开发Spark WordCount的步骤
- 下载并配置Scala2.11.4
- 下载Scala版本的Eclipse,简称Scala IDE
- 下载Spark安装包,使用其中的开发Spark程序需要依赖的jar包
- 下载Spark源代码,以使jar包关联源代码
- 配置IDE环境
- 编写并编译源代码
- 导出jar包
- 提交SparkWordCount jar包到Spark服务器上运行,并查看运行结果
1. 下载并配置Scala2.11.4
http://www.scala-lang.org/download/2.11.4.html
下载scala-2.11.4.zip。解压后,设置Scala的环境变量
SCALA_HOME=C:\Scala_2.11.4
PATH=C:\Scala_2.11.4\bin;%PATH%
配置完成后,在命令行终端,输入scala -version可以查看Scala的版本
2. 下载安装Scala IDE(Eclipse)
http://downloads.typesafe.com/scalaide-pack/4.0.0.vfinal-luna-211-20141216/scala-SDK-4.0.0-vfinal-2.11-win32.win32.x86_64.zip
解压,运行eclipse。这个版本的Eclipse需要64为的JRE,所以,如果JAVA_HOME和PATH指向的是一个32为的JDK,那么Eclipse将启动不起来,解决办法是
- 下载64位JDK
- 修改Eclipse解压目录中的eclipse.ini文件,修改两个地方
a. 在文件开头添加自定义的JDK目录
-vm
C:\jdk1.7.0_71_win64\bin
b. 将-Xmx2G改为-Xmx512m
3. 下载Spark安装包
http://d3kbcqa49mib13.cloudfront.net/spark-1.2.0-bin-hadoop2.4.tgz
4. 下载Spark源代码
http://d3kbcqa49mib13.cloudfront.net/spark-1.2.0.tgz
5. 配置Scala IDE环境
- 启动Eclipse后,新建一个Scala项目,此时可以看到,Scala IDE已经把2.11.4的Scala作为Library加到classpath上了
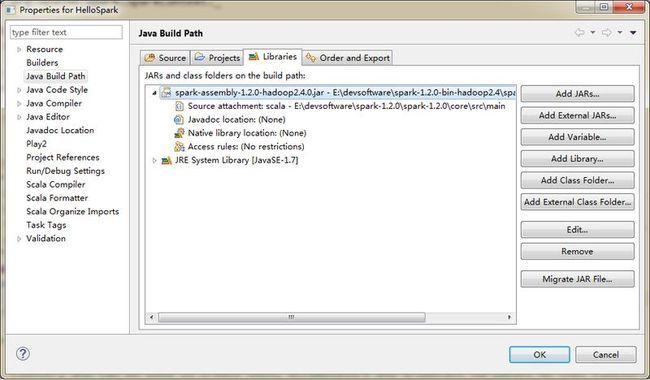
- 使用跟Java设置jar依赖的方式,将Spark的jar包spark-assembly-1.2.0-hadoop2.4.0.jar作为外部jar添加到classpath。同时为spark-assembly-1.2.0-hadoop2.4.0.jar关联源代码,目录是spark-1.2.0\core\src\main\scala
- 设置完成后,Error视图报错,说Eclipse依赖的Scala库有两份,一个是系统安装的Scala(C:\Scala_2.11.4,一个是spark-assembly-1.2.0-hadoop2.4.0.jar中,而spark-assembly-1.2.0-hadoop2.4.0.jar中的版本是2.10.4,因此两个版本不一致而导致冲突
- 因为我们的代码是在Spark中运行,而Spark使用的Scala版本是2.10.4,所以,开发环境中的Scala也应该是2.10.4,因此将2.11.4这个Scala库从Java Build Path删除掉
- 删除了之后,Eclipse继续报错,如下所示,也就是说,项目依赖的Scala版本不如IDE的Scala版本新,解决办法如下
- 右击前面建的Scala项目,在右键弹出菜单中,选择Scala,然后在级联菜单中,选择Set Scala Installation,在弹出的对话框中选择,Fixed Scala Installation:2.10.4(bundled)
- clean整个项目,Scala IDE的环境到此就配置完成了。
Description Resource Path Location Type
The version of scala library found in the build path of HelloSpark (2.10.4.) is prior to the one provided by scala IDE (2.11.4.). Setting a Scala Installation Choice to match. HelloSpark Unknown Scala Version Problem
6. 编写并编译源代码
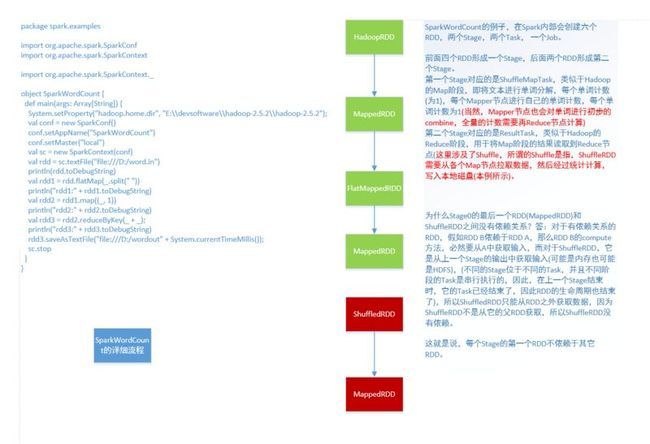
新建一个Scala object SparkWordCount,在main方法中添加处理的逻辑,这个类的处理逻辑是从HDFS读取一段文本,然后进行计数排序,回写回HDFS中,这个已经在Spark Shell多次运行过
package spark.examples
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
object SparkWordCount {
def main(args: Array[String]) {
///运行参数:HDFS中的文件,默认前缀是/user/hadoop/
if (args.length < 1) {
System.err.println("Usage: <file>")
System.exit(1)
}
//定义Spark运行时的配置信息
/*
Configuration for a Spark application. Used to set various Spark parameters as key-value pairs.
Most of the time, you would create a SparkConf object with `new SparkConf()`, which will load
values from any `spark.*` Java system properties set in your application as well. In this case,
parameters you set directly on the `SparkConf` object take priority over system properties.
*/
val conf = new SparkConf()
conf.setAppName("SparkWordCount")
//定义Spark的上下文
/*
Main entry point for Spark functionality. A SparkContext represents the connection to a Spark
cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster.
Only one SparkContext may be active per JVM. You must `stop()` the active SparkContext before
creating a new one. This limitation may eventually be removed; see SPARK-2243 for more details.
@param config a Spark Config object describing the application configuration. Any settings in this config overrides the default configs as well as system properties.
*/
val sc = new SparkContext(conf)
///从HDFS中获取文本(没有实际的进行读取),构造MappedRDD
val rdd = sc.textFile(args(0))
//此行如果报value reduceByKey is not a member of org.apache.spark.rdd.RDD[(String, Int)],则需要import org.apache.spark.SparkContext._
rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).map(x => (x._2, x._1)).sortByKey(false).map(x => (x._2, x._1)).saveAsTextFile("SortedWordCountRDDInSparkApplication")
sc.stop
}
}
7.导出jar包
像导出普通Java项目一样,将HelloSpark这个项目导出成jar包,跟Java项目导出jar不同的时候,虽然SparkWordCount中定义了main方法,但是在导出jar包时,在选择main方法作为MANEFEST.MF中的Main时,没有显示。
虽然上面只定义了一个类,实际上Scala编译得到了很多的类

8. 提交作业
1. 编写一个简单的脚本submitJob.sh,放到Spark的bin目录下;同时,将SparkWordCount.jar也放到bin目录下
#!/usr/bin/env bash
./spark-submit --name SparkWordCount --class spark.examples.SparkWordCount --master spark://hadoop.master:7077 --executor-memory 512M --total-executor-cores 1 SparkWordCount.jar README.md
注意,一开始运行失败,原因是512M,没有写M,导致Spark分配给Executor的内存数为0.
2. 使用sh submitJob.sh提交作业
注意的是,使用spark-submit提交作业时,需要关掉spark-shell交互式命令行终端,因为它们都要启动4040端口(SparkUI)