disruptor调研报告
Disruptor是什么?Disruptor是一个线程间通信的框架,即在多线程间共享数据。它是由LMAX公司开发的可信消息传递架构的一部分,以便用非常快速的方法来在多组件之间传递数据。它的一个核心思想是理解并适应硬件工作方式来达到最优的效果。
在很多(并行) 架构里,普遍使用队列来共享数据(例如传递消息)。图1就是使用队列来传递消息的一个示意图(里面蓝色的小圈圈表示一个线程)。这种架构允许生产线程(图 1里的stage1)在消费线程(图1里的stage2)处理不过来的情况下,还可以继续后面的工作,队列在其中用来做为消息的缓冲区。
 图1
图1
在最简单的情况 下,disruptor可以用来替代图1架构里的队列,也就是线程间通过disruptor来传递数据。在disruptor里保存消息的数据结构是环状 缓冲区(RingBuffer - 后面都用RingBuffer这个术语)。生产线程stage1将消息放到RingBuffer里,然后消费线程stage2从RingBuffer里读 取消息,如图2。
 图2
图2
从图2里可以看到,RingBuffer里的每一个元素都有一个序列号(sequence number)来索引,RingBuffer维护当前最新放置的元素的序列号,这个序列号一直递增,(通过求余来得到元素在RingBuffer下面的数组下标)。
Disruptor的关键特性是无锁编程,这个是通过单一写线程的方式实现的 - 即一块数据永远只有一个线程写入。通过遵循这个编程原则来避免使用昂贵的同步锁或CAS操作,这就是为什么Disruptor这么快的原因。
因为RingBuffer规避了锁,而且每个EventProcessor维护自己的序列号。
向Disruptor发布消息
往RingBuffer里写入消息使用两步提交的方式。首先,生产线程Stage1需要确定RingBuffer里下一个空闲槽,如图3。
 图3
图3
RingBuffer维护了最后一次写入的序列号(图3里的18号),因此就可以推知下一个空闲的槽号。RingBuffer通过检查所有从RingBuffer读取消息的EventProcessor的序列号,以判别下一个槽号是否空闲。
图4演示了索取下一个空闲槽序列号的过程。
 图4
图4
当生产线程拿到了下一个序利号之后,它从RingBuffer里拿到槽里保存的对象并执行任何操作。这个过程中,因为RingBuffer的最新序列号依然是18,因此其它线程无法读取19号槽里面的事件 - 生产线程还在处理它。
 图5
图5
图5演示了RingBuffer在提交变更后的情况。当生产线程处理完第19号槽的数据后,它告诉RingBuffer将其公布出来。这个时候,RingBuffer才会更新它维护的序列号,任何等待读取第19号槽里的数据的线程才能读取它。
从RingBuffer里读取信息
Disruptor 框架里提供了一个叫做BatchEventProcessor来从RingBuffer里读取数据。当生产线程向RingBuffer要求下一个可写入的 空闲槽的序列号时,同时一个EventProcessor(类似消费者,但其并消费RingBuffer里的元素 - 即不从RingBuffer里移除任何元素)也会维护其最后所处理的数据的序列号,并要求下一个可处理的数据的序列号。
图6演示了EventProcessor等待处理下一个可读取数据序利号的过程。
 图6
图6
EventProcessor不是直接从RingBuffer里获取下一个可读取数据的序列号,而是通过一个SequenceBarrier对象来做的,稍后我们谈这个细节。
图6 里,EventProcessor(即消费者线程Stage2)最后看到的是第16号槽的数据,它希望处理下一个(第17号)槽的数据,因此它执行 SequenceBarrier的waitFor(17)函数调用。线程Stage2可以一直等待下一个可读序列号,因为如果尚没有数据生产出来的话,它 什么也不需要做。但跟图6所示的一样,RingBuffer里最新可用数据已经到18号槽了,因此waitFor返回18,即告诉 EventProcessor可以一直读到第18号的所有数据。如图7。
 图7
图7
这种模式提供了很好的批处理行为,可以使用这种批处理代码来实现EventHandler,在Disruptor里性能测试FizzBuzzEventHandler就是一个很好的例子。
处理系统组件之间的依赖关系
Disruptor 处理系统内部多组件的依赖关系,而不引入任何线程竞争的做法很有意思。Disruptor遵循的是单线程写入,多线程读取的做法。Disruptor的原 始设计是支持几步具有特定顺序的串行流水线操作 - 这种操作在企业级的系统里很常见。图8演了一个标准的三步流水线操作:
 图8
图8
首先,所有事件都会写入硬盘(日志“Journaling”操作),以便容灾恢复。第二所有事件会备份(Replication操作)到第二台服务器上,只有这些步骤都完成之后系统才能处理实际的业务操作(Business Logic)。
串行做这三步操作是一个合理的做法,但不是最有效率的。日志和备份操作可以并行,因为它们相互独立。但业务操作不行,因为它依赖前两者,图9演示了这个依赖关系。
 图9
图9
如果使用 Disruptor,前两步(日志和备份)可以直接读RingBuffer。跟图7示意的,它们都使用一个屏障(Sequence Barrier)来得到RingBuffer下一个可读取的序列号。它们各自维护自己的序列号,这样方便它们自己知道已经读到哪了,并使用 BatchEventProcessor来处理事件(日志和备份)。
业务线程也会从同一个RingBuffer里读取事件,不过只能处理前两个线程处理完的事件。这个限制通过第二个SequenceBarrier来实现,它被配置来读取日志线程和备份线程的序列号,返回它们的最小值,以告诉业务线程安全读取的范围。
只有每一个EventProcessor都使用序列号屏障(Sequence Barrier)来确定可以安全处理的事件范围,才能从RingBuffer里读取数据。如图10。
 图10
图10
虽然有很多线程读取不同的序利号,但由于都是简单递增自己内部的序利号,所以线程间没有竞争。
Disruptor术语
github上Disruptor的wiki对Disruptor中的术语进行了解释,在看Disruptor的过程中,对于几个其他的类,觉得有必要与这些术语放到一起,就加进来了。
-
RingBuffer经常被看作Disruptor最主要的组件,然而从3.0开始RingBuffer仅仅负责存储和更新在Disruptor中流通的数据。对一些特殊的使用场景能够被用户(使用其他数据结构)完全替代。 -
SequenceDisruptor使用Sequence来表示一个特殊组件处理的序号。和Disruptor一样,每个消费者(EventProcessor)都维持着 一个Sequence。大部分的并发代码依赖这些Sequence值的运转,因此Sequence支持多种当前AtomicLong类的特性。事实上,这 两者之间唯一的区别是Sequence包含额外的功能来阻止Sequence和其他值之间的共享。 -
Sequencer这是Disruptor真正的核心。实现了这个接口的两种生产者(单生产者和多生产者)均实现了所有的并发算法,为了在生产者和消费者之间进行准确快速的数据传递。 -
SequenceBarrier由Sequencer生成,并且包含了已经发布的Sequence的引用,这些的Sequence源于Sequencer和一些独立的消费者的Sequence。它包含了决定是否有供消费者来消费的Event的逻辑。 - WaitStrategy:它决定了一个消费者将如何等待生产者将Event置入Disruptor。
-
Event从生产者到消费者过程中所处理的数据单元。Disruptor中没有代码表示Event,因为它完全是由用户定义的。 -
EventProcessor主要的事件循环,用于处理Disruptor中的Event,并且拥有消费者的Sequence。它有一个实现类是BatchEventProcessor,包含了event loop有效的实现,并且将回调到一个EventHandler接口的实现对象。 -
EventHandler由用户实现并且代表了Disruptor中的一个消费者的接口。 -
Producer由用户实现,它调用RingBuffer来插入事件(Event),在Disruptor中没有相应的实现代码,由用户实现。 -
WorkProcessor确保每个sequence只被一个processor消费,在同一个WorkPool中的处理多个WorkProcessor不会消费同样的sequence。 -
WorkerPool一个WorkProcessor池,其中WorkProcessor将消费Sequence,所以任务可以在实现WorkHandler接口的worker吃间移交 -
LifecycleAware当BatchEventProcessor启动和停止时,于实现这个接口用于接收通知。
Disruptor印象
初看Disruptor,给人的印象就是RingBuffer是其核心,生产者向RingBuffer中写入元素,消费者从RingBuffer中消费元素,如下图: 
这就是Disruptor最简单的模型。其中的RingBuffer被组织成要给环形队列,但它与我们在常常使用的队列又不一样,这个队列大小固定,且每 个元素槽都以一个整数进行编号,RingBuffer中只有一个游标维护着一个指向下一个可用位置的序号,生产者每次向RingBuffer中写入一个元 素时都需要向RingBuffer申请一个可写入的序列号,如果此时RingBuffer中有可用节点,RingBuffer就向生产者返回这个可用节点 的序号,如果没有,那么就等待。同样消费者消费的元素序号也必须是生产者已经写入了的元素序号。
LMAX Disruptor 是一个开源的并发框架,并获得2011 Duke’s 程序框架创新奖。本文将用图表的方式为大家介绍Disruptor是什么,用来做什么,以及简单介绍背后的实现原理。
Disruptor是什么?
Disruptor 是线程内通信框架,用于线程里共享数据。LMAX 创建Disruptor作为可靠消息架构的一部分并将它设计成一种在不同组件中共享数据非常快的方法。
基于Mechanical Sympathy(对于计算机底层硬件的理解),基本的计算机科学以及领域驱动设计,Disruptor已经发展成为一个帮助开发人员解决很多繁琐并发编程问题的框架。
很多架构都普遍使用一个队列共享线程间的数据(即传送消息)。图1 展示了一个在不同的阶段中通过使用队列来传送消息的例子(每个蓝色的圈代表一个线程)。

图 1
这种架构允许生产者线程(图1中的stage1)在stage2很忙以至于无法立刻处理的时候能够继续执行下一步操作,从而提供了解决系统中数据拥堵的方法。这里队列可以看成是不同线程之间的缓冲。
在这种最简单的情况下,Disruptor 可以用来代替队列作为在不同的线程传递消息的工具(如图2所示)。

图2
这种数据结构叫着RingBuffer,是用数组实现的。Stage1线程把数据放进RingBuffer,而Stage2线程从RingBuffer中读取数据。
图2 中,可以看到RingBuffer中每格中都有序号,并且RingBuffer实时监测值最大(最新)的序号,该序号指向RingBuffer中最后一格。序号会伴随着越来越多的数据增加进RingBuffer中而增长。
Disruptor的关键在于是它的设计目标是在框架内没有竞争.这是通过遵守single-writer 原则,即只有一块数据可以写入一个数据块中,而达到的。遵循这样的规则使得Disruptor避免了代价高昂的CAS锁,这也使得Disruptor非常快。
Disruptor通过使用RingBuffer以及每个事件处理器(EventProcessor)监测各自的序号从而减少了竞争。这样,事件处理器只能更新自己所获得的序号。当介绍向RingBuffer读取和写入数据时会对这个概念作进一步阐述。
发布到Disruptor
向RingBuffer写入数据需要通过两阶段提交(two-phase commit)。首先,Stage1线程即发布者必须确定RingBuffer中下一个可以插入的格,如图3所示。

图 3
RingBuffer持有最近写入格的序号(图3中的18格),从而确定下一个插入格的序号。
RingBuffer通过检查所有事件处理器正在从RingBuffer中读取的当前序号来判断下一个插入格是否空闲。
图4显示发现了下一个插入格。
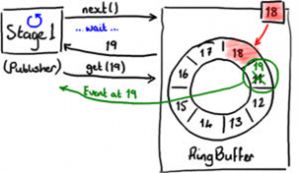
图 4
当发布者得到下一个序号后,它可以获得该格中的对象,并可以对该对象进行任意操作。你可以把格想象成一个简单的可以写入任意值的容器。
同时,在发布者处理19格数据的时候,RingBuffer的序号依然是18,所以其他事件处理器将不会读到19格中的数据。
图5表示对象的改动保存进了RingBuffer。

图5
最终,发布者最终将数据写入19格后,通知RingBuffer发布19格的数据。这时,RingBuffer更新序号并且所有从RingBuffer读数据的事件处理器都可以看到19格中的数据。
RingBuffer中数据读取
Disruptor框架中包含了可以从RingBuffer中读取数据的BatchEventProcessor,下面将概述它如何工作并着重介绍它的设计。
当发布者向RingBuffer请求下一个空格以便写入时,一个实际上并不真的从RingBuffer消费事件的事件处理器,将监控它处理的最新的序号并请求它所需要的下一个序号。
图5显示事件处理器等待下一个序号。

图6
事件处理器不是直接向RingBuffer请求序号,而是通过SequenceBarrier向RingBuffer请求序号。其中具体实现细节对我们的理解并不重要,但是下面可以看到这样做的目的很明显。
如图6中Stage2所示,事件处理器的最大序号是16.它向SequenceBarrier调用waitFor(17)以获得17格中的数据。因 为没有数据写入RingBuffer,Stage2事件处理器挂起等待下一个序号。如果这样,没有什么可以处理。但是,如图6所示的情 况,RingBuffer已经被填充到18格,所以waitFor函数将返回18并通知事件处理器,它可以读取包括直到18格在内的数据,如图7所示。

图7
这种方法提供了非常好的批处理功能,可以在BatchEventProcessor源码中看到。源码中直接向RingBuffer批量获取从下一个序号直到最大可以获得的序号中的数据。
你可以通过实现EventHandler使用批处理功能。在Disruptor性能测试中有关于如何使用批处理的例子,例如FizzBuzzEventHandler。
是低延迟队列?
当然,Disruptor可以被当作低延迟队列来使用。我们对于Disruptor之前版本的测试数据显示了,运行在一个2.2 GHz的英特尔酷睿i7-2720QM处理器上使用Java 1.6.0_25 64位的Ubuntu的11.04三层管道模式架构中,Disruptor比ArrayBlockingQueue快了多少。表1显示了在管道中的每跳延 迟。有关此测试的更多详细信息,请参阅Disruptor技术文件。
但是不要根据延迟数据得出Disruptor只是一种解决某种特定性能问题的方案,因为它不是。
更酷的东西
一个有意思的事是Disruptor是如何支持系统组件之间的依赖关系,并在线程之间共享数据时不产生竞争。
Disruptor在设计上遵守single-writer 原则从而实现零竞争,即每个数据位只能被一个线程写入。但是,这不代表你不可以使用多个线程读数据,而这正是Disruptor所支持的。
Disruptor系统的最初设计是为了支持需要按照特定的顺序发生的阶段性类似流水线事件,这种需求在企业应用系统开发中并不少见。图8显示了标准的3级流水线。
![]()
图 8
首先,每个事件都被写入硬盘(日志)作为日后恢复用。其次,这些事件被复制到备份服务器。只有在这两个阶段后,系统开始业务逻辑处理。
按顺序执行上次操作是一个合乎逻辑的方法,但是并不是最有效的方法。日志和复制操作可以同步执行,因为他们互相独立。但是业务逻辑必须在他们都执行完后才能执行。图9显示他们可以并行互不依赖。

图 9
如果使用Disruptor,前两个阶段(日志和复制)可以直接从RingBuffer中读取数据。正如图7种的简化图所示,他们都使用一个单一的 Sequence Barrier从RingBuffer获取下一个可用的序号。他们记录他们使用过的序号,这样他们知道那些事件已经读过并可以使用 BatchEventProcessor批量获取事件。
业务逻辑同样可以从同一个RingBuffer中读取事件,但是只限于前两个阶段已经处理过事件。这是通过加入第二个SequenceBarrier实现的,用它来监控处理日志的事件处理器和复制的事件处理器,当请求最大可读的序号时,它返回两个处理器中较小的序号。
当每个事件处理器都使用SequenceBarrier 来确定哪些事件可以安全的从RingBuffer中读出,那么就从中读出这些事件。

图10
有很多事件处理器都可以从RingBuffer中读取序号,包括日志事件处理器,复制事件处理器等,但是只有一个处理器可以增加序号。这保证了共享数据没有竞争。
如果有多个发布者?
Disruptor也支持多个发布者向RingBuffer写入。当然,因为这样的话必然会发生两个不同的事件处理器写入同一格的情况,这样就会产生竞争。Disruptor提供ClaimStrategy的处理方式应对有多个发布者的情况。




/**
* <pre>
* 场景描述:生产者p1生产出来的数据需要经过消费者ep1和ep2的处理,然后传递给消费者ep3
*
* +-----+
* +----->| EP1 |------+
* | +-----+ |
* | v
* +----+ +-----+
* | P1 | | EP3 |
* +----+ +-----+
* | ^
* | +-----+ |
* +----->| EP2 |------+
* +-----+
*
*
* 基于队列的解决方案
* ============
* take put
* put +====+ +-----+ +====+ take
* +----->| Q1 |<---| EP1 |--->| Q3 |<------+
* | +====+ +-----+ +====+ |
* | |
* +----+ +====+ +-----+ +====+ +-----+
* | P1 |--->| Q2 |<---| EP2 |--->| Q4 |<---| EP3 |
* +----+ +====+ +-----+ +====+ +-----+
*
* 使用Disruptor的解决方案:
* 以一个RingBuffer为中心,生产者p1生产事件写到ringbuffer中,消费者ep1和ep2仅需要根据队尾位置来进行判断是否有可消费事件即可,消费者ep3则需要根据消费者ep1和ep2的位置来判断是否有可消费事件。生产者需要跟踪ep3的位置,防止覆盖未消费事件。
* ==========
* track to prevent wrap
* +-------------------------------+
* | |
* | v
* +----+ +====+ +=====+ +-----+
* | P1 |--->| RB |<--------------| SB2 |<---| EP3 |
* +----+ +====+ +=====+ +-----+
* claim ^ get | waitFor
* | |
* +=====+ +-----+ |
* | SB1 |<---| EP1 |<-----+
* +=====+ +-----+ |
* ^ |
* | +-----+ |
* +-------| EP2 |<-----+
* waitFor +-----+
*/
不管怎么样,现在大家都渐渐都这么一个意识了:锁是性能杀手。所以这些无锁的数据结构和算法,可以尝试借鉴来使用在合适的场景中。
一个比Disruptor吞吐量等性能指标更好的框架,使用Railway算法,将线程之间的消费发送参考现实生活中火车在站点之间搬运货物。
目标起始于一个简单的想法:创建一个开发人员友好的,简单的,轻量级线程间的通信框架,无需使用任何锁,同步器,信号量,等待,通知以及没有队列,消息,事件或任何其它并发特定的语法或工具。
只是一个Java接口接受到POJO以后在其背后实现这个通信,这个主意很类似Akka的Actors,但是它也许是有点矫枉过正,特别是对于单个多核计算机上线程间的通信优化必须是轻量的。
Akka的伟大之处是跨进程通信,特别是Actor是能够跨越不同JVM节点实现分布式通信。
无论如何,你可能觉得使用Akka在一个小型项目上有些过度,因为你只需要线程之间的通信,但是你还是想使用类似Actor这种做法模式。
该文章作者使用了动态代理 堵塞队列和一个缓存的线程池创建了这个解决方案,如图:
SPSC队列是一个Single Producer/Single Consumer 队列(单生产者/单消费者),而MPSC是一个Multi Producer/Single Consumer队列。
Dispatcher线程从Actor线程接受到消息,然后发送到相应的SPSC中。
Actor线程从接受的消息中使用数据,调用相应的actor类的方法,Actor实例都是发送消息给MPSC队列,然后再从Actor线程那里得到消息。
下面是ping-pong案例:
public interface PlayerA ( void pong(long ball); //send and forget method call } public interface PlayerB { void ping(PlayerA playerA, long ball); //send and forget method call } public class PlayerAImpl implements PlayerA { @Override @ublic void pong(long ball) { } } public class PlayerBImpl implements PlayerB { @Override public void ping(PlayerA playerA, long ball) { playerA.pong(ball); } } public class PingPongExample { public void testPingPong() { // this manager hides the complexity of inter-thread communications // and it takes control over actor proxies, actor implementations and threads ActorManager manager = new ActorManager(); // registers actor implementations inside the manager manager.registerImpl(PlayerAImpl.class); manager.registerImpl(PlayerBImpl.class); //Create actor proxies. Proxies convert method calls into internal messages //which would be sent between threads to a specific actor instance. PlayerA playerA = manager.createActor(PlayerA.class); PlayerB playerB = manager.createActor(PlayerB.class); for(int i = 0; i < 1000000; i++) { playerB.ping(playerA, i); } } |
这两个play能够每秒打500,000个乒乓。但是如果和单个线程执行速度相比,还是很差的,同样代码在单个线程可以到达每秒两百万个。
作者开始研究缓慢的原因,在一些校验和测试以后,他认为是Actors之间发送消息影响了整体性能:
作者找到一个SPSC单生产者和单消费者的无锁队列,http://www.infoq.com/presentations/Lock-Free-Algorithms
无锁队列提供比锁队列更好的性能。锁队列中在当一个线程获得锁,其他线程将被阻塞,直到该锁被释放的。在无锁算法的情况下,生产者线程可以产生消息,但不阻止其他生产者线程,以及其他消费者,而从队列中读取的消费者不会被阻塞。
这个无锁队列据测试结果是超过每秒100M ops,是JDK的并发队列实现的10倍。
但是作者使用这个无锁队列提到SPSC 以后,并没有产生明显性能提升,他立即意识到这个框架的性能瓶颈不是在SPSC,而是在多个生产者/单个消费者(MPSC)那里。
多个生产者如果使用SPSC会覆盖彼此的值,因为SPSC并没有一个对生产者的控制机制,即使最快的SPSC也不适合。
对于MPSC作者找到了LMAX的disruptor,一个通过Ringbuffer实现的高性能线程间通信库包。
使用Disruptor很容易实现非常低延迟,高吞吐量的线程间消息通信。它还提供了用例对生产者和消费者的不同组合。多个线程可以从环形缓冲区中读取而不会阻塞对方:
多生产者和多消费者:
三个生产者/一个消费者测试结果显示,Disruptor都是两倍于LinkedBlockingQueue 。
但是使用Disruptor后的这个框架性能还是没有达到预期,作者从上下班的地铁中得到灵感,在某个站点同一车厢出来的人是生产者,进去的是消费者。
建立一个Railway类,使用AtomicLong来跟踪地铁在站与站之间的传递,下面是一个single-train railway:
public class RailWay {
private final Train train = new Train();
//站台号码stationNo 跟踪火车,定义哪个站点接受火车
private final AtomicInteger stationIndex = new AtomicInteger();
//多线程访问这个方法,也就是在特定站点等待火车
public Train waitTrainOnStation(final int stationNo) {
while (stationIndex.get() % stationCount != stationNo) {
Thread.yield(); // this is necessary to keep a high throughput of message passing. //But it eats CPU cycles while waiting for a train
}
// the busy loop returns only when the station number will match // stationIndex.get() % stationCount condition
return train;
}
//这个方法通过增加火车站台号将火车移到下一个站点。 public void sendTrain() {
stationIndex.getAndIncrement();
}
}
|
参考Disruptor,创建线程间传递long值:
public class Train {
//
public static int CAPACITY = 2*1024;
private final long[] goodsArray; // array to transfer freight goods
private int index;
public Train() {
goodsArray = new long[CAPACITY];
}
public int goodsCount() { // returns the count of goods
return index;
}
public void addGoods(long i) { // adds item to the train
goodsArray[index++] = i;
}
public long getGoods(int i) { //removes the item from the train
index--;
return goodsArray[i];
}
}
|
如下图两个线程传递long:
使用一列火车实现单个生产者单个消费者:
public void testRailWay() {
final Railway railway = new Railway();
final long n = 20000000000l;
//starting a consumer thread
new Thread() {
long lastValue = 0;
@Override
public void run() {
while (lastValue < n) {
Train train = railway.waitTrainOnStation(1); //waits for the train at the station #1
int count = train.goodsCount();
for (int i = 0; i < count; i++) {
lastValue = train.getGoods(i); // unload goods
}
railway.sendTrain(); //sends the current train to the first station.
}
}
}.start();
final long start = System.nanoTime();
long i = 0;
while (i < n) {
Train train = railway.waitTrainOnStation(0); // waits for the train on the station #0
int capacity = train.getCapacity();
for (int j = 0; j < capacity; j++) {
train.addGoods((int)i++); // adds goods to the train
}
railway.sendTrain();
if (i % 100000000 == 0) { //measures the performance per each 100M items
final long duration = System.nanoTime() - start;|
final long ops = (i * 1000L * 1000L * 1000L) / duration;
System.out.format("ops/sec = %,d\n", ops);
System.out.format("trains/sec = %,d\n", ops / Train.CAPACITY);
System.out.format("latency nanos = %.3f%n\n",
duration / (float)(i) * (float) Train.CAPACITY);
}
}
}
|
通过测试,它达到 767,028,751 ops/sec ,是Nitsan’s blog.(第一个采用)的SPSC队列的几倍。
下面假设如果能有两列火车,每个站点有自己的火车,一个火车在第一个站点加载货物,第二列火车在第二个站点加载货物:
经过测试吞吐量是单列火车的1.4被,延迟从192.6纳秒降低到133.5纳秒。
但是线程间传输消息延迟是因为火车容量2048导致2178.4纳秒,通过增加火车降低这个延迟,如下图:
当在两个线程之间使用32,768 列火车传递一个long值,其延迟降低到13.9纳秒。到此吞吐量和延迟达到了一个平衡。
这只是SPSC的实现,纳秒多个生产者如何实现呢?答案是加入更多站点。
每个线程等待下一列火车,然后加载卸装消息,再把火车发到下一个站,而生产者线程放入消息到火车而消费者是从其中获得,火车总是从一个站到另外一个站循环不断移动。
测试了SPMC单个生产者和多个消费者,使用8个站点,一个属于生产者,剩余7个是消费者。
火车数量是256 火车容量是32时,测试结果是:吞吐量和延迟:
ops/sec = 116,604,397
latency nanos = 274.4
而火车数量是32而火车容量是256时:
ops/sec = 432,055,469
latency nanos = 592.5
后者相对是一个好的结果,延迟虽然提高,但是吞吐量提高的倍数要高得多。
本框架目标是多生产者和单消费者:
作者使用了3个生产者和一个消费者,测试结果:
ops/sec = 162,597,109
trains/sec = 54,199,036
latency ns = 18.5
生产者和消费者之间速度达到160M ops/sec
而disruptor则是:
Run 0, Disruptor=11,467,889 ops/sec
Run 1, Disruptor=11,280,315 ops/sec
Run 2, Disruptor=11,286,681 ops/sec
Run 3, Disruptor=11,254,924 ops/sec
使用Disruptor最好的结果是128M ops/sec,相差于作者的Railway框架,当然JDK的LinkedBlockingQueue 最后成绩是4M ops/sec
Railway算法能够显著增加吞吐量,通过调节火车的容量和数量容易在吞吐量和延迟之间取得平衡。
下图是Railway算法在混合生产者消费者中使用:
该项目源码下载github
测试使用源码
我个人观点,该文虽然以火车与火车站来比喻,实际是Disruptor的多个Ringbuffer组合,多列火车实际是多个Ringbuffer。
Disruptor的作者使用Disruptor实现多生产者和消费者案例如下:
点击看英文
他说:如果你知道你有生产商的数目在初始化时,你可以建立一个结构,显著减少争用。Disruptor中现有MultiProducerSequencer没有这个约束。
相比Disruptor以前使用MultiProducerSequencer为多个生产者只用一个Disruptor,现在可以使用SingleProducerSequencer 为每个生产者创建一个disruptor,下面就是在消费者里面的处理,增加了一个 MultiBufferBatchEventProcesor
三个生产者一个消费者的代码: ThreeToThreeSequencedThroughputTes
测试结果:
Run 0, Disruptor=390,738,060 ops/sec
Run 1, Disruptor=387,931,034 ops/sec
Run 2, Disruptor=397,058,823 ops/sec
Run 3, Disruptor=394,160,583 ops/sec
Run 4, Disruptor=396,767,083 ops/sec
Run 5, Disruptor=394,736,842 ops/sec
Run 6, Disruptor=396,767,083 ops/sec
而Railway测试结果:
ops/sec = 243,141,801
ops/sec = 302,695,445
ops/sec = 283,096,862
ops/sec = 273,670,298
ops/sec = 268,340,387
ops/sec = 264,802,500
ops/sec = 262,258,028
disruptor比railway吞吐量提高了。
这个新功能将发布在下一个disruptor版本中。这个用例还是说明保持 single writer的原则,多个线程只写自己的ringbuffer,改造下消费者线程就能达到disruptor单生产者的性能了。
LMAX架构
LMAX是一种新型零售金融交易平台,它能够以很低的延迟 (latency)产生大量交易(吞吐量). 这个系统是建立在JVM平台上,核心是一个业务逻辑处理器,它能够在一个线程里每秒处理6百万订单. 业务逻辑处理器完全是运行在内存中(in-memory),使用事件源驱动方式(event sourcing). 业务逻辑处理器的核心是Disruptors,这是一个并发组件,能够在无锁的情况下实现网络的Queue并发操作。他们的研究表明,现在的所谓高性能研究方向似乎和现代CPU设计是相左的。(见另外一篇文章:JVM伪共享)
过去几年我们不断提供这样声音:免费午餐已经结束。我们不再能期望在单个CPU上获得更快的性能,因此我们需要写使用多核处理的并发软件,不幸的是, 编写并发软件是很难的,锁和信号量是很难理解的和难以测试,这意味着我们要花更多时间在计算机上,而不是我们的领域问题,各种并发模型,如Actors 和软事务STM(Software Transactional Memory), 目的是更加容易使用,但是按下葫芦飘起瓢,还是带来了bugs和复杂性.
我 很惊讶听到去年3月QCon上一个演讲, LMAX是一种新的零售的金融交易平台。它的业务创新 - 允许任何人在一系列的金融衍生产品交易。这就需要非常低的延迟,非常快速的处理,因为市场变化很快,这个零售平台因为有很多人同时操作自然具备了复杂性, 用户越多,交易量越大,不断快速增长。
鉴于多核心思想的转变,这种苛刻的性能自然会提出一个明确的并行编程模型 ,但是他们却提出用一个线程处理6百万订单,而且是每秒,在通用的硬件上。
通过低延迟处理大量交易,取得低延迟和高吞吐量,而且没有并发代码的复杂性,他们是怎么做到呢?现在LMAX已经产品化一段时间了,现在应该可以揭开其神秘而迷人的面纱了。
结构如图: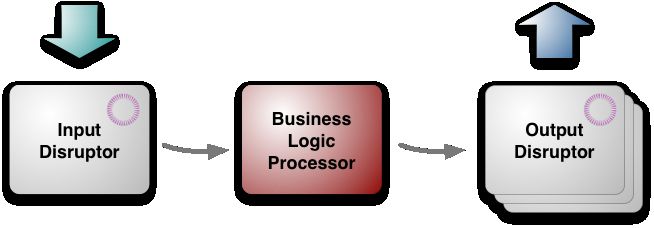
从最高层次看,架构有三个部分:
业务逻辑处理器business logic processor[5]
输入input disruptor
输出output disruptors
业务逻辑处理器处理所有的应用程序的业务逻辑,这是一个单线程的Java程序,纯粹的方法调用,并返回输出。不需要任何平台框架,运行在JVM里,这就保证其很容易运行测试环境。
业务逻辑处理器
全部驻留在内存中
业 务逻辑处理器有次序地取出消息,然后运行其中的业务逻辑,然后产生输出事件,整个操作都是在内存中,没有数据库或其他持久存储。将所有数据驻留在内存中有 两个重要好处:首先是快,没有IO,也没有事务,其次是简化编程,没有对象/关系数据库的映射,所有代码都是使用Java对象模型(广告:开源框架 JdonFramework和Jivejdon也是全部基于内存和事件源,内存领域对象+事件驱动,看来这条路的方向是对的)。
使用基于内存的模型有一个重要问题:万一崩溃怎么办?电源掉电也是可能发生的,“事件”(Event Sourcing )概念是问题解决的核心,业务逻辑处理器的状态是由输入事件驱动的,只要这些输入事件被持久化保存起来,你就总是能够在崩溃情况下,根据事件重演重新获得当前状态。(NOSQL存储的基于事件的事务实现)
要很好理解这点可以通过版本控制系统来理解,版本控制系统提交的序列,在任何时候,你可以建立由申请者提交一个工作拷贝,版本控制系统是一个复杂的商业逻辑处理器,而这里的业务逻辑处理只是一个简单的序列。
因 此,从理论上讲,你总是可以通过后处理的所有事件的商业逻辑处理器重建的状态,但是实践中重建所有事件是耗时的,需要切分,LMAX提供业务逻辑处理的快 照,从快照还原,每天晚上系统不繁忙时构建快照,重新启动商业逻辑处理器的速度很快,一个完整的重新启动 - 包括重新启动JVM加载最近的快照,和重放一天事件 - 不到一分钟。
快照虽然使启动一个新的业务逻辑处理器的速度,但速度还不够快,业 务逻辑处理器在下午2时就非常繁忙甚至崩溃,LMAX就保持多个业务逻辑处理器同时运行,每个输入事件由多个处理器处理,只有一个处理器输出有效,其他忽 略,如果一个处理器失败,切换到另外一个,这种故障转移失败恢复是事件源驱动(Event Sourcing)的另外一个好处。
通过事件驱动(event sourcing)他们也可以在处理器之间以微秒速度切换,每晚创建快照,每晚重启业务逻辑处理器, 这种复制方式能够保证他们没有当机时间,实现24/7.
事件方式是有价值的因为它允许处理器可以完全在内存中运行,但它有另一种用于诊断相当大的优势:如果出现一些意想不到的行为,事件副本们能够让他们在开发环境重放生产环境的事件,这就容易使他们能够研究和发现出在生产环境到底发生了什么事。
这 种诊断能力延伸到业务诊断。有一些企业的任务,如在风险管理,需要大量的计算,但是不处理订单。一个例子是根据其目前的交易头寸的风险状况排名前20位客 户名单,他们就可以切分到复制好的领域模型中进行计算,而不是在生产环境中正在运行的领域模型,不同性质的领域模型保存在不同机器的内存中,彼此不影响。
性能优化
正如我解释,业务逻辑处理器的性能关键是按顺序地做事(其实并不愚蠢 并行做就聪明吗?),这可以让普通开发者写的代码处理10K TPS. 如果能精简代码能够带来100K TPS提升. 这需要良好的代码和小方法,当然,JVM Hotspot的缓存微调,让其更加优化也是必须的。
以下省去两段.......调试方面。
编程模型
以 一个简单的非LMAX的例子来说明。想象一下,你正在为糖豆使用信用卡下订单。一个简单的零售系统将获取您的订单信息,使用信用卡验证服务,以检查您的信 用卡号码,然后确认您的订单 - 所有这些都在一个单一过程中操作。当进行信用卡有效性检查时,服务器这边的线程会阻塞等待,当然这个对于用户来说停顿不会太长。
在MAX架构中,你将此单一操作过程分为两个,第一部分将获取订单信息,然后输出事件(请求信用卡检查有效性的请求事件)给信用卡公司. 业务逻辑处理器将继续处理其他客户的订单,直至它在输入事件中发现了信用卡已经检查有效的事件,然后获取该事件来确认该订单有效。
这种异步事件驱动方式确实不寻常,虽然使用异步提高应用程序的响应是一个熟悉的技术。它还可以帮助业务流程更弹性,因为你必须要更明确的思考与远程应用程序打交道的不同之处。
这个编程模型第二个特点在于错误处理。传统模式下会话和数据库事务提供了一个有用的错误处理能力。如果有什么出错,很容易抛出任何东西,这个会话能够被丢弃。如果一个错误发生在数据库端,你可以回滚事务。
LMAX 的内存模式(in-memory structures)在于持久化输入事件,如果有错误发生也不会从内存中离开造成不一致的状态。但是因为没有回滚机制,LMAX投入了更多精力,确保输 入事件在实施任何内存状态影响前有效地持久化,他们发现这个关键是测试,在进入生产环境之前尽可能发现各种问题,确保持久化有效。
尽管业务逻辑是在单个线程中实现的,但是在我们调用一个业务对 象方法之前,有很多任务需要完成. 原始输入来自于消息形式,这个消息需要恢复成业务逻辑处理器能够处理的形式。事件源Event Sourcing依赖于让所有输入事件持久化,这样每个输入消息需要能够存储到持久化介质上,最后整个架构还有赖于业务逻辑处理器的集群. 同样在输出一边,输出事件也需要进行转换以便能够在网络上传输。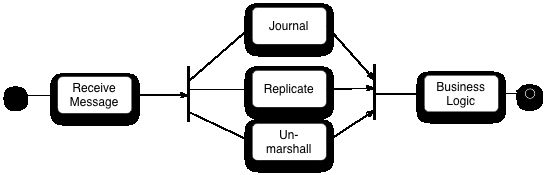
如图复制和日志是比较慢的。所有业务逻辑处理器避免最任何IO处理,所有这些任务都应该相对独立,他们需要在业务逻辑处理器处理之前完成,它们可以以任何次序方式完成,这不同意业务逻辑处理器需要根据交易自然先后进行交易,这些都是需要的并发机制。
为了这个并发机制,他们开发了disruptor的开源组件。
Disruptor 可以看成一个事件监听或消息机制,在队列中一边生产者放入消息,另外一边消费者并行取出处理. 当你进入这个队列内部查看,发现其实是一个真正的单个数据结构:一个ring buffer. 每个生产者和消费者都有一个次序计算器,以显示当前缓冲工作方式.每个生产者消费者写入自己次序计数器,能够读取对方的计数器,生产者能够读取消费者的计 算器确保其在没有锁的情况下是可写的,类似地消费者也要通过计算器在另外一个消费者完成后确保它一次只处理一次消息。
输出disruptors也类似于此,但是只有两个有顺序的消费者,转换和输出。输出事件被组织进入几个topics, 这样消息能够被发送到只有感兴趣的topic中,每个topic有自己的disruptor.
disruptor不但适合一个生产者多个消费者,也适合多个生产者。
disruptor设计的好处是能够容易让消费者快速抓取,如果发生问题,比如在15号位置有一个转换问题,而接受者在31号,它能够从16-30号一次性批量抓取,这种数据批读取能力加快消费者处理,降低整体延迟性。
ring buffer是巨大的: 输入2千万号槽;4百万输出. 次序计算器是一个64bit long 整数型,平滑增长(banq注:大概这里发现了JVM的伪共享),象其他系统一样disruptors过一个晚上将被清除,主要是擦除内存,以便不会产生 代价昂贵的垃圾回收机制启动(我认为重启是一个好的习惯,以便你应付不时之需。)
日志工作是将事件存储到持久化介质上,以便出错是重放,但是他们没有使用数据库来实现,而是文件系统,他们将事件流写到磁盘上,在现代概念看来,磁盘对于随机访问是非常慢,但是对于流操作却很快,也就是说,磁盘是一种新式的磁带。
之 前我提到LMAX运行在集群多个系统拷贝能够支持失败回复,复制工作负责这些节点的同步,所有节点联系是IP广播, 这样客户端能够不需要知道主节点的IP地址. 只有主节点直接听取输入事件,然后运行一个复制工作者,复制工作者将把输入事件广播到其他次要节点. 如果主节点当机,心跳机制将会发现, 另外一个节点就成为主节点,开始处理输入事件,启动复制工作者,每个节点都有自己的输入disruptor这样它有自己的日志处理和格式转换。
即使有IP广播,复制还是需要的,因为IP消息是以不同顺序到达不同节点,主节点提供为其他处理提供一个确定顺序。
格 式转换unmarshaler是将事件从其消息格式转换到Java对象,这样才能在业务逻辑处理器中使用,不同于其他消费者,它需要修改ring buffer中的数据以便能够存入这个被转换好的Java对象,这里有一个规则:并发地每次只有一个消费者能够运行写入,这实际上也符合单一写入者原则。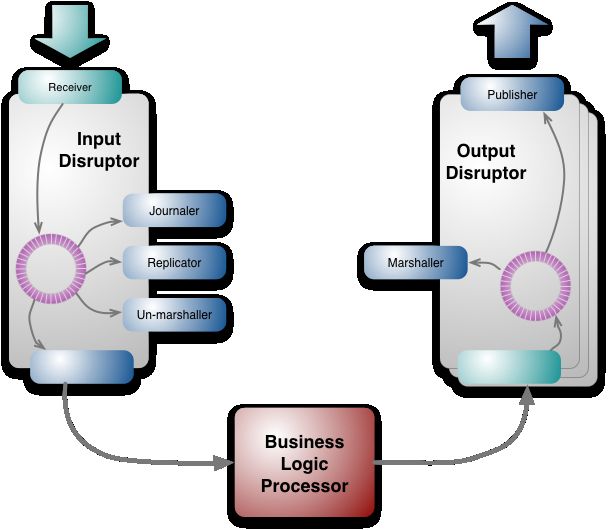
disruptor组件可以用在LMAX系统以外,通常金融财务公司对他们的系统都保持隐秘,但是LMAX能够开源,我很高兴,这将允许其他组织使用disruptor,它也将允许其他人对其进行并发性能测试。
(banq注:disruptor看来是一种特殊的消息组件类似JMS东西)。
队列和机制偏爱的缺乏
LMAX架构引起了人们的关注,因为它是一个非常不同的方式接近的高性能系统。到目前为止,我已经谈到了它是如何工作的,但没有太多深入探讨了为什么它是这样。这个故事本身是有趣的,意识到他们是有缺陷的。
许 多商业系统都有自己的核心架构师,通过事务性数据库实现多个会话事务(banq注:如EJB或Spring JTA等等),LMAX团队也熟悉这些知识,但是确信这些不合适他们的系统。这个经验是建立在LMAX母公司Betfair上 - 这是一家体育博彩公司,它处理很多人的体育投赌事件,这是一个相当大的并发访问,传统数据库机制几乎无法应付,这些让他们相信必须寻找另外一个途径来突破,他们现在接近目标了。
他们最初的想法为获得高性能是使用现在流行的并发。这意味着允许多线程并行处理多个订单。然而,在这种情况下是很难实现的,因为这些线程必须互相沟通。处理订单变化的市场条件等都需要相互沟通。
早期他们探索了Actor模型和近亲SEDA. Actor模型依赖于独立,活跃的对象有其自己的线程,彼此之间是通过queue同学,很多人认为这种并发模型比基于原始锁的方式易于处理。
这 团队就建立了一个actor模型原型,进行性能测试,他们发现的是处理器会花费更多时间在管理队列,而不是去做真正应用逻辑,队列访问成了真正瓶颈 (banq注:Scala的Actor模型很有名,不知这是否算Scala致命问题,怪不得很少人谈Scala的Actor模型了).
当 追求性能达到这种程度,现代硬件构造原理成为很重要的必须了解的知识了,马丁汤普森喜欢用的一句话是“机制偏爱”,这词来自赛车驾驶,它反映的是赛车手对 汽车有一种与生俱来的感觉,使他们能够感受到如何发挥它到最好状态。许多程序员包括我承认我也陷入这样一个阵营:不会认为编程如何与硬件等底层机制交互是 值得研究的。
现代的CPU延迟是影响性能的主导因素之一,在CPU如何与内存交互,CPU具有多层次的缓存(一级二级),每级速度都明显加快。因此,如果要提高速度,将您的代码和数据加载到这些缓存中。
在某个层次, actor模型能够帮助你,你能认为actor可以作为集群节点,是缓存的自然单元。但是Actors需要相互联系, 这是通过队列的- 而LMAX团队发现队列会干扰缓存(banq注:JVM伪分享的问题)。
为什么队列干扰了缓存呢?解释是这样的: 为了将数据放入队列,你需要写入队列,类似地,为了从队列取出数据,你需要移除队列也是一种写,客户端也许不只一次写入同样数据结构,处理写通常需要锁,但是如果锁使用了,会引起切换到底层系统的场景, 当这个发生后,处理器会丢失它的缓存中的数据。
他们得出的结论能够获得最好的缓存性能, 你需要设计一个CPU核写任何内存,多个读是好的,处理器会非常快,而队列失败在one-writer原则。
(JVM伪共享)
这样的分析导致LMAX团队得出一系列结论,导致他们设计出disruptor, 能够遵循single-writer约束. 其次它导向留澳单个线程处理业务逻辑的新的目标, 问题是:一个线程如果从并发管理结构中脱离出来(没有锁机制),它到底能跑多快?
单个线程的本质是:确保你每个CPU核运行一个线程,缓存配合,尽可能的高速缓存访问甚于主内存。这就意味着代码和数据需要尽可能的一致,. 保持小的代码对象和数据在一起,以便允许他们能够调入到一个高速缓存单位中或者轮换,简化高速缓存管理就是提高性能。
LMAX架构的路径的一个重要组成部分是使用了性能测试。基于 actor模型的放弃也是来自于测试原型的性能。同时也为改善的各个组成部分的性能步骤,启用了性能测试。机械同情是非常宝贵的的 - 它有助于形成假设什么可以改进,并指导你前进 -最终测试提供了有说服力的证据。
两段关于性能测试重要性,忽略....
你应当使用者架构吗
这个架构是适合非常小小众,必须有很低的延迟获得复杂大量的交易,大多数应用并不需要6百万TPS。
但是我对这个架构着迷的原因是它的设计,它移除了很多其他大多数编程系统的复杂性,传统围绕事务性的关系数据库会话并发模 型是不是免费的麻烦?(banq注:因为都掌握都知道也就是免费的) 通常与数据库打交道都有不寻常的付出和努力,对象/关系数据库映射ORM工具Object/relational mapping tools能够帮助减轻不少这种痛苦,但是它不能解决全部问题,大多数企业性能微调还是要纠结于SQL.
现在你能得到服务器更多的主内 存,比我们过去这些老家伙得到的磁盘还要多,越来越多应用能够将他们的工作全部置于内存中,这样消除了复杂性和性能低问题. 事件源驱动Event Sourcing提供了一种内存in-memory系统的解决方案, 在单个线程运行业务解决了并发. LMAX 经验建议只要你需要少于几百万TPS,你就有足够的性能提升余地。
这里也是相似于CQRS. 一种事件驱动, in-memory风格自然的命令系统(尽管LMAX当前没有使用CQRS.)
那么表示你是不是不应该走上这条道路呢?始终存在这样鲜为人知的棘手的技术问题,这个行业需要更多的时间去探索它的边界(注:老子思想的缴啊)。基本出发点是鼓励有自己特点的架构。
一个重要特点是处理一个交易总是潜在地影响其后面的处理方式,因为交易总是相互独立的, 因为很少相互协调,那么使用分离单独处理器分别处理并发运行也许更加有吸引力。
LMAX指出了“事件”概念是如何改变世界(banq注:hold住事件,而不是hold住数据,你就上了一个新层次,摆脱低级趣味的数据库癖好)。 许多网站使用原有的信息存储系统,然后渲染各种能够吸引眼球的效果. 他们的架构挑战就是如何正确使用缓存。
LMAX另外一个特点是这是一个后台系统,有理由考虑如何在一个交互模型中应用它,比如日益增长的Web应用,当异步通讯在WEB应用越来越多时,这将改变我们的编程模型。
这个改变会影响很多团队,大多数人倾向于认为同步编程,不习惯于异步处理。异步通讯是必不可少的响应工具,在javascript世界已经广泛使用,如 AJAX 和 node.js, 这些鼓励人们研究这些风格. LMAX团队发现虽然要花费一定时间来适应异步编程模型,但是一旦习惯就成为自然,特别是错误处理上容易得多。
LMAX团队当然感觉到花力气协调事务性关系数据库的日子已经屈指可数(banq老泪纵横啊,05年喊出了数据库时代的终结,08年我就喊出数据库已死,被国内很多大牛讥笑为疯子) 。你可以使用一种更加容易方式编写程序而且比传统集中式中央数据库运行得更快,为什么视而不见呢?
从我的观点看,我发现了一个令人激动的故事,我的大多数目标集中在软件的复杂领域模型解决上,作为一个架构师很喜欢这样的分离关注:让人们关注领域驱动设计DDD Domain-Driven Design,同时很好分离了平台复杂性,领域对象和数据库的紧耦合总是如一根针刺激我,现在好像找到出路了。
全文完。
banq最后注,我来总结老马文章的主要观点:
1.肯定了In-Memory内存缓存模式 + 异步事件 架构,LMAX实践也验证了这个架构。这个架构降低复杂性。
2.LMAX的核心是新型并发框架Disruptor,其核心是根据现代CPU硬件缓存特点发明不同于通用LinkedList或Queue的新型数据结构RingBuffer。
3.号称并发未来的Actor模型被LMAX团队验证是有瓶颈的。
4.提出新的并发模型,每个CPU一个线程,多个CPU多个线程并发模式,摒弃了锁模式。
5.ORM等Hibernate没有完全解决OO的目标,关系数据库的事务也不是最后救命的稻草。LMAX用自己的事件记录的方式实现事务,这也不同于所谓内存事务STM。见另外一篇:NOSQL存储的基于事件的事务实现。
6.09年推出jdonFramework 6.1版本就是事件驱动(Event Sourcing)+异步编程模型+In-memory架构,老马实际肯定了Jdon一直坚持的前沿架构观点。(当然jdonframework和LMAX还有些差别,只有领域模型异步的输出事件,没有输入事件,下一步可以引入Disruptors)。
7.老马认为架构师要分离关注,一是通过DDD降低业务的复杂性;二是通过技术探索创新,降低技术平台的复杂性,让程序员更多精力投入业务问题解决上。