s and %s are good friends', 'tom', 'jacky');
ShowMessage(S);
end;
是不是很神奇,函数声明明明只有两个参数,但调用的时候却可以传入任意多的参数,对函数本身来说,它并不知道参数有多少,因此是无法清理栈现场的,只有调用者知道有多少个参数,所以栈现场由调用者清理,下面是调用这个函数的汇编代码:
//sprintf(PChar(S), '%s and %s are good friends', 'tom', 'jacky');
push $00453d00
push $00453d10
push $00453d14
mov eax,[ebp-$04]
call @LStrToPChar
push eax
call sprintf
add esp,$10
Safecall
Safecall常用于COM,Delphi作了很多处理,使得函数返回值小于0时,自动抛出异常。
1. 任何Safecall函数,都可以转换成等价的Stdcall函数。
例1:
procedure Proc(); safecall;
Function Proc(): HResult; stdcall;
例 2:
Function func(): Integer; safecall;
Function func(out Re: Integer): HResult; stdcall;
问题:假设有一个Safecall的函数:function Add4(a, b: Integer): Integer; safecall;如何用汇编代码调用之?
1) 首先是将其转换成StdCall的声明:
function Add4(a, b: Integer; out Re: Integer): HRESULT; stdcall;
2) 按照Stdcall的调用规则调用:
var
I: Integer;
begin
//I := Add4(10, 20);
asm
lea eax, I
push eax
push 20
push 10
call Add4
end;
end;
2. 函数返回时,Delphi自动检查其返回值,如果小于0,就引发reSafeCallError异常。
比如I := Add4(10, 20)这一句,实际的汇编代码是这样的:
lea eax,[ebp-$04]
Push eax
push $14
push $0a
call Add4
call @CheckAutoResult
CheckAutoResult是System单元的一个RTL函数,负责检查函数的返回结果:
function _CheckAutoResult(ResultCode: HResult): HResult;
begin
if ResultCode < 0 then
begin
if Assigned(SafeCallErrorProc) then
SafeCallErrorProc(ResultCode, Pointer(-1)); // loses error address
Error(reSafeCallError);
end;
Result := ResultCode;
end;
3. 栈框架(Stack Frame)
Stack Frame是一项非常有用的技术,特别是对于高级语言,可以说,如果没有Stack Frame,就没有Call Stack。
函数一般都有如下的汇编代码框架
begin
push ebp
mov ebp,esp
... ...
mov esp,ebp
pop ebp
end;
在调用push ebp,mov ebp, esp之后,栈的现场是这样的:

由此可知,对于每一个函数,EBP总是指向函数进入时的栈顶,那么上图中的“EBP的前一个值”应该就是调用该函数的上一级函数进入时的栈顶了,依此类推,最终将形成下面的图示:

上图实际上就形成了一个链表的结构,用下面的记录来表示:
PStackFrame = ^TStackFrame
TStackFrame = Record
Prev: PStackFrame;
CallerAddr: Pointer;
end;
也就是说,函数调用的同时也在增加这个栈框架链表。举一个例子,假设有A,B,C三个函数,A调用B,B调用C,则最终的栈框架链表如下图所示:

利用栈框架就可以实现调试里面的Call Stack。原理很简单,只要遍历StackFrame链表,根据CallerAddr获得每一个函数名。
下面是第一个例子,遍历StackFrame链表,并取出每一个CallerAddr:
procedure OutputCallStack(CallStackProc: TCallStackProc1); overload;
var
StackFrame: PStackFrame;
i: Integer;
begin
asm
MOV StackFrame, EBP
end;
if Assigned(CallStackProc) then
begin
i := 0;
while i < 10 do
begin
Inc(i);
CallStackProc(StackFrame^.CallerAddr);
StackFrame := StackFrame^.Prev;
end;
end;
end;
如果想获得每一个调用函数的详细信息,需要调试符号的帮助,下面一个例子利用生成的Map文件,也可以获得一些函数信息(需要JCLDebug的支持):
procedure OutputCallStack(CallStackProc: TCallStackProc2); overload;
var
StackFrame: PStackFrame;
ProcName, UnitName: string;
Line: Integer;
begin
asm
MOV StackFrame, EBP
end;
if Assigned(CallStackProc) then
while True do
begin
ProcName := ProcOfAddr(StackFrame^.CallerAddr);
UnitName := ModuleOfAddr(StackFrame^.CallerAddr);
Line := LineOfAddr(StackFrame^.CallerAddr);
if UnitName <> '' then
CallStackProc(StackFrame^.CallerAddr, UnitName, ProcName, Line)
else
Break;
StackFrame := PStackFrame(StackFrame^.Prev);
end;
end;
4. Move函数比较
我例出了四个Move函数的运行比较,旨在说明即使是汇编也有很大的速度差异。
System.Move请到System单元下查看;FastCode.Move到http://fastcode.sourceforge.net/下载,下面是MyMove_Assembly和MyMove_pascal的实现代码:
procedure MyMove_Pascal(const Source; var Dest; Count: Integer);
var
S, D: PChar;
I: Integer;
begin
S := PChar(@Source);
D := PChar(@Dest);
if S = D then Exit;
if Cardinal(D) > Cardinal(S) then
for I := count-1 downto 0 do
D[I] := S[I]
else
for I := 0 to count-1 do
D[I] := S[I];
end;
procedure MyMove_Assembly(const Source; var Dest; Count: Integer);
asm
{ EAX Pointer to source }
{ EDX Pointer to destination }
{ ECX Count }
CMP EAX, EDX
JZ @endProc
PUSH EDI
PUSH ESI
PUSH ECX
CMP EAX, EDX
JL @DownLoop
@UpLoop:
MOV ESI, EAX
MOV EDI, EDX
REP MOVSB
JMP @exit
@DownLoop:
LEA ESI, [EAX + ECX - 1]
LEA EDI, [EDX + ECX - 1]
STD
REP MOVSB
CLD
@exit:
POP ECX
POP ESI
POP EDI
@endProc:
end;
下面是运行结果的比较:
i. 未钩选优化指令的情况:
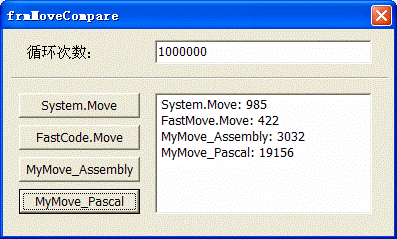
ii. 钩选优化指令的情况:
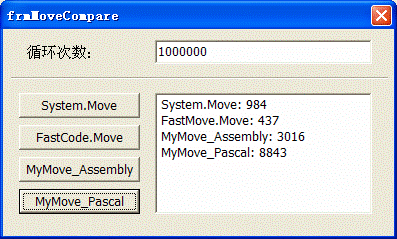
根据上面的结果,我得出了下面的结论,并有下面的建议。
结论:
① 未优化的Pascal代码与优化的汇编代码效率相差为45倍。
② 优化的Pascal代码与优化的汇编代码效率相差为20倍。
③ 优化的Pascal代码与未优化的汇编代码效率相差为2.9位。
④ 未优化的汇编代码与优化的汇编效率相差为7倍。
建议:
① 对于应用程序员来说,除非遇到效率要求非常高的地方,否则尽量不要写汇编代码,因为经过优化的高级语言效率已经非常高。
② 理解汇编与高级语言的关系,能够通过查看汇编代码解决困难的问题。