Spark历险记之编译和远程任务提交
Spark简介
Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处,Spark以其先进的设计理念,迅速成为社区的热门项目,围绕着Spark推出了Spark SQL、Spark Streaming、MLLib和GraphX等组件,也就是BDAS(伯克利数据分析栈),这些组件逐渐形成大数据处理一站式解决平台。从各方面报道来看Spark抱负并非池鱼,而是希望替代Hadoop在大数据中的地位,成为大数据处理的主流标准,不过Spark还没有太多大项目的检验,离这个目标还有很大路要走。
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松地操作分布式数据集(Scala 提供一个称为 Actor 的并行模型,其中Actor通过它的收件箱来发送和接收非同步信息而不是共享数据,该方式被称为:Shared Nothing 模型)。在Spark官网上介绍,它具有运行速度快、易用性好、通用性强和随处运行等特点。
环境介绍
这里Hadoop已经安装完毕,并且能正常工作,Spark可以运行在Standalone模式上,所以假如你没有Hadoop环境,当然也是可以使用的。
1,下载scala :
wget http://downloads.typesafe.com/scala/2.11.7/scala-2.11.7.tgz?_ga=1.103717955.215870088.1434449855
2, 安装scala , 解压到某个目录,并加入环境变量
export SCALA_HOME=/ROOT/server/scala
export PATH=$PATH:$SCALA_HOME/bin
3,下载spark,这里推荐下载spark源码,自己编译所需对应的hadoop版本,虽然spark官网也提供了二进制的包!
http://spark.apache.org/downloads.html
4,编译spark
这里需要注意,默认的spark编译,使用的是scala2.10的版本,一定要确保你所有使用的scala在大版本2.10.x范围内一致,否则在某些情况下可能会出现莫名其妙的问题。
我这里用的是spark1.4.0的版本,所以只能用scala2.11.x的版本,这就需要重新编译spark了,另一个原因也需要和对应的haodop版本编译对应。
编译步骤
(1)将下载好的spark源码解压到某个目录下
(2)进入源码目录,分别执行如下命令
设置使用scala那个版本编译
dev/change-version-to-2.11.sh
maven打包,指定hadoop版本和scala版本
mvn -Pyarn -Phadoop-2.6 -Dscala-2.11 -DskipTests clean package
大概半小时候可编译成功

5,安装spark
请参考散仙以前的文章:http://qindongliang.iteye.com/blog/2224797
6,spark测试的几个命令:
7,远程任务提交
Spark集群一般都会部署在Linux上,而我们开发一般都会在windows上,那么我们想调试Spark程序,应该怎么做?
大多数的情况下,你都需要把你的程序打包成一个jar,然后上传到Linux上,然后在执行测试,这样非常麻烦,你频繁改代码
就意味着,你得不断的打包,上传,打包,上传,这跟hadoop的调试是一样的。
更简洁的方式,就是直接在编译器(这里推荐Intellj IDEA)里,开发,然后打包,直接在IDEA里以编程方式提交spark任务,这样在开发期间相对就比较很高效了。
如何打包构建一个spark应用的程序 ?
(1)安装使用maven 下载地址 https://maven.apache.org/
(2)安装使用sbt 下载地址 http://www.scala-sbt.org/
这里推荐用sbt,专门针对scala项目的进行构建打包的
好吧,也许你需要一个demo来帮助你理解?
在IDEA中,创建一个Scala的SBT项目:
然后在build.sbt文件中,加入如下依赖:
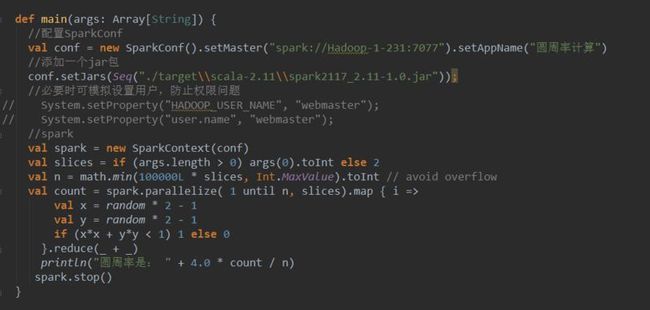
一段简单的代码:
然后直接运行就能直接在windows上提交任务到Linux上的spark集群了
IDEA的控制台里会打印计算结果:

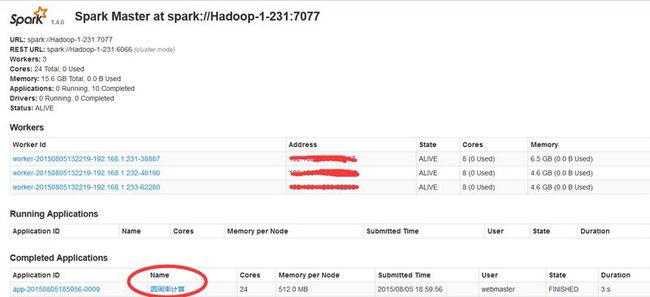
在Spark的8080监控页面显示如下:
8,遇到的问题:
IDEA里警告日志显示:
Spark集群的Master机器的master的log日志显示:
服务器上log是准确的,它告诉我们有客户端和服务端的序列化版本不一致,意思就是说,你的scala或者是hadoop的版本等跟服务器上的可能不一致,所以安装时务必要确定所有的软件版本号一致。
这个问题,我在stackoverflow上提问了2天,都没人知道,最后各种疯狂的找资料才发现就是软件版本不一致导致的,真是大意失荆州了,解铃还须系铃人!
最后欢迎大家扫码关注微信公众号:我是攻城师(woshigcs),我们一起学习,进步和交流!(woshigcs)
本公众号的内容是有关搜索和大数据技术和互联网等方面内容的分享,也是一个温馨的技术互动交流的小家园,有什么问题随时都可以留言,欢迎大家来访!

Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处,Spark以其先进的设计理念,迅速成为社区的热门项目,围绕着Spark推出了Spark SQL、Spark Streaming、MLLib和GraphX等组件,也就是BDAS(伯克利数据分析栈),这些组件逐渐形成大数据处理一站式解决平台。从各方面报道来看Spark抱负并非池鱼,而是希望替代Hadoop在大数据中的地位,成为大数据处理的主流标准,不过Spark还没有太多大项目的检验,离这个目标还有很大路要走。
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松地操作分布式数据集(Scala 提供一个称为 Actor 的并行模型,其中Actor通过它的收件箱来发送和接收非同步信息而不是共享数据,该方式被称为:Shared Nothing 模型)。在Spark官网上介绍,它具有运行速度快、易用性好、通用性强和随处运行等特点。
环境介绍
| 序号 | 应用 | 说明 |
| 1 | CDH Hadoop2.6 | 如果想跑在hadoop上,则需要安装 |
| 2 | JDK7 | 底层依赖 |
| 3 | Scala2.11.7 | 底层依赖 |
| 4 | Maven3.3.3 | 构建编译打包 |
| 5 | Ant1.9.5 | 构建编译打包 |
| 6 | Spark1.4.0 | 主角 |
| 7 | Intillj IDEA | 开发IDE |
| 8 | SBT | scala-spark专属打包构建工具 |
| 9 | Centos6或Centos7 | 集群运行的Linux系统 |
这里Hadoop已经安装完毕,并且能正常工作,Spark可以运行在Standalone模式上,所以假如你没有Hadoop环境,当然也是可以使用的。
1,下载scala :
wget http://downloads.typesafe.com/scala/2.11.7/scala-2.11.7.tgz?_ga=1.103717955.215870088.1434449855
2, 安装scala , 解压到某个目录,并加入环境变量
export SCALA_HOME=/ROOT/server/scala
export PATH=$PATH:$SCALA_HOME/bin
3,下载spark,这里推荐下载spark源码,自己编译所需对应的hadoop版本,虽然spark官网也提供了二进制的包!
http://spark.apache.org/downloads.html
4,编译spark
这里需要注意,默认的spark编译,使用的是scala2.10的版本,一定要确保你所有使用的scala在大版本2.10.x范围内一致,否则在某些情况下可能会出现莫名其妙的问题。
我这里用的是spark1.4.0的版本,所以只能用scala2.11.x的版本,这就需要重新编译spark了,另一个原因也需要和对应的haodop版本编译对应。
编译步骤
(1)将下载好的spark源码解压到某个目录下
(2)进入源码目录,分别执行如下命令
设置使用scala那个版本编译
dev/change-version-to-2.11.sh
maven打包,指定hadoop版本和scala版本
mvn -Pyarn -Phadoop-2.6 -Dscala-2.11 -DskipTests clean package
大概半小时候可编译成功
5,安装spark
请参考散仙以前的文章:http://qindongliang.iteye.com/blog/2224797
6,spark测试的几个命令:
standlone模式 bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://Hadoop-1-231:7077 examples/target/spark-examples_2.11-1.4.0.jar 100 yarn-cluster模式cluster bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster examples/target/spark-examples_2.11-1.4.0.jar 100 yarn-client模式cluster bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client examples/target/spark-examples_2.11-1.4.0.jar 100
7,远程任务提交
Spark集群一般都会部署在Linux上,而我们开发一般都会在windows上,那么我们想调试Spark程序,应该怎么做?
大多数的情况下,你都需要把你的程序打包成一个jar,然后上传到Linux上,然后在执行测试,这样非常麻烦,你频繁改代码
就意味着,你得不断的打包,上传,打包,上传,这跟hadoop的调试是一样的。
更简洁的方式,就是直接在编译器(这里推荐Intellj IDEA)里,开发,然后打包,直接在IDEA里以编程方式提交spark任务,这样在开发期间相对就比较很高效了。
如何打包构建一个spark应用的程序 ?
(1)安装使用maven 下载地址 https://maven.apache.org/
(2)安装使用sbt 下载地址 http://www.scala-sbt.org/
这里推荐用sbt,专门针对scala项目的进行构建打包的
好吧,也许你需要一个demo来帮助你理解?
在IDEA中,创建一个Scala的SBT项目:
然后在build.sbt文件中,加入如下依赖:
name := "spark2117" version := "1.0" scalaVersion := "2.11.7" libraryDependencies += "org.apache.hadoop" % "hadoop-client" % "2.6.0" libraryDependencies += "org.apache.spark" % "spark-core_2.11" % "1.4.0" libraryDependencies += "javax.servlet" % "javax.servlet-api" % "3.0.1"
一段简单的代码:
然后直接运行就能直接在windows上提交任务到Linux上的spark集群了
IDEA的控制台里会打印计算结果:
在Spark的8080监控页面显示如下:
8,遇到的问题:
IDEA里警告日志显示:
15/08/04 19:33:09 WARN ReliableDeliverySupervisor: Association with remote system [akka.tcp://sparkMaster@h1:7077] has failed, address is now gated for [5000] ms. Reason is: [Disassociated].
Spark集群的Master机器的master的log日志显示:
java.io.InvalidClassException: scala.reflect.ClassTag$$anon$1; local class incompatible: stream classdesc serialVersionUID = -4937928798201944954, local class serialVersionUID = -8102093212602380348
服务器上log是准确的,它告诉我们有客户端和服务端的序列化版本不一致,意思就是说,你的scala或者是hadoop的版本等跟服务器上的可能不一致,所以安装时务必要确定所有的软件版本号一致。
这个问题,我在stackoverflow上提问了2天,都没人知道,最后各种疯狂的找资料才发现就是软件版本不一致导致的,真是大意失荆州了,解铃还须系铃人!
最后欢迎大家扫码关注微信公众号:我是攻城师(woshigcs),我们一起学习,进步和交流!(woshigcs)
本公众号的内容是有关搜索和大数据技术和互联网等方面内容的分享,也是一个温馨的技术互动交流的小家园,有什么问题随时都可以留言,欢迎大家来访!