1.sortByKey
2.cartesian
1.sortByKey
1.示例代码
1.1 RDD依赖关系
(3) ShuffledRDD[3] at sortByKey at SparkRDDSortByKey.scala:15 [] +-(3) ParallelCollectionRDD[0] at parallelize at SparkRDDSortByKey.scala:14 []
1.2 计算结果
part-00000:
(A,5)
(A,4)
(B,4)
(B,2)
part-00001:
(C,3)
(D,2)
part-00002:
(E,1)
(Z,3)
2.RDD依赖图

3.sortByKey源代码
/**
* Sort the RDD by key, so that each partition contains a sorted range of the elements. Calling
* `collect` or `save` on the resulting RDD will return or output an ordered list of records
* (in the `save` case, they will be written to multiple `part-X` files in the filesystem, in
* order of the keys).
*/
// TODO: this currently doesn't work on P other than Tuple2!
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.size)
: RDD[(K, V)] =
{
val part = new RangePartitioner(numPartitions, self, ascending)
new ShuffledRDD[K, V, V](self, part)
.setKeyOrdering(if (ascending) ordering else ordering.reverse)
}
3.1 sortByKey是OrderedRDDFunctions的方法,而不是PairRDDFunctions类的方法。它其中使用了RangePartitioner,因此对于同一个Reducer来说,它得到的结果是有序的,即part-00000中的数据是有序的,part-00001中的数据也是有序的,同时part-00001中的数据较part-00000要么为大(升序),要么为小(降序).
3.2 如果Reducer的个数大于1个,那么这些reducer的排序不是全局有序的?不是这么理解的,在一个节点上的Reducer任务,得到的结果是有序的,但是不同节点上的数据不是全量有序的。
3.3 sortByKey只支持K,V类型的sort,即按照Key进行排序。然后通过隐式转换转换到OrderedRDDFunctions类上。
2. cartesian
1. 示例代码
package spark.examples
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by yuzhitao on 2/6/2015.
*/
object SparkRDDCartesian {
def main(args : Array[String]) {
val conf = new SparkConf().setAppName("SparkRDDCartesian").setMaster("local");
val sc = new SparkContext(conf);
//第一个参数是集合,第二个参数是分区数
val rdd1 = sc.parallelize(List((1,2),(2,3), (3,4),(4,5),(5,6)), 3)
val rdd2 = sc.parallelize(List((3,6),(2,8)), 2);
val pairs = rdd1.cartesian(rdd2);
pairs.saveAsTextFile("file:///D:/cartesian" + System.currentTimeMillis());
println(pairs.toDebugString)
}
}
1.1 RDD依赖关系
(6) CartesianRDD[2] at cartesian at SparkRDDCartesian.scala:18 [] | ParallelCollectionRDD[0] at parallelize at SparkRDDCartesian.scala:14 [] | ParallelCollectionRDD[1] at parallelize at SparkRDDCartesian.scala:15 []
1.2 计算结果
part-00000: ((1,2),(3,6))
part-00001:((1,2),(2,8))
part-00002:((2,3),(3,6)) ((3,4),(3,6))
part-00003: ((2,3),(2,8)) ((3,4),(2,8))
part-00004: ((4,5),(3,6)) ((5,6),(3,6))
part-00005:((4,5),(2,8)) ((5,6),(2,8))
2. RDD依赖图
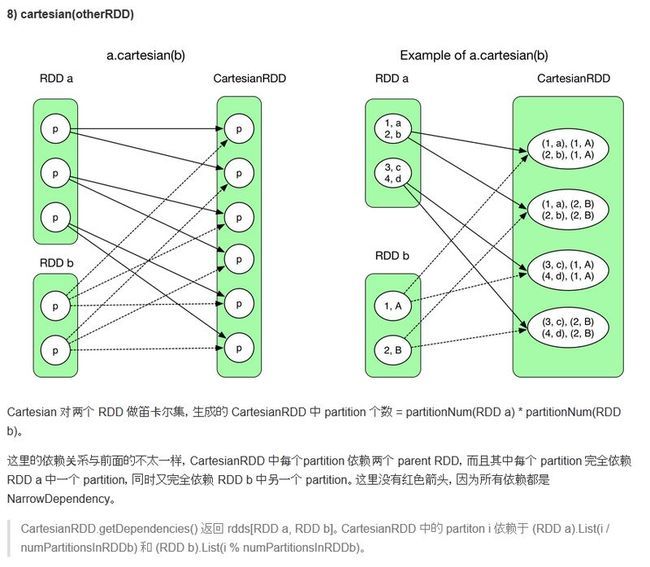
3. cartesian源代码
/** * Return the Cartesian product of this RDD and another one, that is, the RDD of all pairs of * elements (a, b) where a is in `this` and b is in `other`. */ def cartesian[U: ClassTag](other: RDD[U]): RDD[(T, U)] = new CartesianRDD(sc, this, other)
3.1 子RDD的每个partition完全依赖于父RDD的一个partion,又完全依赖于另一个父RDDb的partition,那么这个为什么称为窄依赖???对于窄依赖,NarrowDependency的文档如下。可见,不是说父RDD的partition只能被一个子RDD的partition使用才是窄依赖。一个父RDD的partition可以被多个子RDD依赖
/** * :: DeveloperApi :: * Base class for dependencies where each partition of the child RDD depends on a small number * of partitions of the parent RDD. Narrow dependencies allow for pipelined execution. */
3.2 CartesianRDD的源代码:
class CartesianRDD[T: ClassTag, U: ClassTag](
sc: SparkContext,
var rdd1 : RDD[T],
var rdd2 : RDD[U])
extends RDD[Pair[T, U]](sc, Nil)
with Serializable {
val numPartitionsInRdd2 = rdd2.partitions.size
override def getPartitions: Array[Partition] = {
// create the cross product split
val array = new Array[Partition](rdd1.partitions.size * rdd2.partitions.size)
for (s1 <- rdd1.partitions; s2 <- rdd2.partitions) {
val idx = s1.index * numPartitionsInRdd2 + s2.index
array(idx) = new CartesianPartition(idx, rdd1, rdd2, s1.index, s2.index)
}
array
}
override def getPreferredLocations(split: Partition): Seq[String] = {
val currSplit = split.asInstanceOf[CartesianPartition]
(rdd1.preferredLocations(currSplit.s1) ++ rdd2.preferredLocations(currSplit.s2)).distinct
}
override def compute(split: Partition, context: TaskContext) = {
val currSplit = split.asInstanceOf[CartesianPartition]
for (x <- rdd1.iterator(currSplit.s1, context);
y <- rdd2.iterator(currSplit.s2, context)) yield (x, y)
}
///都是窄依赖
override def getDependencies: Seq[Dependency[_]] = List(
new NarrowDependency(rdd1) {
def getParents(id: Int): Seq[Int] = List(id / numPartitionsInRdd2)
},
new NarrowDependency(rdd2) {
def getParents(id: Int): Seq[Int] = List(id % numPartitionsInRdd2)
}
)
override def clearDependencies() {
super.clearDependencies()
rdd1 = null
rdd2 = null
}
}
再论宽窄依赖:
依赖是针对分区来说的,所以洗牌就是对分区的数据进行重新整理,重新分配等,所以需要重组分区数据之类的操作,在理论上才是一种Shuffle
有shuffle就是宽,没shuffle就是窄
- 第一种 1:1 的情况被称为 OneToOneDependency。
- 第二种 N:1 的情况被称为 N:1 NarrowDependency。
- 第三种 N:N 的情况被称为 N:N NarrowDependency。不属于前两种情况的完全依赖都属于这个类别。
- 第四种被称为 ShuffleDependency。